対象者:![]() SQL Server 2016 (13.x) およびそれ以降のバージョン
SQL Server 2016 (13.x) およびそれ以降のバージョン ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL Database in Microsoft Fabric
SQL Database in Microsoft Fabric
データ仮想化 を使用すると、外部データをデータベースに読み込まずに、Transact-SQL (T-SQL) クエリを外部データに対して実行できます。 PolyBase は、SQL Server と Azure SQL 全体でデータ仮想化を実装するデータベース エンジン機能です。 外部データ ソース、オプションのファイル形式、および外部テーブルを定義し、他のテーブルと同様に SELECT を使用して外部テーブルにクエリを実行します。
このガイドは、次のことに役立ちます。
- 対応する SQL プラットフォームとバージョンによってサポートされる PolyBase の機能を理解してください。
-
OPENROWSET、外部テーブル、およびデータのクエリまたは取り込みのBULK INSERTを選択します。 - 一般的なシナリオについては、ステップ バイ ステップのリンクに従ってください。
- 運用ワークロードのパフォーマンス、トラブルシューティング、ベスト プラクティスを確認します。
一般的なユース ケース
次の表では、考えられる使用シナリオについて説明します。
| シナリオ | 用途 |
|---|---|
| アドホック ファイルの探索 | OPENROWSET(BULK ...) |
| BI/レポート用の再利用可能なファイル クエリ | ファイル上の外部テーブル |
| データベース間クエリ (SQL Server、Oracle、Teradata、MongoDB、ODBC) | 外部テーブルを含む PolyBase コネクタ |
| クエリ結果をファイルにエクスポートする |
CREATE EXTERNAL TABLE AS SELECT (CETAS) |
| テーブルへの一括取り込み |
BULK INSERTまたはOPENROWSET(BULK ...)INSERT ... SELECT |
利用可能な機能はどこにありますか?
次の表は、各 SQL プラットフォームで使用できる PolyBase とデータ仮想化のコア機能を示しています。 この表を使用して、詳細なガイドを使用する前に、プラットフォームで何ができるかを判断します。
| 特徴 | SQL Server 2019 | SQL Server 2022 | SQL Server 2025 | Azure SQL Database | Azure SQL Managed Instance | Microsoft Fabric の SQL データベース |
|---|---|---|---|---|---|---|
| 外部テーブル | はい | はい | はい | はい | はい | はい |
| OPENROWSET (BULK) | はい 1 | はい | はい | はい | はい | はい |
| CETAS (エクスポート) | いいえ | はい | はい | いいえ | はい | いいえ |
| CSV/区切りファイル | はい 2 | はい | はい | はい | はい | はい |
| Parquet ファイル | いいえ | はい | はい | はい | はい | はい |
| Delta Lake テーブル | いいえ | はい | はい | いいえ | いいえ | いいえ |
| 別の SQL Server に接続する | はい | はい | はい | いいえ | いいえ | いいえ |
| Azure SQL Database または Azure SQL Managed Instance に接続する | はい 3 | はい 3 | はい 3 | いいえ | いいえ | いいえ |
| Oracle/Teradata/MongoDB への接続 | はい | はい | はい | いいえ | いいえ | いいえ |
| Azure Blob Storage に接続する | はい | はい | はい | はい | はい | いいえ |
| ADLS Gen2 に接続する | いいえ | はい | はい | はい | はい | いいえ |
| S3 互換ストレージに接続する | いいえ | はい | はい | いいえ | いいえ | いいえ |
| OneLake に接続する (Fabric) | いいえ | いいえ | いいえ | いいえ | いいえ | はい |
| プッシュダウン計算 | はい | はい | はい | いいえ | いいえ | いいえ |
| マネージド ID 認証 | いいえ | いいえ | はい 4 | はい | はい | いいえ |
1 SQL Server 2019 (15.x) では、ローカル およびネットワーク ファイル パスの OPENROWSET(BULK...) がサポートされます。 SQL Server 2022 (16.x) 以降のバージョンでは、 OPENROWSET(BULK...) では、 FORMAT = 'PARQUET'、 FORMAT = DELTA、 FORMAT = 'CSV'を使用したクラウド ストレージからの読み取りもサポートされています。
SQL Server 2019 (15.x) での 2 つの CSV サポートには Hadoop が必要です。 SQL Server 2022 (16.x) 以降のバージョンでは、CSV は Hadoop なしでネイティブにサポートされています。
3 SQL Server コネクタ (sqlserver://) を使用します。 データベース スコープの資格情報は、別の SQL Server への接続と同じ手順で Azure SQL エンドポイントを対象とします。
4 マネージド ID 認証は、Azure Blob Storage (ABS) と ADLS Gen2 に接続するためにサポートされています。 オンプレミスの SQL Server 用の Azure VM 上の Azure Arc 対応 SQL Server または SQL Server が必要です。 Azure SQL Database と Azure SQL Managed Instance でネイティブに使用できます。
注
SQL Server 2025 (17.x) 以降では、Azure Blob Storage、ADLS Gen2、または S3 互換ストレージ上のデータ ファイル (CSV、Parquet、デルタ) に対してクエリを実行することはネイティブ エンジン機能であり、PolyBase サービスをインストールまたは実行する必要がなくなりました。 RDBMS コネクタ (SQL Server、Oracle、Teradata、MongoDB、ODBC) では、PolyBase サービスをインストールして実行する必要があります。 SQL Server 2025 (17.x) では、以前は Windows でのみ使用できたこれらのコネクタに対する Linux サポートも追加されています。
外部データに対してクエリを実行する
特定のシナリオを選択する前に、外部データのクエリを実行する 3 つの方法を理解してください。
| 方法 | 構文 | 次の場合に使用します。 | 認証 | PolyBase が必要 |
|---|---|---|---|---|
| OLE DB アドホック クエリ | OPENROWSET(provider, connection, query) |
