チュートリアル:Spark ジョブを使用して SQL Server のデータ プールにデータを取り込む
適用対象:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
このチュートリアルでは、Spark ジョブを使用して SQL Server 2019 ビッグ データ クラスター のデータ プールにデータを取り込む方法について説明します。
このチュートリアルでは、以下の内容を学習します。
- データ プールに外部テーブルを作成する
- Spark ジョブを作成して HDFS からデータを読み込む
- 外部テーブルの結果に対してクエリを実行する
ヒント
必要に応じて、このチュートリアルのコマンド用のスクリプトをダウンロードして実行できます。 手順については、GitHub のデータ プールのサンプルを参照してください。
前提条件
- ビッグ データ ツール
- kubectl
- Azure Data Studio
- SQL Server 2019 の拡張機能
- ビッグ データ クラスターにサンプル データを読み込む
データ プールに外部テーブルを作成する
次の手順では、web_clickstreams_spark_results という名前のデータ プールに外部テーブルを作成します。 このテーブルは、ビッグ データ クラスターにデータを取り込むための場所として使用できます。
Azure Data Studio で、ビッグ データ クラスターの SQL Server マスター インスタンスに接続します。 詳細については、「SQL Server マスター インスタンスに接続する」を参照してください。
[サーバー] ウィンドウで接続をダブルクリックして、SQL Server マスター インスタンスのサーバー ダッシュボードを表示します。 [新しいクエリ] を選択します。
MSSQL-Spark コネクタのアクセス許可を作成します。
USE Sales CREATE LOGIN sample_user WITH PASSWORD ='password123!#' CREATE USER sample_user FROM LOGIN sample_user -- To create external tables in data pools GRANT ALTER ANY EXTERNAL DATA SOURCE TO sample_user; -- To create external tables GRANT CREATE TABLE TO sample_user; GRANT ALTER ANY SCHEMA TO sample_user; -- To view database state for Sales GRANT VIEW DATABASE STATE ON DATABASE::Sales TO sample_user; ALTER ROLE [db_datareader] ADD MEMBER sample_user ALTER ROLE [db_datawriter] ADD MEMBER sample_userまだ存在しない場合は、データ プールへの外部データ ソースを作成します。
USE Sales GO IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlDataPool') CREATE EXTERNAL DATA SOURCE SqlDataPool WITH (LOCATION = 'sqldatapool://controller-svc/default');データ プールで、web_clickstreams_spark_results という名前の外部テーブルを作成します。
USE Sales GO IF NOT EXISTS(SELECT * FROM sys.external_tables WHERE name = 'web_clickstreams_spark_results') CREATE EXTERNAL TABLE [web_clickstreams_spark_results] ("wcs_click_date_sk" BIGINT , "wcs_click_time_sk" BIGINT , "wcs_sales_sk" BIGINT , "wcs_item_sk" BIGINT , "wcs_web_page_sk" BIGINT , "wcs_user_sk" BIGINT) WITH ( DATA_SOURCE = SqlDataPool, DISTRIBUTION = ROUND_ROBIN );データ プールのログインを作成し、ユーザーにアクセス許可を与えます。
EXECUTE( ' Use Sales; CREATE LOGIN sample_user WITH PASSWORD = ''password123!#'' ;') AT DATA_SOURCE SqlDataPool; EXECUTE('Use Sales; CREATE USER sample_user; ALTER ROLE [db_datareader] ADD MEMBER sample_user; ALTER ROLE [db_datawriter] ADD MEMBER sample_user;') AT DATA_SOURCE SqlDataPool;
データ プールの外部テーブルの作成は、ブロッキング操作です。 指定したテーブルがすべてのバックエンド データ プール ノードで作成されると、制御が戻ります。 作成操作中にエラーが発生した場合、エラー メッセージが呼び出し元に返されます。
Spark ストリーミング ジョブを開始する
次の手順では、ストレージ プール (HDFS) から Web クリックストリーム データを、データ プールに作成した外部テーブルに読み込む Spark ストリーミング ジョブを作成します。 このデータは「ビッグ データ クラスターにサンプル データを読み込む」で /clickstream_data に追加されました。
Azure Data Studio で、ビッグ データ クラスターのマスター インスタンスに接続します。 詳細については、ビッグ データ クラスターへの接続に関するページを参照してください。
新しいノートブックを作成し、カーネルとして Spark | Scala を選択します。
Spark インジェスト ジョブを実行する
- Spark-SQL コネクタ パラメーターを構成する
Note
ビッグ データ クラスターが Active Directory 統合を使用して展開されている場合は、以下の hostname の値を置き換えて、サービス名に追加された FQDN を含めます。 E.g. hostname=master-p-svc.<domainName>.
