適用対象:![]() SQL Server 2017 (14.x) 以降のバージョン
SQL Server 2017 (14.x) 以降のバージョン
この記事では、Windows サーバー上の 1 つのレプリカと Linux サーバー上のもう 1 つのレプリカを使用して、Always On 可用性グループ (AG) を作成する手順について説明します。
重要
完全な高可用性とディザスター リカバリーのサポートを備えた異種レプリカを含む SQL Server クロスプラットフォーム可用性グループが DH2i DxEnterprise で使用できます。 詳細については、「オペレーティング システムが混在する SQL Server 可用性グループ」を参照してください。
DH2i を使用したクロスプラットフォーム可用性グループの詳細については、次のビデオをご覧ください。
レプリカが異なるオペレーティング システム上にあるため、この構成はクロスプラットフォームです。 この構成は、プラットフォーム間の移行またはディザスター リカバリー (DR) を目的として使用してください。 この構成では、高可用性はサポートされていません。
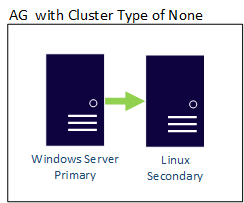
先に進む前に、Windows と Linux での SQL Server インスタンスのインストールと構成について理解しておく必要があります。
シナリオ
このシナリオでは、2 台のサーバーが異なるオペレーティング システム上に配置されています。
WinSQLInstance という名前の Windows Server 2022 で、プライマリ レプリカがホストされます。
LinuxSQLInstance という名前の Linux サーバーで、セカンダリ レプリカがホストされます。
AG を構成する
AG を作成する手順は、読み取りスケール ワークロード用に AG を作成する手順と同じです。 クラスター マネージャーがないため、AG クラスターの種類は NONE。
この記事のスクリプトでは、山かっこ < と > を使用して、お使いの環境に合う値に置き換える必要がある値を識別しています。 スクリプトには、山かっこそのものは必要ありません。
Windows Server 2022 に SQL Server 2022 (16.x) をインストールし、SQL Server 構成マネージャーから Always On 可用性グループを有効にし、混合モード認証を設定します。
ヒント
このソリューションを Azure で検証する場合は、両方のサーバーを同じ可用性セットに配置して、それらがデータ センター内で確実に分離されるようにします。
可用性グループを有効にする
手順については、「 Always On 可用性グループ機能を有効または無効にする」を参照してください。
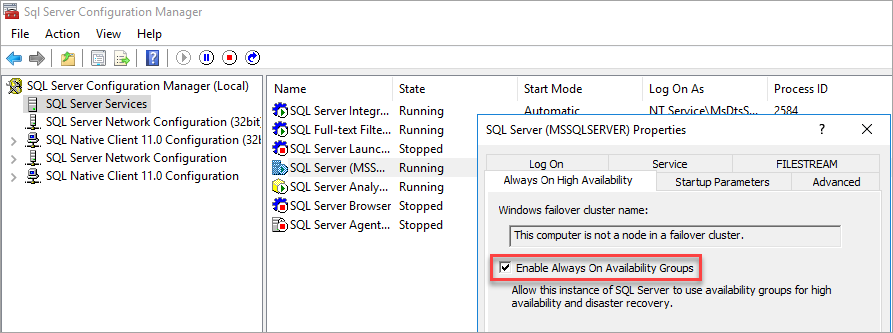
SQL Server 構成マネージャーに、このコンピューターがフェールオーバー クラスター内のノードではないことが示されます。
可用性グループを有効にした後、SQL Server を再起動します。
混合モード認証を設定する
手順については、「サーバーの認証モードの変更」を参照してください。
Linux 上に SQL Server 2022 (16.x) をインストールします。 手順については、「SQL Server on Linux のインストール ガイダンス」を参照してください。
hadrでmssql-confを有効にします。シェル プロンプトから
hadr経由でmssql-confを有効にするには、次のコマンドを発行します。sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1hadrを有効にした後、SQL Server インスタンスを再起動します。sudo systemctl restart mssql-server.service両方のサーバーで
hostsファイルを構成するか、DNS にサーバー名を登録します。Windows と Linux の両方で、TCP 1433 と 5022 に対してファイアウォール ポートを開放します。
プライマリ レプリカで、データベース ログインとパスワードを作成します。
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO注意事項
パスワードは SQL Server の既定のパスワードポリシーに準拠している必要があります。 既定では、パスワードの長さは少なくとも 8 文字で、大文字、小文字、10 進数の数字、記号の 4 種類のうち 3 種類を含んでいる必要があります。 パスワードには最大 128 文字まで使用できます。 パスワードはできるだけ長く、複雑にします。
プライマリ レプリカで、マスター キーと証明書を作成し、秘密キーを使用して証明書をバックアップします。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GO注意事項
パスワードは SQL Server の既定のパスワードポリシーに準拠している必要があります。 既定では、パスワードの長さは少なくとも 8 文字で、大文字、小文字、10 進数の数字、記号の 4 種類のうち 3 種類を含んでいる必要があります。 パスワードには最大 128 文字まで使用できます。 パスワードはできるだけ長く、複雑にします。
証明書と秘密キーを Linux サーバー (セカンダリ レプリカ) の
/var/opt/mssql/dataにコピーします。 これらのファイルを Linux サーバーにコピーするには、pscpを使用できます。秘密キーと証明書のグループと所有権を
mssql:mssqlに設定します。次のスクリプトで、ファイルのグループと所有権を設定します。
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cer次の図では、証明書とキーに対して所有権とグループが正しく設定されています。
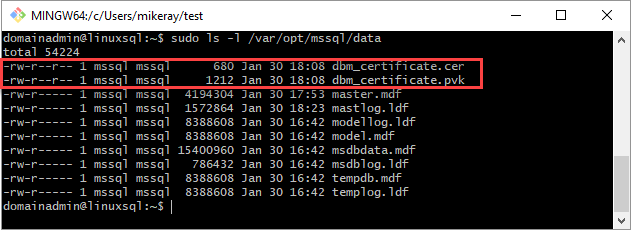