永続的なオブジェクトを使用せずに 1 回限りすばやくクエリを実行する場合、または Microsoft Entra ID 認証が必要な場合 | SQL 認証、Windows 認証、Microsoft Entra ID (MSOLEDBSQL) | いいえ |
| アドホック クエリのファイル | OPENROWSET(BULK ...) |
テーブルを作成する前に、ファイル データをすばやく調べるか、スキーマをテストする必要がある | SAS トークン、アクセス キー、マネージド ID、Microsoft Entra ID | はい (Azure SQL Database と Azure SQL Managed Instance の場合) SQL Server インスタンスの場合は No |
| 永続データ コネクタ |
CREATE EXTERNAL TABLE
sqlserver://、oracle://、teradata://など |
運用には、定期的なアクセス、ガバナンス、統計、プッシュダウンの計算が必要です | SQL 認証のみ | はい |
POLYBase サービスは、SQL Server 2019 (15.x) および SQL Server 2022 (16.x) のクラウド ファイル アクセスに必要です。 SQL Server 2025 (17.x) 以降のバージョンでは、PolyBase を使用しない CSV、Parquet、Delta がネイティブにサポートされています。
意思決定ガイド
| シナリオ | レコメンデーション |
|---|---|
| リモート SQL に Microsoft Entra ID 認証が必要であるか、PolyBase サービスを回避したい |
OPENROWSET(MSOLEDBSQL, ...)を使用する (アドホック、永続的なオブジェクトなし) |
| 永続的なテーブル、統計、またはリモート データベースへのプッシュダウン計算が必要です | PolyBase コネクタ (CREATE EXTERNAL TABLE、sqlserver://、oracle://、teradata://、mongodb://) でodbc://を使用します。
OPENROWSETはコネクタをサポートしていません |
| 新しいファイルを探索するか、スキーマをテストしています |
OPENROWSET(BULK ...)を使用する (高速反復、永続的なオブジェクトなし) |
| ファイルデータを変換しながらテーブルに取り込む |
OPENROWSET(BULK ...) から INSERT ... SELECT を使用する |
| 多くのユーザーまたはアプリケーションのガバナンスまたは共有アクセスが必要です |
CREATE EXTERNAL TABLEを使用してアクセス許可とメタデータを一元化する |
| Fabric の SQL データベースで作業しています | アドホック OneLake クエリまたは再利用可能なアクセス用の外部テーブルに OPENROWSET(BULK ...) を使用する。外部ストレージの場合は OneLake ショートカットを使用する |
シナリオを選択する
3 つの方法を理解したら、次のいずれかのガイドを使用して、特定のユース ケースを実装します。
ファイルのクエリ (Parquet、CSV、またはデルタ)
データが Azure Blob Storage、ADLS Gen2、S3 互換ストレージ、または OneLake 上の Parquet、CSV、または Delta ファイルにある場合は、次のいずれかのガイドに従います。
| シナリオ | 推奨ガイド | プラットフォーム |
|---|---|---|
| Parquet または CSV ファイルに対するクイック アドホック クエリ |
OPENROWSET を使用してください。 外部テーブルは必要ありません |
SQL Server 2022 (16.x) 以降のバージョン、Azure SQL Database、Azure SQL Managed Instance、Fabric の SQL データベース |
| 永続的なスキーマを使用した Parquet ファイルに対するクエリの繰り返し | Parquet で外部テーブルを作成する | SQL Server 2022 (16.x) 以降のバージョン、Azure SQL Database、Azure SQL Managed Instance、Fabric の SQL データベース |
| 外部テーブルを使用して CSV ファイルにクエリを実行する | 区切りテキストのファイル形式で外部テーブルを作成する | SQL Server 2019 (15.x) 以降のバージョン、Azure SQL Database、Azure SQL Managed Instance、Fabric の SQL データベース |
| Delta Lake テーブルのクエリを実行する | を使用して外部テーブルを作成する FILE_FORMAT = DeltaLakeFileFormat |
SQL Server 2022 (16.x) 以降のバージョン |
| クエリ結果 を Parquet または CSV ファイルにエクスポートする (CETAS) |
CREATE EXTERNAL TABLE AS SELECT を使用する |
SQL Server 2022 (16.x) 以降のバージョン、Azure SQL Managed Instance |
次のいずれかのステップ バイ ステップ チュートリアルに従うこともできます。
| チュートリアル | 説明 |
|---|---|
| SQL Server 2022 の PolyBase の概要 | Parquet と CSV、外部テーブル、フォルダー ナビゲーションを使用した OPENROWSET について説明します。 |
| PolyBase を使用して S3 互換オブジェクト ストレージ内の Parquet ファイルを仮想化する | SQL Server 2022 (16.x) 以降のバージョンのチュートリアル。 |
| PolyBase を使用して CSV ファイルを仮想化する | SQL Server 2022 (16.x) 以降のバージョンのチュートリアル。 |
| PolyBase を使用してデルタ テーブルを仮想化する | SQL Server 2022 (16.x) 以降のバージョンのチュートリアル。 |
| Azure SQL Database を使用したデータ仮想化 (プレビュー) | Parquet および CSV 用の Azure SQL Database ガイド。 |
| Azure SQL Managed Instance によるデータ仮想化 | Parquet、CSV、および CETAS 用の Azure SQL Managed Instance ガイド。 |
| FabricのSQLデータベースにおけるデータ仮想化 | OneLake ファイルのための「ファブリック」内のSQLデータベースガイド。 |
別の SQL Server インスタンス、Azure SQL Database、または SQL Managed Instance に接続する
SQL Server 2019 (15.x) 以降のバージョンでは、PolyBase では、リンク サーバーを使用せずに、別の SQL Server インスタンス、Azure SQL Database、または Azure SQL Managed Instance のテーブルに対してクエリを実行できます。
Important