import org.apache.spark.sql.types._ import org.apache.spark.sql.{SparkSession, SaveMode, Row, DataFrame} // Change per your installation val user= "username" val password= "****" val database = "MyTestDatabase" val sourceDir = "/clickstream_data" val datapool_table = "web_clickstreams_spark_results" val datasource_name = "SqlDataPool" val schema = StructType(Seq( StructField("wcs_click_date_sk",LongType,true), StructField("wcs_click_time_sk",LongType,true), StructField("wcs_sales_sk",LongType,true), StructField("wcs_item_sk",LongType,true), StructField("wcs_web_page_sk",LongType,true), StructField("wcs_user_sk",LongType,true) )) val hostname = "master-p-svc" val port = 1433 val url = s"jdbc:sqlserver://${hostname}:${port};database=${database};user=${user};password=${password};"- Spark ジョブを定義して実行する
- 各ジョブは、readStream と writeStream という 2 部構成になっています。 以下では、上で定義したスキーマでデータ フレームを作成し、データ プールの外部テーブルに書き込みます。
import org.apache.spark.sql.{SparkSession, SaveMode, Row, DataFrame} val df = spark.readStream.format("csv").schema(schema).option("header", true).load(sourceDir) val query = df.writeStream.outputMode("append").foreachBatch{ (batchDF: DataFrame, batchId: Long) => batchDF.write .format("com.microsoft.sqlserver.jdbc.spark") .mode("append") .option("url", url) .option("dbtable", datapool_table) .option("user", user) .option("password", password) .option("dataPoolDataSource",datasource_name).save() }.start() query.awaitTermination(40000) query.stop()
データにクエリを実行する
次の手順は、HDFS からデータをデータ プールに読み込む Spark ストリーミング ジョブを示しています。
取り込んだデータについて問い合わせる前に、Yarn アプリ ID、Spark UI、ドライバー ログなど、Spark の実行状態を確認します。 この情報は、Spark アプリケーションの初回起動時にノートブックに表示されます。
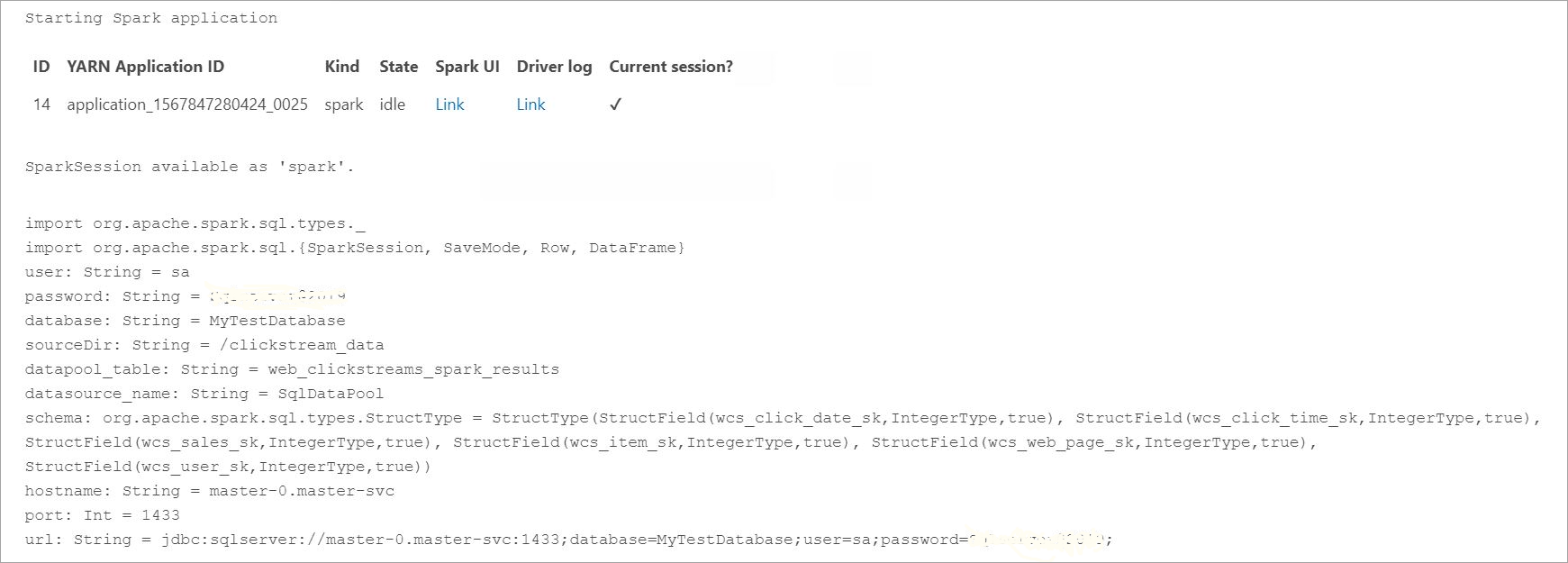
このチュートリアルで最初に開いた SQL Server マスター インスタンス クエリ ウィンドウに戻ります。
次のクエリを実行して、取り込まれたデータを検査します。
USE Sales GO SELECT count(*) FROM [web_clickstreams_spark_results]; SELECT TOP 10 * FROM [web_clickstreams_spark_results];データは Spark でも照会できます。 たとえば、下のコードでは、テーブルのレコード数が印刷されます。
def df_read(dbtable: String, url: String, dataPoolDataSource: String=""): DataFrame = { spark.read .format("com.microsoft.sqlserver.jdbc.spark") .option("url", url) .option("dbtable", dbtable) .option("user", user) .option("password", password) .option("dataPoolDataSource", dataPoolDataSource) .load() } val new_df = df_read(datapool_table, url, dataPoolDataSource=datasource_name) println("Number of rows is " + new_df.count)
クリーンアップ
このチュートリアルで作成されたデータベース オブジェクトを削除するには、次のコマンドを使用します。
DROP EXTERNAL TABLE [dbo].[web_clickstreams_spark_results];
次のステップ
Azure Data Studio でサンプル ノートブックを実行する方法について説明します。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示