セカンダリ レプリカで、データベース ログインとパスワードを作成し、マスター キーを作成します。
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO注意事項
パスワードは SQL Server の既定のパスワードポリシーに準拠している必要があります。 既定では、パスワードの長さは少なくとも 8 文字で、大文字、小文字、10 進数の数字、記号の 4 種類のうち 3 種類を含んでいる必要があります。 パスワードには最大 128 文字まで使用できます。 パスワードはできるだけ長く、複雑にします。
セカンダリ レプリカで、
/var/opt/mssql/dataにコピーした証明書を復元します。CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GO前の例で、
<private-key-password>をプライマリ レプリカで証明書を作成するときに使用したのと同じパスワードに置き換えます。プライマリ レプリカで、エンドポイントを作成します。
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GO重要
リスナー TCP ポートに対してファイアウォールを開放する必要があります。 前述のスクリプトでは、このポートは 5022 です。 使用可能な任意の TCP ポートを使用してください。
セカンダリ レプリカで、エンドポイントを作成します。 セカンダリ レプリカで上記のスクリプトを繰り返して、エンドポイントを作成します。
プライマリ レプリカで、
CLUSTER_TYPE = NONEで AG を作成します。 このサンプル スクリプトでは、SEEDING_MODE = AUTOMATICを使用して AG を作成します。注記
SQL Server の Windows インスタンスでデータ ファイルとログ ファイルに対して異なるパスを使用する場合、これらのパスはセカンダリ レプリカには存在しないため、SQL Server の Linux インスタンスに対する自動シード処理は失敗します。 クロスプラットフォーム AG に対して次のスクリプトを使用するには、データベースのデータ ファイルとログ ファイルのパスを Windows Server と同じにする必要があります。 または、スクリプトを更新して
SEEDING_MODE = MANUALを設定した後、NORECOVERYでデータベースをバックアップして復元して、データベースをシード処理できます。この動作は、Azure Marketplace のイメージに適用されます。
自動シード処理の詳細については、自動シード処理のディスク レイアウトに関する記事をご覧ください。
スクリプトを実行する前に、お使いの AG の値を更新します。
<WinSQLInstance>を、プライマリ レプリカの SQL Server インスタンスのサーバー名に置き換えます。<LinuxSQLInstance>を、セカンダリ レプリカの SQL Server インスタンスのサーバー名に置き換えます。
AG を作成するには、値を更新し、プライマリ レプリカでスクリプトを実行します。
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); );詳細については、「CREATE AVAILABILITY GROUP」を参照してください。
セカンダリ レプリカで、AG にジョインします。
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOAG 用のデータベースを作成します。 この例の手順では、
TestDBという名前のデータベースを使用します。 自動シード処理を使用する場合は、データ ファイルとログ ファイルの両方に同じパスを設定します。スクリプトを実行する前に、データベース用の値を更新します。
TestDBをお使いのデータベースの名前に変更します。<F:\Path>を、お使いのデータベースとログ ファイルのパスに置き換えます。 データベースとログ ファイルで同じパスを使用します。
既定のパスを使用することもできます。
データベースを作成するには、次のスクリプトを実行します。
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY (NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GOデータベースの完全バックアップを実行します。
自動シード処理を使用していない場合は、セカンダリ レプリカ (Linux) サーバーにデータベースを復元します。 バックアップと復元を使用して SQL Server データベースを Windows から Linux に移行します。 データベースを
WITH NORECOVERYを指定してセカンダリ レプリカに復元します。AG にデータベースを追加します。 サンプル スクリプトを更新します。
TestDBをお使いのデータベースの名前に変更します。 プライマリ レプリカで、次の T-SQL クエリを実行して、データベースを AG に追加します。ALTER AG [ag1] ADD DATABASE TestDB; GOセカンダリ レプリカのデータベースにデータが設定されることを確認します。

プライマリ レプリカをフェールオーバーする
各可用性グループにはプライマリ レプリカが 1 つだけあります。 プライマリ レプリカは読み書きができます。 プライマリになっているレプリカの変更は、フェールオーバーで行うことができます。 一般的な可用性グループでは、クラスター マネージャーによってフェールオーバー プロセスが自動化されます。 クラスターの種類が NONE の可用性グループでは、フェールオーバー プロセスは手動です。
クラスターの種類が NONE の可用性グループでプライマリ レプリカをフェールオーバーするには、2 つの方法があります。
- データ損失のない手動フェールオーバー
- データ損失のある強制的な手動フェールオーバー
データ損失のない手動フェールオーバー
プライマリ レプリカを使用できても、プライマリ レプリカをホストするインスタンスを一時的または永続的に変更する必要がある場合は、この方法を使用します。 データ損失の可能性を排除するため、手動フェールオーバーを実行する前にターゲット セカンダリ レプリカが最新の状態であることを確認します。
データ損失のない手動フェールオーバーを行うには:
現在のプライマリおよびターゲット セカンダリ レプリカを
SYNCHRONOUS_COMMITとします。ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);アクティブなトランザクションが、プライマリ レプリカと少なくとも 1 つの同期セカンダリ レプリカにコミットされていることを確認するために、次のクエリを実行します。
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;synchronization_state_descがSYNCHRONIZEDの場合、セカンダリ レプリカは同期されています。REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITを 1 に更新します。次の例のスクリプトは、
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITという名前の可用性グループでag1を 1 に設定します。 次のスクリプトを実行する前に、ag1を実際の可用性グループの名前に置き換えます。ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);この設定により、すべてのアクティブなトランザクションが、プライマリ レプリカと少なくとも 1 つの同期セカンダリ レプリカにコミットされます。
注記
この設定は、フェールオーバーに固有のものではなく、環境の要件に基づいて設定する必要があります。
ロールの変更に備えて、フェールオーバーに参加していないプライマリ レプリカとセカンダリ レプリカをオフラインに設定します。
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEターゲット セカンダリ レプリカをプライマリに昇格させます。
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;以前のプライマリとその他のセカンダリのロールを
SECONDARYに更新し、以前のプライマリ レプリカをホストする SQL Server インスタンスで次のコマンドを実行します。ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);注記
可用性グループを削除するには、DROP AVAILABILITY GROUP を使います。 種類が NONE または EXTERNAL のクラスターを使って作成された可用性グループでは、可用性グループに含まれるすべてのレプリカでコマンドを実行する必要があります。
データ移動を再開し、プライマリ レプリカがホストされている SQL Server インスタンス上の可用性グループ内のすべてのデータベースに対して、次のコマンドを実行します。
ALTER DATABASE [db1] SET HADR RESUME読み取りスケールの目的で作成した、クラスター マネージャーでは管理されないリスナーをすべて再作成します。 元のリスナーが以前のプライマリを指している場合、それを削除して、新しいプライマリを指すように再作成します。
データ損失のある強制的な手動フェールオーバー
プライマリ レプリカが利用できず、復旧をすぐに行えない場合は、データ損失を伴うセカンダリ レプリカへのフェールオーバーを強制的に実行する必要があります。 ただし、フェールオーバー後に元のプライマリ レプリカが回復した場合は、それによってプライマリの役割が引き継がれます。 各レプリカが異なる状態になるのを回避するには、データ損失を伴う強制フェールオーバー後に、可用性グループから元のプライマリを削除します。 元のプライマリがオンラインに戻ったら、その中の可用性グループ全体を削除します。
プライマリ レプリカ N1 からセカンダリ レプリカ N2 へのデータ損失を伴う手動フェールオーバーを強制的に実行するには、次の手順を行います。
セカンダリ レプリカ (N2) で、強制フェールオーバーを開始します。
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;新しいプライマリ レプリカ (N2) 上で、元のプライマリ (N1) を削除します。
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';すべてのアプリケーション トラフィックがリスナーまたは新しいプライマリ レプリカに向けられていることを確認します。
元のプライマリ (N1) がオンラインになった場合は、直ちに、元のプライマリ (N1) 上で可用性グループ AGRScale をオフラインにします。
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEデータまたは同期されていない変更がある場合は、ビジネス ニーズに合わせてバックアップまたはその他のデータ レプリケート オプションを使用して、そのデータを保存します。
次に、元のプライマリ (N1) から可用性グループを削除します。
DROP AVAILABILITY GROUP [AGRScale];元のプライマリ レプリカ (N1) 上の可用性グループ データベースを削除します。
USE [master] GO DROP DATABASE [AGDBRScale] GO(省略可能) 必要に応じて、N1 を新しいセカンダリ レプリカとして可用性グループ AGRScale に追加できるようになりました。
この記事では、移行または読み取りスケール ワークロードをサポートするクロスプラットフォーム AG を作成する手順を確認しました。 手動によるディザスタリカバリーに使用できます。 AG をフェールオーバーする方法についても説明しました。 クロスプラットフォーム AG ではクラスターの種類 NONE が使用され、高可用性はサポートされていません。