適用対象:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Microsoft Fabric の SQL データベース
Microsoft Fabric の SQL データベース
Transact-SQL のキーワードの 1 つである OPENXML は、テーブルやビューに類似したインメモリ XML ドキュメントの行セットを提供します。 OPENXML を使用することで、リレーショナル行セット同様に XML データにアクセスできるようになります。 これを実現するため、XML ドキュメントの内部表現の行セット ビューが用意されています。 行セット内のレコードは、データベース テーブルに格納できます。
OPENXML を使用できるのは、行セット プロバイダー、ビュー、または OPENROWSET をソースとして指定できる SELECT ステートメントおよび SELECT INTO ステートメントです。 OPENXML の構文の詳細については、「OPENXML (Transact-SQL)」を参照してください。
OPENXML を使用して XML ドキュメントに対するクエリを記述するには、最初に sp_xml_preparedocumentを呼び出す必要があります。 このプロシージャは XML ドキュメントを解析し、使用準備が整った解析後のドキュメントへのハンドルを返します。 解析後のドキュメントは、XML ドキュメント内のさまざまなノードを DOM (ドキュメント オブジェクト モデル) ツリーで表現したものです。 このドキュメント ハンドルは OPENXML に渡されます。 OPENXML では渡されたパラメーターを基にドキュメントの行セット ビューを用意します。
Note
sp_xml_preparedocument では、SQL 用に更新された MSXML パーサー (Msxmlsql.dll) が使用されます。 このバージョンの MSXML パーサーは、SQL Server をサポートし、MSXML Version 2.6 との下位互換性を維持するように設計されました。
XML ドキュメントの内部表現は、 sp_xml_removedocument システム ストアド プロシージャを呼び出してメモリを解放することによって、メモリから削除する必要があります。
次の図がプロセスを示します。
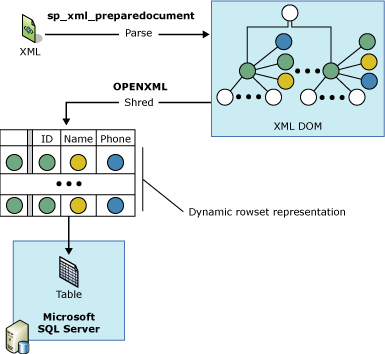
OPENXML を理解するには、XPath クエリと XML を詳しく理解している必要があります。 SQL Server での XPath のサポートの詳細については、「 SQLXML 4.0 での XPath クエリの使用」を参照してください。
Note
OPENXML では、XPath の行と列のパターンを変数としてパラメーター化できます。 プログラマがこのようなパラメーター化を外部ユーザーに公開すると (たとえば、外部で呼び出されるストアド プロシージャからパラメーターが指定される場合)、XPath 式を外部から挿入できる可能性があります。 このような潜在的なセキュリティの問題を回避するために、XPath パラメーターを外部の呼び出し元に公開しないでください。
例
次の例では、 OPENXML ステートメントと INSERT ステートメントで SELECT を使用します。 サンプルの XML ドキュメントには、 <Customers> 要素と <Orders> 要素が含まれています。
最初に、 sp_xml_preparedocument ストアド プロシージャで XML ドキュメントを解析します。 この解析済みのドキュメントでは、XML ドキュメント内のノード (要素、属性、テキスト、コメント) がツリー形式で表示されます。
OPENXML は次に、この解析済みの XML ドキュメントを参照して、この XML ドキュメントのすべてまたは一部の行セットを表示します。
INSERT ステートメントで OPENXML を使用すると、このような行セットのデータをデータベース テーブルに挿入できます。 複数の OPENXML 呼び出しを使用することで、XML ドキュメントの各部の行セット ビューを提供し、各部を処理 (たとえば、別のテーブルに挿入) できます。 この処理は、テーブルへの XML の細分化とも呼ばれます。
次の例では、2 つの <Customers> ステートメントで Customers 要素を <Orders> テーブルに格納し、 Orders 要素を INSERT テーブルに格納することで、XML ドキュメントを細分化しています。 また、この例では、 SELECT を使用して XML ドキュメントから OPENXML と CustomerID を取得する OrderDate ステートメントも示しています。 この処理の最後に sp_xml_removedocumentが呼び出されています。 これは、解析時に作成された内部 XML ツリー表現を保持するために割り当てられたメモリを解放するための処理です。
-- Create tables for later population using OPENXML.
CREATE TABLE Customers (CustomerID varchar(20) primary key,
ContactName varchar(20),
CompanyName varchar(20));
GO
CREATE TABLE Orders( CustomerID varchar(20), OrderDate datetime);
GO
DECLARE @docHandle int;
DECLARE @xmlDocument nvarchar(max); -- or xml type
SET @xmlDocument = N'<ROOT>
<Customers CustomerID="XYZAA" ContactName="Joe" CompanyName="Company1">
<Orders CustomerID="XYZAA" OrderDate="2000-08-25T00:00:00"/>
<Orders CustomerID="XYZAA" OrderDate="2000-10-03T00:00:00"/>
</Customers>
<Customers CustomerID="XYZBB" ContactName="Steve"
CompanyName="Company2">No Orders yet!
