適用対象:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Microsoft SQL Server 2019 ビッグ データ クラスターは廃止されました。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日の時点で終了しました。 詳細については、Microsoft SQL Server プラットフォーム の発表ブログ投稿 と ビッグ データ オプションを参照してください。
このチュートリアルでは、SQL Server 2019 ビッグ データ クラスターで Azure Data Studio にノートブックを読み込んで実行する方法について説明します。 これにより、データ サイエンティストやデータ エンジニアは、クラスターに対して Python、R、または Scala コードを実行することができます。
Tip
必要に応じて、このチュートリアルのコマンド用のスクリプトをダウンロードして実行できます。 手順については、GitHub の Spark サンプルを参照してください。
Prerequisites
-
ビッグ データ ツール
- kubectl
- Azure Data Studio
- SQL Server 2019 の拡張機能
- ビッグ データ クラスターにサンプル データを読み込む
サンプルのノートブック ファイルをダウンロードする
次の手順を使用して、サンプルのノートブック ファイル spark-sql.ipynb を Azure Data Studio に読み込みます。
bash コマンド プロンプト (Linux) または Windows PowerShell を開きます。
サンプルのノートブック ファイルをダウンロードするディレクトリに移動します。
次の curl コマンドを実行し、GitHub からノートブック ファイルをダウンロードします。
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
ノートブックを開く
次の手順では、Azure Data Studio でノートブック ファイルを開く方法を示しています。
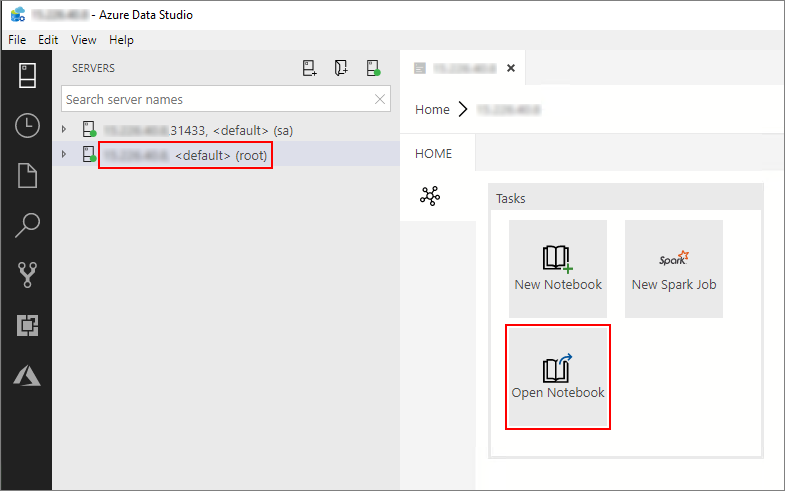
Azure Data Studio で、ビッグ データ クラスターのマスター インスタンスに接続します。 詳細については、ビッグ データ クラスターへの接続に関するページを参照してください。
[サーバー] ウィンドウで、HDFS/Spark ゲートウェイ接続をダブルクリックします。 その後、 [ノートブックを開く] を選択します。
[カーネル] とターゲット コンテキスト ( [アタッチ先] ) が設定されるまで待ちます。 [カーネル] を PySpark3 に設定し、 [アタッチ先] をビッグ データ クラスター エンドポイントの IP アドレスに設定します。
![[カーネル] と [アタッチ先] を設定する](media/notebook-tutorial-spark/set-kernel-and-attach-to.png?view=sql-server-ver15)
Important
Azure Data Studio では、すべての種類の Spark ノートブック (Scala Spark、PySpark、SparkR) で通常、最初のセルの実行時に、一部の重要な Spark セッションに関連する変数が定義されます。 これらの変数は、spark、sc、および sqlContext です。 バッチ送信用のノートブックからロジックを (たとえば、azdata bdc spark batch create を使って実行する Python ファイルに) コピーする場合は、必要に応じて変数を定義してください。
ノートブック セルを実行する
セルの左側にある [再生] ボタンを押して、各ノートブック セルを実行することができます。 セルの実行が完了した後、結果がノートブックに表示されます。

サンプル ノートブック内の各セルを続けて実行します。 SQL Server ビッグ データ クラスター でノートブックを使用する方法の詳細については、次のリソースを参照してください。
Next steps
ノートブックについてさらに学習します: