Integration Services (SSIS) 用の Azure Feature Pack
適用対象:![]() SQL Server
SQL Server![]() Azure Data Factory の SSIS Integration Runtime
Azure Data Factory の SSIS Integration Runtime
SQL Server Integration Services (SSIS) Feature Pack for Azure は、このページにリストされている SSIS のコンポーネントを提供して、Azure サービスへの接続、Azure とオンプレミスのデータ ソース間でのデータ転送、および Azure に格納されたデータの処理を行うための拡張機能です。
 SSIS Feature Pack for Azure のダウンロード
SSIS Feature Pack for Azure のダウンロード
- SQL Server 2022 の場合 - Microsoft SQL Server 2022 Integration Services Feature Pack for Azure
- SQL Server 2019 の場合 - Microsoft SQL Server 2019 Integration Services Feature Pack for Azure
- SQL Server 2017 の場合 - Microsoft SQL Server 2017 Integration Services Feature Pack for Azure
- SQL Server 2016 の場合 - Microsoft SQL Server 2016 Integration Services Feature Pack for Azure
- SQL Server 2014 の場合 - Microsoft SQL Server 2014 Integration Services Feature Pack for Azure
- SQL Server 2012 の場合 - Microsoft SQL Server 2012 Integration Services Feature Pack for Azure
ダウンロード ページには、前提条件に関する情報も含まれます。 必ず SQL Server をインストールしてから Azure Feature Pack をサーバーにインストールします。そうしないと、サーバー上の SSIS カタログ データベース (SSISDB) にパッケージを展開するときに Feature Pack 内のコンポーネントを利用できない場合があります。
Feature Pack のコンポーネント
接続マネージャー
タスク
データ フロー コンポーネント
Azure BLOB、Azure Data Lake Store、および Data Lake Storage Gen2 のファイル列挙子。 「Foreach ループ コンテナー」を参照してください。
TLS 1.2 を使用する
Azure Feature Pack で使用される TLS のバージョンは、システム .NET Framework 設定に準拠しています。
TLS 1.2 を使用するには、次の 2 つのレジストリキーの下に SchUseStrongCrypto という名前の REG_DWORD 値をデータ 1 と共に追加します。
HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\.NETFramework\v4.0.30319HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\.NETFramework\v4.0.30319
Java への依存関係
Azure Data Lake Store/柔軟なファイル コネクタで ORC/Parquet ファイル形式を使用するには、Java が必要です。
Java ビルドのアーキテクチャ (32/64 ビット) は、SSIS ランタイムのそれと一致しなければ使用できません。
次の Java ビルドがテストされています。
Zulu の OpenJDK を設定する
- インストール zip パッケージをダウンロードし、抽出します。
- コマンド プロンプトから
sysdm.cplを実行します。 - [詳細設定] タブの [環境変数] を選択します。
- [システム変数] セクションで [新規] を選択します。
- [変数名] に「
JAVA_HOME」と入力します。 - [ディレクトリの参照] を選択し、解凍したフォルダーに移動し、
jreサブフォルダーを選択します。 [OK] を選択すると、変数の値が自動的に入力されます。 - [OK] を選択し、 [新しいシステム変数] ダイアログ ボックスを閉じます。
- [OK] を選択し、 [環境変数] ダイアログ ボックスを閉じます。
- [OK] を選択して [システム プロパティ] ダイアログ ボックスを閉じます。
ヒント
Parquet 形式を使用し、"Java の呼び出し中にエラーが発生しました。メッセージ: java.lang.OutOfMemoryError:Java heap space" というエラーが発生した場合、環境変数 _JAVA_OPTIONS を追加し、JVM の最小/最大ヒープ サイズを調整できます。
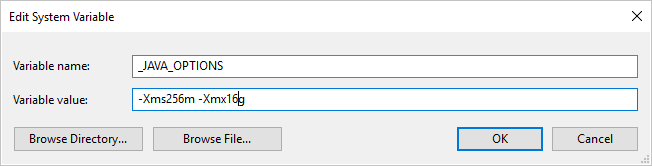
例: 変数 _JAVA_OPTIONS を設定して、値 -Xms256m -Xmx16g を指定します。 フラグ Xms では、Java 仮想マシン (JVM) の初期メモリ割り当てプールを指定します。Xmx では、最大メモリ割り当てプールを指定します。 これは、JVM 起動時のメモリ量が Xms、使用可能なメモリ量が最大で Xmx であることを意味します。 既定値は最小 64MB および最大 1G です。
Azure-SSIS Integration Runtime で Zulu の OpenJDK を設定する
これは、Azure-SSIS Integration Runtime のカスタム セットアップ インターフェイス経由で行う必要があります。
zulu8.33.0.1-jdk8.0.192-win_x64.zip が使用されているとします。
BLOB コンテナーは次のように構成できます。
main.cmd
install_openjdk.ps1
zulu8.33.0.1-jdk8.0.192-win_x64.zip
エントリ ポイントとして、main.cmd により PowerShell スクリプト install_openjdk.ps1 の実行がトリガーされます。それによって次に zulu8.33.0.1-jdk8.0.192-win_x64.zip が抽出され、それに応じて JAVA_HOME が設定されます。
main.cmd
powershell.exe -file install_openjdk.ps1
ヒント
Parquet 形式を使用し、"Java の呼び出し中にエラーが発生しました。メッセージ: java.lang.OutOfMemoryError:Java heap space" というエラーが発生した場合、 main.cmd でコマンドを追加し、JVM の最小/最大ヒープ サイズを調整できます。 例:
setx /M _JAVA_OPTIONS "-Xms256m -Xmx16g"
フラグ Xms では、Java 仮想マシン (JVM) の初期メモリ割り当てプールを指定します。Xmx では、最大メモリ割り当てプールを指定します。 これは、JVM 起動時のメモリ量が Xms、使用可能なメモリ量が最大で Xmx であることを意味します。 既定値は最小 64MB および最大 1G です。
install_openjdk.ps1
Expand-Archive zulu8.33.0.1-jdk8.0.192-win_x64.zip -DestinationPath C:\
[Environment]::SetEnvironmentVariable("JAVA_HOME", "C:\zulu8.33.0.1-jdk8.0.192-win_x64\jre", "Machine")
Oracle の Java SE Runtime Environment を設定する
- exe インストーラーをダウンロードし、実行します。
- インストーラーの指示に従い、設定を完了します。
シナリオ:ビッグ データの処理
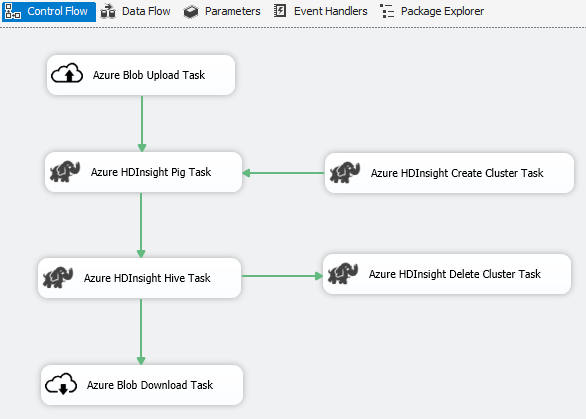
Azure コネクタを使用して、次のビッグ データの処理を完了します。
Azure Blob Upload Task を使用して、入力データを Azure Blob ストレージにアップロードします。
Azure HDInsight Create Cluster Task を使用して、Azure HDInsight のクラスターを作成します。 独自のクラスターを使用する場合は、この手順は省略できます。
Azure HDInsight Hive Task か Azure HDInsight Pig Task を使用して、Azure HDInsight クラスターで Pig または Hive ジョブを呼び出します。
手順 2 でオンデマンドの HDInsight クラスターを作成した場合は、使用後の HDInsight クラスターを Azure HDInsight Delete Cluster Task で削除します。