</Customers>
</ROOT>';
EXEC sp_xml_preparedocument @docHandle OUTPUT, @xmlDocument;
-- Use OPENXML to provide rowset consisting of customer data.
INSERT Customers
SELECT *
FROM OPENXML(@docHandle, N'/ROOT/Customers')
WITH Customers;
-- Use OPENXML to provide rowset consisting of order data.
INSERT Orders
SELECT *
FROM OPENXML(@docHandle, N'//Orders')
WITH Orders;
-- Using OPENXML in a SELECT statement.
SELECT * FROM OPENXML(@docHandle, N'/ROOT/Customers/Orders')
WITH (CustomerID nchar(5) '../@CustomerID', OrderDate datetime);
-- Remove the internal representation of the XML document.
EXEC sp_xml_removedocument @docHandle;
次の図は、sp_xml_preparedocument によって作成された上記の XML ドキュメントを解析した結果の XML ツリーを表しています。
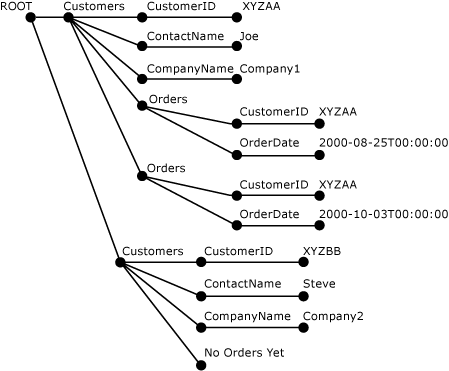
OPENXML のパラメーター
OPENXML のパラメーターは、次のとおりです。
XML ドキュメント ハンドル (idoc)
行にマップされるノードを特定するための XPath 式 (rowpattern)
生成される行セットの説明
行セット列と XML ノード間のマッピング
XML ドキュメント ハンドル (idoc)
ドキュメント ハンドルは、 sp_xml_preparedocument ストアド プロシージャから返されます。
処理するノードを特定するための XPath 式 (rowpattern)
rowpattern として指定する XPath 式で、XML ドキュメントに含まれる一連のノードを特定します。 rowpattern によって特定される各ノードが、OPENXML で生成される行セット内の 1 行に相当します。
XPath 式で特定するノードは、XML ドキュメント内のどの XML ノードでもかまいません。 XML ドキュメント内の一連の要素を rowpattern で特定すると、特定した要素ノードごとに 1 行の行セットが形成されます。 たとえば、 rowpattern の結果が属性になる場合は、 rowpatternによって選択された属性ノードごとに行が作成されます。
生成される行セットの説明
OPENXML では行セット スキーマを使用して、結果の行セットを生成します。 行セット スキーマを指定するときは、次の方法を使用できます。
Edge テーブル形式を使用する
行セット スキーマを指定するにはエッジ テーブル形式を使用してください。 WITH 句は指定しないでください。
これによって、OPENXML からエッジ テーブル形式の行セットが返されます。 この行セットは、解析した XML ドキュメント ツリーのすべてのエッジが行セットの各行にマップされるので、エッジ テーブルと呼ばれます。
エッジ テーブルは XML ドキュメントの詳細構造を 1 つのテーブル内に表現します。 表現される構造には、要素名、属性名、ドキュメント階層、名前空間、処理命令などがあります。 エッジ テーブル形式を使用すると、メタプロパティでは公開されない追加情報を取得できます。 メタプロパティの詳細については、「 Specify Metaproperties in OPENXML」を参照してください。
エッジ テーブルに含まれる追加情報によって、要素と属性のデータ型、ノードの種類、XML ドキュメント構造に関する情報の保存およびクエリを実行できます。 また、独自の XML ドキュメント管理システムを構築することもできます。
エッジ テーブルを使用することで、XML ドキュメントを BLOB (バイナリ ラージ オブジェクト) 入力として受け取り、エッジ テーブルを生成し、ドキュメントを詳細なレベルまで展開および分析するストアド プロシージャを作成できます。 詳細なレベルでは、ドキュメント階層、要素名、属性名、名前空間、および処理命令を検出できます。
また、他のリレーショナル形式へのマッピングが論理的でなく、ntext 型のフィールドでは構造情報が十分得られない場合に、エッジ テーブルを XML ドキュメントの格納形式としても使用できます。
XML パーサーを使用して XML ドキュメントを検査できる場合は、エッジ テーブルを使用しても同じ情報を入手できます。
次の表で、エッジ テーブルの構造について説明します。
| 列名 | データ型 | 説明 |
|---|---|---|
| id | bigint | ドキュメント ノードの一意の ID。 ルート要素の ID 値は 0 です。 負の ID 値は予約済みです。 |
| parentid | bigint | ノードの親の識別子。 この ID で識別される親が親要素だとは限りません。 識別された親が親要素であるかどうかは、この ID で識別されるノードを親とするノードの NodeType によって決まります。 たとえば、ノードがテキスト ノードの場合、その親は属性ノードである可能性があります。 ノードが XML ドキュメントの最上位にある場合、その ParentID は NULL になります。 |
