ODBC アプリケーションでのアラインメントの問題は、通常、他のアプリケーションと同じ問題はありません。 つまり、ほとんどの ODBC アプリケーションには、アラインメントに関する問題がほとんどまたはまったくありません。 アドレスをアラインしない場合のペナルティは、ハードウェアとオペレーティング システムによって異なり、わずかなパフォーマンス低下や致命的な実行時エラーと同じくらい小さい場合があります。 そのため、ODBC アプリケーション、特にポータブル ODBC アプリケーションでは、データを適切に配置するように注意する必要があります。
ODBC アプリケーションでアライメントの問題が発生する例の 1 つは、大きなメモリ ブロックを割り当て、そのメモリのさまざまな部分を結果セット内の列にバインドする場合です。 これは、一般的なアプリケーションが実行時に結果セットの形状を決定し、それに応じてメモリを割り当ててバインドする必要がある場合に発生する可能性が最も高くなります。
たとえば、アプリケーションがユーザーによって入力された SELECT ステートメントを実行し、このステートメントから結果をフェッチするとします。 この結果セットの形状はプログラムの書き込み時には認識されないため、アプリケーションは結果セットの作成後に各列の型を決定し、それに応じてメモリをバインドする必要があります。 これを行う最も簡単な方法は、大きなメモリ ブロックを割り当て、そのブロック内の異なるアドレスを各列にバインドすることです。 列のデータにアクセスするために、アプリケーションはその列にバインドされたメモリをキャストします。
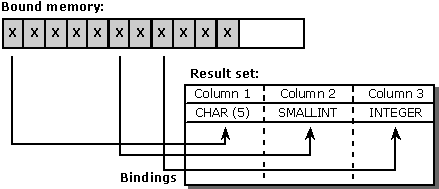
次の図は、サンプルの結果セットと、各 SQL データ型の既定の C データ型を使用してメモリ ブロックをバインドする方法を示しています。 各 "X" は、1 バイトのメモリを表します。 (この例では、列にバインドされているデータ バッファーのみを示しています。これは、わかりやすくするために行われます。実際のコードでは、長さ/インジケーター バッファーもアラインする必要があります)。
 する
する
バインドされたアドレスが Address 配列に格納されていると仮定すると、アプリケーションは次の式を使用して、各列にバインドされたメモリにアクセスします。
(SQLCHAR *) Address[0]
(SQLSMALLINT *) Address[1]
(SQLINTEGER *) Address[2]
2 番目と 3 番目の列にバインドされたアドレスは奇数バイトで始まり、3 番目の列にバインドされているアドレスは、SDWORD のサイズである 4 つで割り切れないことに注意してください。 一部のマシンでは、これは問題になりません。他の人には、わずかなパフォーマンス低下を引き起こします。それ以外の場合は、致命的な実行時エラーが発生します。 より良い解決策は、各バインドされたアドレスを自然なアラインメント境界に配置することです。 UCHAR の場合は 1、SWORD の場合は 2、SDWORD の場合は 4 であると仮定すると、次の図に示す結果が得られます。ここで、"X" は使用されるメモリのバイトを表し、"O" は未使用のメモリのバイトを表します。
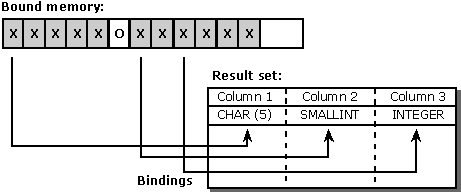
このソリューションでは、アプリケーションのすべてのメモリを使用するわけではありませんが、アラインメントの問題は発生しません。 残念ながら、各列は型に応じて個別に配置する必要があるため、このソリューションを実装するにはかなりの量のコードが必要です。 より簡単な解決策は、次の図に示す例の 4 である、最大の配置境界のサイズですべての列を配置することです。
 によるバインド
によるバインド
このソリューションでは大きな穴が残りますが、実装するコードは比較的単純で高速です。 ほとんどの場合、これは未使用のメモリで支払われるペナルティを相殺します。 このメソッドを使用する例については、「 SQLBindCol の使用」を参照してください。