Azure HDInsight Blob Download Task を使用して、Azure Blob ストレージから Pig/Hive の出力データをダウンロードします。
シナリオ:クラウド内のデータ管理
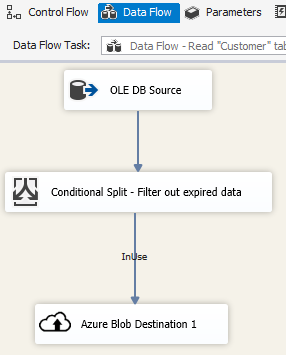
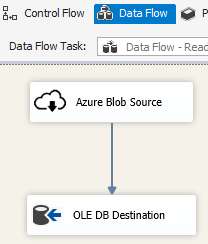
SSIS パッケージ内の Azure Blob Destination を使用して、出力データを Azure Blob ストレージに書き込みむか、または Azure Blob Source を使用して、Azure Blob ストレージからデータを読み取ります。
Azure Blob 列挙子とともに Foreach ループ コンテナーを使用して、複数の BLOB ファイルのデータを処理します。
リリース ノート
バージョン 1.21.0
改善
- log4j をバージョン 1.2.17 から 2.17.1 にアップグレードしました。
バージョン 1.20.0
機能強化
- ターゲット .NET Framework バージョンを 4.6 から 4.7.2 に更新しました。
- "Azure SQL DW アップロード タスク" の名称を "Azure Synapse Analytics タスク" に変更しました。
バグ修正
- Azure Blob Storage にアクセスしたとき、SSIS を実行しているコンピューターのロケールが en-US ではない場合、パッケージ実行に失敗し、"String not recognized as a valid DateTime value" というエラー メッセージが表示されます。
- Azure Storage Connection Manager の場合、データ ファクトリ管理の ID が認証に使用される場合でも、シークレットが必要になります (使用されません)。
バージョン 1.19.0
機能強化
- Azure Storage 接続マネージャーに Shared Access Signature 認証のサポートを追加。
バージョン 1.18.0
機能強化
- Flexible File タスクの場合、次の 3 点で改善されます:(1) コピー操作と削除操作でワイルドカードが使用できるようになる、(2) ユーザーは削除操作で再帰的検索の有効と無効を切り替えることができる、(3) コピー操作のコピー先となるファイル名を空にし、コピー元のファイル名を維持できる。
バージョン 1.17.0
これは、SQL Server 2019 に対してのみリリースされる修正プログラムのバージョンです。
バグ修正
- Visual Studio 2019 で実行し、SQL Server 2019 をターゲットにすると、柔軟なファイル タスクのソースまたは送信先が
Attempted to access an element as a type incompatible with the array.というエラー メッセージで失敗する場合があります。 - Visual Studio 2019 で実行し、SQL Server 2019 をターゲットにすると、ORC または Parquet 形式を使用した柔軟なファイルのソースまたは送信先が、
Microsoft.DataTransfer.Common.Shared.HybridDeliveryException: An unknown error occurred. JNI.JavaExceptionCheckException.というエラー メッセージで失敗する場合があります。
バージョン 1.16.0
バグ修正
- 特定のケースで、パッケージを実行すると "エラー: ファイルまたはアセンブリ 'Newtonsoft.Json, Version=11.0.0.0, Culture=neutral, PublicKeyToken=30ad4fe6b2a6aeed'、またはその依存関係の 1 つが読み込めませんでした" が報告されます。
バージョン 1.15.0
機能強化
- 柔軟なファイル タスクに、フォルダー/ファイルの削除操作が追加されます
- 柔軟なファイル ソースに、外部/出力データ型の変換機能が追加されます
バグ修正
- 特定のケースで、"配列と互換性のない型の要素にアクセスしようとしました" というエラー メッセージと共に発生する Data Lake Storage Gen2 の接続障害がテストされます
- Azure Storage エミュレーターのサポートが再開されます
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示