sqlserver:// コネクタは、Fabric の SQL データベースではサポートされていません。 PolyBase RDBMS コネクタでは、 CREATE DATABASE SCOPED CREDENTIAL を介した SQL 認証が使用され、Microsoft Entra ID、マネージド ID、またはサービス プリンシパル認証はサポートされません。 Fabric の SQL データベースには Microsoft Entra 認証が必要であるため、PolyBase を使用して接続することはできません。
| Step | 何をすべきか |
|---|---|
| 1. PolyBase をインストールする | Windows に PolyBase をインストールするか、Linux に PolyBase をインストールする |
| 2. 資格情報を作成する |
CREATE DATABASE SCOPED CREDENTIAL ターゲット ログインを使用する |
| 3. 外部データ ソースを作成する | CREATE EXTERNAL DATA SOURCE ... WITH (LOCATION = 'sqlserver://<server>') |
| 4. 外部テーブルを作成する | CREATE EXTERNAL TABLE ... WITH (LOCATION = '<db>.<schema>.<table>') |
| 5. クエリ | SELECT * FROM <external_table> |
ヒント
SQL Server コネクタ (sqlserver://) は、Azure SQL Database と Azure SQL Managed Instance でも機能します。 同じ手順を使用し、 LOCATION を Azure SQL エンドポイント ( sqlserver://myserver.database.windows.net など) に設定します。
詳細なガイドについては、「 SQL Server の外部データにアクセスするように PolyBase を構成する」を参照してください。
Oracle、Teradata、または MongoDB に接続する
SQL Server 2019 (15.x) 以降のバージョンでは、PolyBase ODBC コネクタを使用して Oracle、Teradata、MongoDB、Cosmos DB に対してクエリを実行できます。
| データ ソース | ガイド | 必要条件 |
|---|---|---|
| Oracle | Oracle 上の外部データにアクセスするための PolyBase の構成 | SQL Server 2019 (15.x) 以降のバージョン、Oracle クライアント ドライバー |
| Teradata | Teradata 上の外部データにアクセスするための PolyBase の構成 | SQL Server 2019 (15.x) 以降のバージョン、Teradata ODBC ドライバー |
| MongoDB/Cosmos DB | MongoDB 上の外部データにアクセスするための PolyBase の構成 | SQL Server 2019 (15.x) 以降のバージョン、MongoDB ODBC ドライバー |
| 任意の ODBC ソース | ODBC ジェネリック型の外部データにアクセスするための PolyBase の構成 | SQL Server 2019 (15.x) 以降のバージョン (Windows) (SQL Server 2025 (17.x) 以降の Linux) |
Azure Blob Storage または ADLS Gen2 に接続する
| SQL プラットフォーム | 認証オプション | ガイド |
|---|---|---|
| SQL Server 2022 (16.x) 以降のバージョン | SAS トークン、アクセス キー、マネージド ID (SQL Server 2025 (17.x) 以降) | Azure Blob Storage の外部データにアクセスするように PolyBase を構成する |
| SQL Server 2019 (15.x) | アクセス キー (Hadoop コネクタ経由) | Azure Blob Storage の外部データにアクセスするように PolyBase を構成する |
| Azure SQL Database | SAS トークン、マネージド ID、Microsoft Entra パススルー | Azure SQL Database を使用したデータ仮想化 (プレビュー) |
| Azure SQL Managed Instance | SAS トークン、マネージド ID | Azure SQL Managed Instance によるデータ仮想化 |
SQL Server 2022 (16.x) では、URI プレフィックスが変更されました。 SQL Server 2019 (15.x) 以前のバージョンから移行する場合:
-
Azure Blob Storage:
wasb[s]://を次の値に変更するabs:// -
ADLS Gen2:
abfs[s]://をadls://に変更する
詳細については、「 Azure Blob Storage の外部データにアクセスするように PolyBase を構成する」を参照してください。
S3 互換オブジェクト ストレージに接続する
SQL Server 2022 (16.x) 以降のバージョンでは、Amazon S3、MinIO、Ceph などの S3 互換ストレージがサポートされています。
詳しくは、「S3 互換オブジェクト ストレージの外部データにアクセスするように PolyBase を構成する」をご覧ください。
CREATE EXTERNAL TABLE AS SELECT (CETAS) を使用してデータをエクスポートする
CETAS は、Azure Blob Storage、ADLS Gen2、または S3 互換ストレージの外部ファイル (Parquet または CSV) にクエリ結果をエクスポートします。
| SQL プラットフォーム | サポートされている | エクスポート形式 | メモ |
|---|---|---|---|
| SQL Server 2022 (16.x) 以降のバージョン | はい | Parquet、CSV | サーバー構成が必要: polybase エクスポートを許可する |
| Azure SQL Managed Instance | はい | Parquet、CSV | 既定では無効 |
| Azure SQL Database | いいえ | なし | 該当なし |
| Fabric の SQL データベース | いいえ | なし | 該当なし |
Transact-SQL リファレンスについては、「 CREATE EXTERNAL TABLE AS SELECT (CETAS)」を参照してください。
簡単スタートの例
例 1: Parquet ファイルに対するアドホック クエリ (OPENROWSET)
外部テーブルは必要ありません。 SQL Server 2022 (16.x) 以降のバージョン、Azure SQL Database、Azure SQL Managed Instance、および Fabric の SQL データベースで動作します。
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
例 2: Azure Blob Storage の CSV 上の外部テーブル
この例は、PolyBase をサポートするすべての SQL プラットフォームで動作します。
手順 1: データベース マスター キー (DMK) を作成します。 資格情報には SAS トークン シークレットが格納されるため、この手順が必要です。 ただし、マネージド ID または Microsoft Entra 認証を使用する場合は、この手順を実行できます。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';手順 2: SAS トークンを使用して資格情報を作成する。 先頭の
?を省略します。CREATE DATABASE SCOPED CREDENTIAL MyStorageCred WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<your_SAS_token>'; -- omit the leading '?'手順 3: 外部データ ソースを作成する。
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH ( LOCATION = 'abs://mycontainer@mystorageaccount.blob.core.windows.net', CREDENTIAL = MyStorageCred );手順 4: CSV のファイル形式を作成します。
CREATE EXTERNAL FILE FORMAT CsvFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2 ) );手順 5: 外部テーブルを作成します。
CREATE EXTERNAL TABLE dbo.SalesExternal ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer NVARCHAR (100) ) WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/data/sales/', FILE_FORMAT = CsvFormat );手順 6: 外部テーブルに対してクエリを実行します。
SELECT * FROM dbo.SalesExternal WHERE OrderDate >= '2025-01-01';
例 3: 別の SQL Server のテーブルに対してクエリを実行する
この例は、SQL Server 2019 (15.x) 以降のバージョンで動作します。
手順 1: データベース マスター キーを作成する (資格情報にパスワードが格納されるため必要)。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';手順 2: リモート SQL Server インスタンスの資格情報を作成します。
CREATE DATABASE SCOPED CREDENTIAL RemoteSqlCred WITH IDENTITY = 'remote_user', SECRET = '<password>';手順 3: 外部データ ソースを作成します。
CREATE EXTERNAL DATA SOURCE RemoteSqlServer WITH ( LOCATION = 'sqlserver://remote-server.contoso.com', PUSHDOWN = ON, CREDENTIAL = RemoteSqlCred );手順 4: 外部テーブル (
LOCATIONの 3 部構成の名前) を作成します。CREATE EXTERNAL TABLE dbo.RemoteCustomers ( CustomerId INT, CustomerName NVARCHAR (200) COLLATE SQL_Latin1_General_CP1_CI_AS ) WITH ( DATA_SOURCE = RemoteSqlServer, LOCATION = 'SalesDB.dbo.Customers' );手順 5: サーバー間でクエリを実行する。
SELECT c.CustomerName, s.Amount FROM dbo.RemoteCustomers AS c INNER JOIN dbo.LocalSales AS s ON c.CustomerId = s.CustomerId;
例 4: CETAS を使用して Parquet に結果をエクスポートする
SQL Server 2022 (16.x) 以降のバージョンの Azure SQL Managed Instance で動作します。
手順 1: CETAS を有効にする (SQL Server のみ)。
EXECUTE sp_configure 'allow polybase export', 1; RECONFIGURE;手順 2: 資格情報とデータ ソースを作成する (前の例から再利用)。
手順 3: Parquet エクスポート用のファイル形式を作成する。
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );手順 4: クエリ結果をエクスポートする。
CREATE EXTERNAL TABLE dbo.Sales2025Export WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/exports/sales_2025.parquet', FILE_FORMAT = ParquetFormat ) AS SELECT * FROM Sales.Orders WHERE OrderDate >= '2025-01-01';
PolyBase の T-SQL 構成要素
シナリオを実装する前に、PolyBase で使用される主要な T-SQL オブジェクトとその組み合わせについて理解してください。
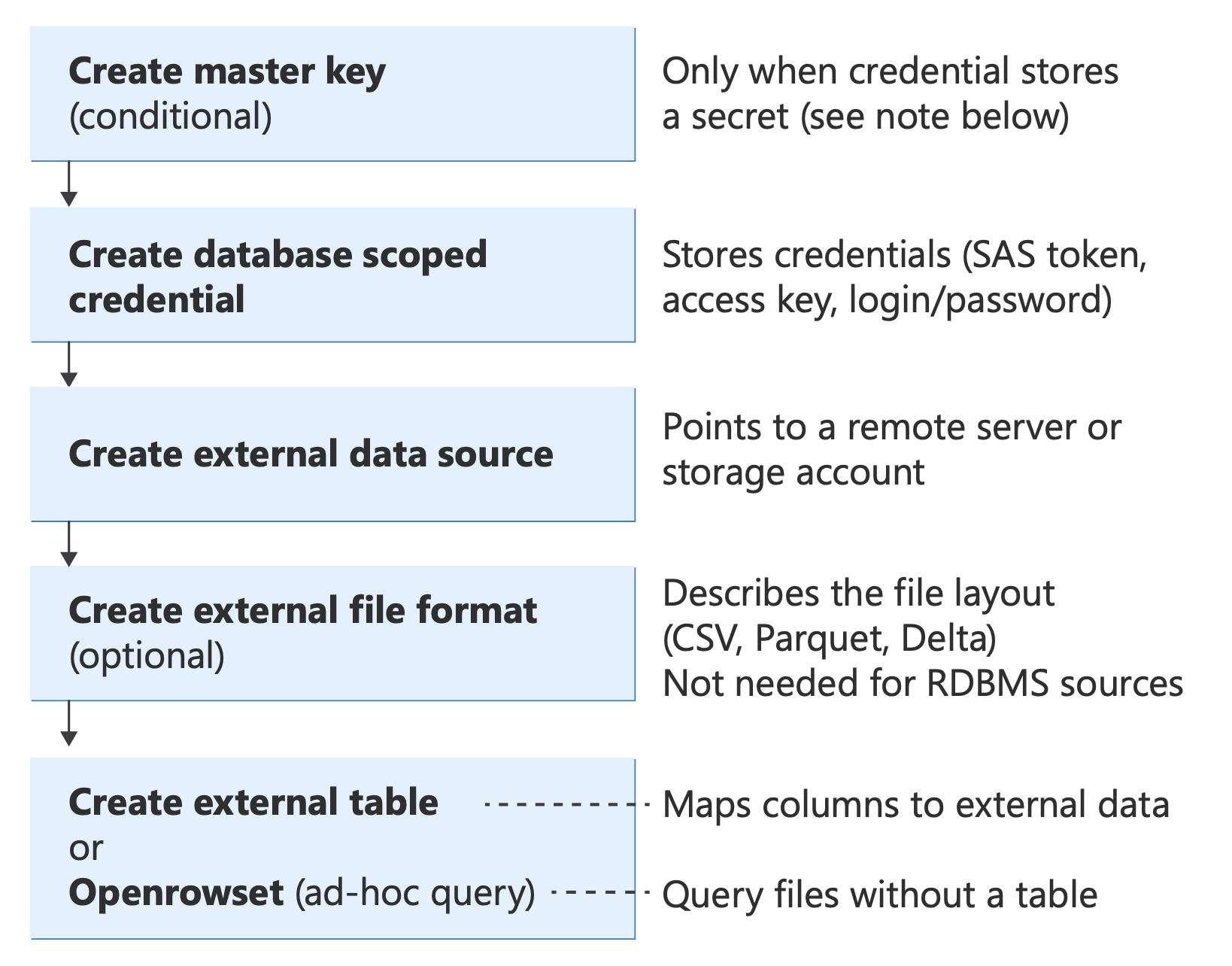
認証 (データベース マスター キー、資格情報) からデータ ソースとファイル形式、クエリ メソッド (外部テーブル、OPENROWSET、BULK INSERT、CETAS) まで、PolyBase T-SQL オブジェクトとそのリレーションシップを示す図。
これらの T-SQL ステートメントの詳細については、以下を参照してください。
- 外部データ ソースを作成する
- 外部ファイル形式を作成
- CREATE EXTERNAL TABLE(外部テーブルを作成)
- OPENROWSET
- SELECT として外部テーブルを作成する (CETAS)
すべてのオブジェクトの完全な Transact-SQL リファレンスについては、「 PolyBase Transact-SQL リファレンス」を参照してください。
Important
外部ファイル形式のデータ型マッピングを確認します。 外部ファイル形式を作成するか、 OPENROWSETを使用してファイルにクエリを実行すると、PolyBase はソース データ型 (Parquet、CSV、Delta、Oracle、Teradata、MongoDB) を SQL Server データ型に自動的にマップします。 型が一致しない場合、サイレント切り捨て、精度の低下、またはクエリ エラーが発生する可能性があります。 たとえば、Parquet DECIMAL(38,18) は DECIMAL(18,0)にマップされます。 外部テーブル列または WITH 句を定義する前に、マッピング テーブルを確認します。 完全なリファレンスについては、「 PolyBase を使用した型マッピング」を参照してください。
CREATE MASTER KEY が必要なのはいつですか?
データベース マスター キー (DMK) は、 CREATE MASTER KEY 構文を使用して作成されます。 DMK は、データベース スコープの資格情報内に格納されているシークレットを暗号化します。 資格情報にシークレット値が含まれている場合、つまりパスワード、トークン、またはアクセス キーを格納する場合にのみ必要です。
DMK が必要です (資格情報にはシークレットが格納されます)。
認証の種類 IDENTITY値シークレットがある Dmk SAS トークン 'SHARED ACCESS SIGNATURE'はい 必須 S3 アクセス キー 'S3 ACCESS KEY'はい 必須 SQL ログイン/基本認証 '<username>'はい 必須 ストレージ アカウント アクセス キー '<storage_account_name>'はい 必須 DMK は必要ありません (シークレットは格納されません)。
認証の種類 IDENTITY値シークレットがある Dmk マネージド ID 'Managed Identity'いいえ 必須ではない Microsoft Entra ID 'User Identity'または'Managed Identity'いいえ 必須ではない
ヒント
CREATE DATABASE SCOPED CREDENTIAL ステートメントにシークレットがない場合は、DMK は必要ありません。 マネージド ID と Microsoft Entra ID 認証は、プラットフォームへの信頼を委任します。 データベースにはパスワードやトークンは格納されません。
例:
このクエリ例では、DMK が必要です (資格情報は SAS トークンを格納します)。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';
CREATE DATABASE SCOPED CREDENTIAL SasCred
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<your_SAS_token>';
このクエリ例では、DMK は必要ありません (マネージド ID、シークレットなし)。
CREATE DATABASE SCOPED CREDENTIAL ManagedIdentityCred
WITH IDENTITY = 'Managed Identity';
このクエリ例では、DMK は必要ありません (Microsoft Entra パススルー、シークレットなし)。
CREATE DATABASE SCOPED CREDENTIAL EntraIdCred
WITH IDENTITY = 'User Identity';
OPENROWSET および外部テーブルを使用したリモート データ アクセス
SQL Server には、リモート データのクエリを実行するための 3 つの異なるアプローチが用意されています。 構文、認証、アーキテクチャの違いを理解している場合は、適切なアプローチを選択できます。
| 方法 | 構文 | 接続先 | 認証 | PolyBase サービス | プラットフォーム |
|---|---|---|---|---|---|
| OLE DB クエリ | OPENROWSET(provider, connection, query) |
MSOLEDBSQL、SQLOLEDB、またはその他のプロバイダーを介した OLE DB ソース | SQL 認証、Windows 認証、Microsoft Entra ID (MSOLEDBSQL) | いいえ | SQL Server (サポートされているすべてのバージョン) |
| ファイル クエリ | OPENROWSET(BULK ...) |
ローカル ディスク、ネットワーク、またはクラウド上のファイル (Azure BLOB、ADLS、S3、OneLake) | SAS トークン、アクセス キー、マネージド ID、Microsoft Entra ID | クラウドの場合ははい*;ローカルの場合は [いいえ] | SQL Server 2005;SQL Server 2022 (16.x) 以降のバージョン (クラウド);Azure SQL |
| PolyBase コネクタ |
CREATE EXTERNAL TABLEとCREATE EXTERNAL DATA SOURCEを使用して、sqlserver://、oracle://、teradata://、mongodb://、odbc:// |
リモート SQL Server、Oracle、Teradata、MongoDB、ODBC ソース | SQL 認証のみ | はい | SQL Server 2019 (15.x) 以降のバージョン (Windows);SQL Server 2025 (17.x) 以降のバージョン (Linux) |
POLYBase サービスは、SQL Server 2019 (15.x) および SQL Server 2022 (16.x) のクラウド ファイル アクセスに必要です。 SQL Server 2025 (17.x) 以降のバージョンでは、ネイティブ クラウド ファイルがサポートされており、CSV、Parquet、または Delta の PolyBase は不要です。
各アプローチを使用するタイミング
次の場合に OLE DB OPENROWSET を使用します。
- 永続的なオブジェクトを作成せずに、1 回限りのアドホック クエリを迅速に実行する
- Microsoft Entra ID またはマネージド ID 認証 (MSOLEDBSQL 経由)
- PolyBase サービスの依存関係の回避
- OLE DB プロバイダーを使用して任意のデータ ソースに接続する
ファイル OPENROWSET(BULK) を使用して、次の場合に使用します。
- アドホック ファイルの探索とスキーマの検出
- テーブル定義にコミットする前のクイック変換とプレビュー
- インラインでの柔軟な列変換 (キャスト、フィルター処理、計算列)
- 頻繁に変更されない、永続的なメタデータを必要としないデータ
CREATE EXTERNAL TABLE で PolyBase コネクタを使用します。
- 複数のユーザーまたはアプリケーションがアクセスする永続的で再利用可能なテーブル定義
- 統計とクエリ プランの最適化を必要とする運用ワークロード
- リモート ソースへのプッシュダウン計算 (Oracle、SQL Server などにプッシュするフィルター)
- 共有ガバナンスとセキュリティ (一度作成すると、ユーザーは
SELECTアクセス許可のみが必要) - リモート ソースで SQL 認証を使用できる場合
OPENROWSET (OLE DB) - アドホック リモート クエリ (PolyBase サービスは必要ありません)
OLE DB 形式の OPENROWSET は、OLE DB プロバイダーを介してリモート データ ソースに接続し、パススルー クエリを実行して、結果を行セットとして返します。 これは、リンク サーバーに代わる 1 回限りのアドホックな代替手段です。 永続的なメタデータは作成されません。 この構文では PolyBase サービスは必要ありません。また、クラウド ファイルや外部データ ソースもサポートされていません。
この例のクエリは、OLE DB (PolyBase ではなく) 経由でリモート SQL Server に接続します。
SELECT *
FROM OPENROWSET (
'MSOLEDBSQL',
'Server=remote-server;Database=AdventureWorks;Trusted_Connection=yes;',
'SELECT TOP 10 * FROM AdventureWorks.Sales.SalesOrderHeader'
);
OPENROWSET(BULK) - ファイル ベースのクエリ (PolyBase)
BULKのOPENROWSET形式は、ファイルから直接データを読み取ります。 SQL Server 2019 (15.x) 以前のバージョンでは、ローカルまたは UNC ファイル パスから読み取り、フォーマット ファイルが必要です。 SQL Server 2022 (16.x) 以降のバージョンでは、パラメーターとDATA_SOURCE パラメーターを使用してFORMATから読み取ることができます。 このアプローチは、データ仮想化に使用される PolyBase 統合バージョンです。
PolyBase とデータ仮想化のコンテキストでは、このガイドがOPENROWSETを参照する場合は、外部ファイルに対してクエリを実行するためのOPENROWSET(BULK ...)句を含むFORMAT構文を意味します。
例:
このクエリ例では、Azure Blob Storage (SQL Server 2022 以降のバージョン) から Parquet ファイルを読み取ります。
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'data/sales/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET'
) AS [result];
このクエリ例では、インライン パス (Azure SQL Database、Azure SQL Managed Instance) を使用して Parquet ファイルを読み取ります。
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
OPENROWSET と外部テーブルのどちらを使用するべきか
OPENROWSET(BULK ...)テーブルと外部テーブルの両方で、T-SQL を使用して外部データのクエリを実行できますが、さまざまなユース ケース向けに設計されています。 次の表は、シナリオに適したアプローチを決定するのに役立つ主な違いをまとめたものです。
| 能力 | OPENROWSET(BULK ...) |
外部テーブル |
|---|---|---|
| Purpose | アドホック探索と 1 回限りのクエリ | 永続的で再利用可能なテーブル定義 |
| データベースに格納されているメタデータ | No. クエリの実行後に何も保存されない | Yes. テーブル定義、データ ソース、およびファイル形式はデータベース オブジェクトとして格納されます |
| スキーマ定義 | ファイル (Parquet) から自動的に推論されるか、 WITH 句を使用してインラインで指定されます |
CREATE EXTERNAL TABLE ステートメントで明示的に定義されている |
| アクセス許可 | 必要ADMINISTER BULK OPERATIONSまたはADMINISTER DATABASE BULK OPERATIONS |
作成したら、テーブルに対する標準の SELECT アクセス許可で十分です |
| 計算列 | Yes.
SELECTリストに式と計算列を追加します。filename()やfilepath()などのメタデータ関数は、ここでしか使用できません。 |
No. 固定列リスト;ビューまたは外部テーブルを読み取るクエリで変換を実行する |
| 統計 | Azure SQL: sys.sp_create_openrowset_statistics を使用した単一列の手動統計。SQL Server 2022 (16.x) 以降のバージョン: 述語に対して統計を自動作成します (SQL Server では手動での統計作成はありません)。
OPENROWSET の手動統計を参照してください。 |
すべてのプラットフォームでの完全な CREATE STATISTICS サポートに加えて、SQL Server 2022 (16.x) 以降のバージョンでの自動作成。
外部テーブルの手動統計の作成を参照してください。 |
| プッシュダウン | 制限付きサポート。 エンジンはフィルターをファイル スキャンにプッシュダウンする可能性がありますが、リモート RDBMS ソースへのプッシュダウンはありません | Yes. RDBMS コネクタのプッシュダウン計算をサポートします (SQL Server、Oracle、Teradata、MongoDB) |
| 最適な用途 | データ探索、スキーマ検出、プロトタイプ作成クエリ、1 回限りのデータ読み込み、柔軟な変換 | 運用ワークロード、繰り返しクエリ、ユーザー間の共有アクセス、ダッシュボード、レポート |
柔軟性が必要な場合は OPENROWSET を使用する
OPENROWSETを使用して、永続的なオブジェクトを作成せずに、ファイルの探索、さまざまなスキーマのテスト、計算列と変換の追加を行います。 たとえば、ファイル パスを列として抽出したり、データ型をインラインでキャストしたり、1 つのクエリで計算式をフィルター処理したりすることができます。
このクエリ例には、計算列と変換が含まれています。
SELECT result.filename() AS [FileName],
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
CAST (OrderDate AS DATE) AS OrderDate,
Amount,
OrderDate
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025';
ヒント
filepath()およびfilename()関数は、Azure SQL Database、Azure SQL Managed Instance、および SQL Server 2022 (16.x) 以降のバージョンで使用できます。 ファイル パスの一部をフィルター処理し (パーティションの削除)、ソース ファイル名を列として公開することができます。外部テーブルでは直接はできません。
永続化とガバナンスが必要な場合に外部テーブルを使用する
複数のユーザーまたはアプリケーションが同じ外部データに対して繰り返しクエリを実行する必要がある場合は、外部テーブルを使用します。 スキーマ、データ ソース、および資格情報を 1 回定義し、データベースに格納します。 コンシューマーは、テーブル SELECT アクセス許可のみを必要とします。
外部テーブルでは 統計もサポートされています。統計は、クエリ オプティマイザーが、より優れた実行プランを構築するために使用します。 統計は手動で作成することも、エンジンで自動的に作成することもできます (SQL Server 2022 (16.x) 以降のバージョン)。
このクエリ例では、クエリ プランを改善するために、外部テーブルに統計を作成します。
CREATE STATISTICS Stats_OrderDate
ON dbo.SalesExternal(OrderDate)
WITH FULLSCAN;
両方の方法の統計の詳細については、「 PolyBase のパフォーマンスに関する考慮事項 - 統計」を参照してください。
BULK INSERT と OPENROWSET(BULK): どれを使用する必要がありますか?
BULK INSERTとOPENROWSET(BULK ...)の両方で、基になる同じ一括読み込みエンジンを使用して、ファイルから SQL Server にデータをインポートします。 ただし、構文、柔軟性、結果でできることは異なります。 次の表に主要な相違点を示します。
注
BULK INSERT は、Fabric の SQL データベースでは使用できません。 Fabric の場合は、OneLake に対して OPENROWSET(BULK ...) を使用します。
| 能力 | BULK INSERT |
OPENROWSET(BULK ...) |
|---|---|---|
| 基本的な目的 | ファイルからターゲット テーブルに直接データを読み込む |
またはSELECT ステートメントで使用するINSERT ... SELECTを返します。 |
| 使用パターン | スタンドアロン ステートメント: BULK INSERT <table> FROM '<file>' |
クエリ内で使用する必要があります: SELECT * FROM OPENROWSET(BULK ...) または INSERT INTO <table> SELECT * FROM OPENROWSET(BULK ...) |
| ターゲット テーブルが必要ですか? | Yes. 常にテーブルに直接書き込む | No. 任意の場所に挿入せずにそこから SELECT したり、任意のテーブルまたは一時テーブルに挿入したりできます。 |
| 読み込み中の列変換 | 制限付きサポート。 データは、ファイルからテーブルへの流れ(そのまま)であり、フォーマットファイルまたは列の順序によって制御されるマッピングによります。 | 完全なサポート。 式、CAST、WHERE フィルター、JOIN その他のテーブル、および計算列を周囲の環境に追加できます SELECT |
| 表のヒント |
WITH句には、BATCHSIZE、CHECK_CONSTRAINTS、FIRE_TRIGGERS、KEEPIDENTITY、KEEPNULLS、TABLOCKなどのサポートが含まれています |
INSERT ... SELECT * FROM OPENROWSET(BULK ...) WITH (TABLOCK, IGNORE_CONSTRAINTS, ...)構文を使用してテーブル ヒントをサポートします |
| ラージ オブジェクト (LOB) の単一値インポート | サポートしていません | Yes. ファイル全体を 1 つの SINGLE_BLOB、または SINGLE_CLOB 値としてインポートするSINGLE_NCLOB、、をサポートします |
| ファイルの書式設定 | Yes. (XML および XML 以外) を介してサポートされます | Yes. サポート対象 (XML および XML 以外) |
| クラウド ファイル アクセス (Azure Blob Storage、ADLS Gen2、S3) | Yes.
DATA_SOURCE パラメーターを使用してサポートされます (SQL Server 2017 (14.x) 以降のバージョン、Azure SQL) |
Yes.
DATA_SOURCE パラメーターまたはインライン URL と FORMAT 句 (SQL Server 2022 (16.x) 以降のバージョン、Azure SQL) でサポートされます |
| Parquet または Delta ファイル | サポートされていません。 CSV/区切りテキストのみ | Yes.
FORMAT = 'PARQUET'またはFORMAT = 'DELTA' (SQL Server 2022 (16.x) 以降のバージョン、Azure SQL) でサポートされます |
| 必要なアクセス許可 |
ADMINISTER BULK OPERATIONSまたはADMINISTER DATABASE BULK OPERATIONSに加えて、ターゲットテーブルのINSERT |
ADMINISTER BULK OPERATIONS または ADMINISTER DATABASE BULK OPERATIONS |
| 最小ログ記録 | Yes. 単純復旧モデルまたは一括ログ復旧モデルでサポートされます。 TABLOCK |
Yes.
INSERT ... SELECTとTABLOCKを一緒に使用する場合にサポートされます |
BULK INSERT を選択するタイミング
BULK INSERTは、ファイルからテーブルへの読み込みが簡単で、インポート中にデータを変換、フィルター処理、結合する必要がない場合に使用します。 CSV またはその他の区切りファイルには、より単純な構文が使用されます。
このクエリ例では、Azure Blob Storage からテーブルに直接 CSV ファイルを読み込みます。
BULK INSERT Sales.Invoices
FROM 'invoices/inv-2025-01.csv'
WITH (
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
);
このクエリ例では、列マッピング用のフォーマット ファイルを含むローカル ファイルを読み込みます。
BULK INSERT dbo.Products
FROM 'C:\Data\products.csv'
WITH (
FORMATFILE = 'C:\Data\products.fmt',
FIRSTROW = 2,
TABLOCK
);
OPENROWSET(BULK) を選択するタイミング
次の条件のうち 1 つ以上が必要な場合は、 OPENROWSET(BULK ...) を使用します。
- 最初にテーブルを作成せずに、ファイル データのクエリまたはプレビューを行います。
- インポート中にデータを変換、フィルター処理、または結合します。
-
Parquet または Delta ファイルを読み込みます (これらの形式をサポート
OPENROWSETのみ)。 -
ファイル全体を 1 つの LOB 値 (
SINGLE_BLOB、SINGLE_CLOB、SINGLE_NCLOB) としてインポートします。
このクエリ例では、データをどこにも挿入せずに、Azure Blob Storage の CSV ファイルをプレビューします。
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ','
) AS src;
このクエリ例では、変換とフィルター処理を使用してデータを挿入します。
INSERT INTO Sales.Invoices (InvoiceDate, Amount, Customer)
SELECT CAST (InvoiceDate AS DATE),
Amount * 1.1, -- Apply a 10% markup
UPPER(Customer)
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2
) WITH (
InvoiceDate VARCHAR (10),
Amount DECIMAL (18, 2),
Customer VARCHAR (100)
) AS src
WHERE Amount IS NOT NULL;
このクエリ例では、Parquet ファイルを読み込みます ( BULK INSERTではできません)。
INSERT INTO Sales.Invoices
SELECT *
FROM OPENROWSET (
BULK 'data/invoices/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET') AS src;
このクエリ例では、XML ファイル全体を 1 つの varbinary(max) 値としてインポートします。
INSERT INTO dbo.XmlDocuments (DocContent)
SELECT BulkColumn
FROM OPENROWSET (
BULK 'C:\Data\catalog.xml',
SINGLE_BLOB
) AS x;
ヒント
1 つの方法は、OPENROWSET(BULK ...)内のSELECTから始めてファイル データを探索して検証し、変換が必要ない場合は最終的な運用負荷のBULK INSERTに切り替える方法です。 Parquet または Delta のサポートまたはインライン フィルター処理が必要な場合は、 OPENROWSETを使用してください。
詳細については、次の関連ガイドを参照してください。
- BULK INSERT または OPENROWSET(BULK...) を使用して SQL Server にデータをインポートする: セキュリティに関する考慮事項を含む詳細なサイド バイ サイド ガイド。
-
データの一括インポートとエクスポート (SQL Server):すべての一括データ移動方法 (bcp、
BULK INSERT、OPENROWSET) の概要です。 - BULK INSERT (Transact-SQL): 完全な T-SQL リファレンス。
- OPENROWSET BULK (Transact-SQL): 完全な T-SQL リファレンス。
- Azure Blob Storage 内のデータへの一括アクセスの例: Azure Storage で両方の方法を使用するサイド バイ サイドの例。
-
OPENROWSET Bulk Rowset Provider (SQL Server) を使用してラージ オブジェクト データを一括インポートする:
SINGLE_BLOB、SINGLE_CLOB、SINGLE_NCLOBの例。 - フォーマット ファイルを使用してデータを一括インポートする (SQL Server):両方の方法でファイルの使用法を書式設定します。
便利なメタデータ関数
OPENROWSETテーブルまたは外部テーブルを使用して外部ファイルに対してクエリを実行する場合は、いくつかの組み込み関数とプロシージャを使用して、ファイル メタデータの検査、スキーマの検出、パーティション対応クエリの実装を行うことができます。
filepath() と filename()
filepath()関数とfilename()関数は、結果セット内の各行のファイル パスまたはファイル名の一部を返します。 これらは特に次の場合に役立ちます。
パーティションの削除: フォルダー セグメント (年/月/日のパーティションなど) をフィルター処理して、エンジンがすべてをスキャンするのではなく、一致するファイルのみを読み取るようにします。
ソース メタデータの公開: クエリ結果に元のファイル名またはパスを列として含めます。これは、監査やデバッグに役立ちます。
| Function | 返品 | 例 |
|---|---|---|
filename() |
各行のソース ファイルのファイル名 (拡張子を含む) | sales_2025_01.parquet |
filepath(N) |
パスのワイルドカード (*) の BULK番目のフォルダー セグメント。N は 1 から始まります |
パス sales/2025/01/*.parquetの場合、 filepath(1) は 2025を返し、 filepath(2) は戻ります 01 |
適用対象: Azure SQL Database、Azure SQL Managed Instance、SQL Server 2022 (16.x) 以降のバージョン、Fabric の SQL データベース。
このクエリ例では、パーティションの削除に filepath() を使用し、ソース ファイルを識別するための filename() を使用します。
/2025/ フォルダーの下にあるファイルのみを読み取り、/06/サブフォルダーの下にあるファイルのみを読み取ります。
SELECT result.filename() AS SourceFile,
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
*
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025'
AND result.filepath(2) = '06';
ヒント
サブクエリや CTE ではなく、filepath()句にWHERE フィルターを配置します。 フィルターが WHERE 句にある場合、エンジンはファイル スキャン レベルでパーティションの削除を実行できるため、I/O が大幅に削減されます。
sp_describe_first_result_set - OPENROWSET 列の型を特定する
Parquet ファイルで OPENROWSET を使用すると、エンジンは列データ型を自動的に推論します (スキーマ推論)。 推論される型は、必要以上に大きくなる可能性があります。 たとえば、Parquet メタデータには最大長が含まれていないため、多くの場合、文字列は varchar(8000) として推論されます。 この選択により、パフォーマンスが低下し、より多くのメモリが消費される可能性があります。
クエリを終了するsp_describe_first_result_setに、を使用して推論されたスキーマを検査します。 推論された型が表示されたら、 WITH 句でより狭い型を指定してパフォーマンスを向上させます。
手順 1: 推論されたスキーマを調べます。
EXECUTE sp_describe_first_result_set N' SELECT * FROM OPENROWSET( BULK ''abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet'', FORMAT = ''PARQUET'' ) AS result';出力には、各列の名前、推論されたデータ型、最大長、有効桁数、および小数点以下桁数が表示されます。 varchar(100) で十分な varchar(8000) が表示された場合は、それをオーバーライドします。
手順 2: パフォーマンスを向上させるには、明示的な型を使用します。
SELECT TOP 100 * FROM OPENROWSET ( BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet', FORMAT = 'PARQUET' ) WITH ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer VARCHAR (100) -- much narrower than the inferred varchar(8000) ) AS result;
スキーマ推論は Parquet ファイルでのみ機能します。 CSV ファイルの場合は、常に WITH 句 ( OPENROWSETの場合) または CREATE EXTERNAL TABLE ステートメントで列定義を指定します。
sp_describe_first_result_set は一般的な SQL Server および Azure SQL プロシージャですが、 OPENROWSET クエリに特に役立ちます。 詳細については、 sp_describe_first_result_setをご覧ください。
パフォーマンス、トラブルシューティング、ベスト プラクティス
データ仮想化を実装したら、次のガイドを使用してパフォーマンスを最適化し、問題を診断し、運用環境の準備を確認します。
| 面積 | [アーティクル] | 詳細情報 |
|---|---|---|
| PolyBase のパフォーマンス | SQL Server 用 PolyBase のパフォーマンスに関する考慮事項 | 統計、プッシュダウン、並列処理、およびメモリ管理 |
| プッシュダウン計算 | PolyBase でのプッシュダウン計算 | リモート ソースにプッシュする操作を指定します |
| プッシュダウンが発生したかどうかを確認する方法 | 外部プッシュダウンが発生した場合の確認方法 | クエリ プランと DMV |
| Troubleshooting | PolyBase の監視とトラブルシューティング | よくあるエラーと解決方法 |
| Kerberos 接続 | PolyBase Kerberos の接続性のトラブルシューティング | |
| よくある質問 | PolyBase に関してよく寄せられる質問 | |
| エラーと解決策 | PolyBase エラーと考えられる解決策 |