| ノードの種類 | int | XML DOM (オブジェクト モデル) でノードの種類に付けられている番号に応じた、ノードの種類を識別するための整数です。 この列に示される、ノードの種類を示す値を次に示します。 1 = 要素ノード 2 = 属性ノード 3 = テキスト ノード 4 = CDATA セクション ノード 5 = エンティティ参照ノード 6 = エンティティ ノード 7 = 処理命令ノード 8 = コメント ノード 9 = ドキュメント ノード 10 = ドキュメント型ノード 11 = ドキュメント フラグメント ノード 12 = 注釈ノード 詳細については、Microsoft XML (MSXML) SDK の「nodeType Property」の記事を参照してください。 |
| localname | nvarchar(max) | 要素または属性のローカル名。 DOM オブジェクトに名前がない場合は NULL になります。 |
| prefix | nvarchar(max) | ノード名の名前空間のプレフィックス。 |
| namespaceuri | nvarchar(max) | ノードの名前空間 URI。 値が NULL の場合、名前空間はありません。 |
| datatype | nvarchar(max) | 要素行または属性行の実際のデータ型です。それ以外は NULL になります。 データ型は、インライン DTD またはインライン スキーマから推定されます。 |
| prev | bigint | 前の兄弟要素の XML ID。 前に直接の兄弟がない場合は NULL になります。 |
| text | ntext | テキスト形式で表した属性の値または要素のコンテンツです。 エッジ テーブルのエントリに値が必要ない場合は NULL になります。 |
WITH 句を使用した既存のテーブルの指定
WITH 句を使用して、既存のテーブルの名前を指定できます。 これを行うには、OPENXML で使用して行セットを生成できるスキーマを持つ既存のテーブルの名前を指定するだけです。
WITH 句を使用したスキーマの指定
WITH 句を使用して、スキーマ全体を指定できます。 行セットのスキーマを指定するときは、列名と、そのデータ型および XML ドキュメントへのマッピングを指定します。
SchemaDeclaration 内で ColPattern パラメーターを使用することによって、列パターンを指定できます。 指定された列パターンを使用するのは、rowpattern によって識別される XML ノードに行セットの列をマップする場合、およびマッピングの種類を決定する場合です。
列に ColPattern が指定されていない場合、行セットの列は、 flags パラメーターで指定したマッピングに基づいて、同じ名前の XML ノードにマップされます。 一方、ColPattern が WITH 句のスキーマ指定の一部として指定されている場合は、 flags パラメーターで指定したマッピングが上書きされます。
行セット列と XML ノード間のマップ
OPENXML ステートメントでは、必要に応じて、 rowpatternで特定される XML ノードと行セットの列の間のマッピングの種類 (属性中心、要素中心など) を指定できます。 この情報は、XML ノードと行セットの列の間で変換を行うときに使用されます。
マッピングの指定方法は 2 種類で、それらを同時に指定することもできます。
flags パラメーターを使用する方法
flags パラメーターで指定されるマッピングは、XML ノードが行セット内の対応する同名の列にマップされるという名前の対応が前提になっています。
ColPattern パラメーターを使用する方法
ColPatternは XPath 式であり、WITH 句で SchemaDeclaration の一部として指定されます。 ColPattern で指定されるマッピングは、 flags パラメーターで指定されるマッピングを上書きします。
ColPattern でマッピングの種類 (属性中心、要素中心など) を指定できます。ここでの指定は、 flagsによる既定のマッピングを上書きしたり、拡張したりするものです。
ColPattern は次の場合に指定します。
行セット内の列名が、マップされる要素名または属性名と異なっている場合。 このとき ColPattern は、行セットの列をマップする XML の要素名または属性名を特定するために使用されます。
メタプロパティ属性を列にマップする場合。 このとき ColPattern は、行セットの列をマップするメタプロパティを特定するために使用されます。 メタプロパティの使用方法の詳細については、「 OPENXML 内でのメタプロパティの指定」を参照してください。
flags パラメーターと ColPattern パラメーターはどちらも省略できます。 マッピングの指定がない場合、属性中心のマッピングが想定されます。 属性中心のマッピングが、 flags パラメーターの既定値です。
属性中心のマッピング
OPENXML の flags パラメーターを 1 (XML_ATTRIBUTES) に設定すると、 属性中心 のマッピングが指定されます。 flags に XML_ATTRIBUTES が含まれていると、公開される行セットで使用される行は、各 XML 要素が 1 行として表現されます。 XML 属性は名前の対応を基に、SchemaDeclaration で定義した属性、または WITH 句の TableName で指定した属性にマップされます。 名前の対応とは、特定の名前の XML 属性が、行セット内の同名の列に格納されることを意味します。
列名がマップ先の属性名と異なっている場合は、 ColPattern を指定する必要があります。
XML 属性に名前空間の修飾子がある場合は、行セット内の列名にも修飾子が必要です。
要素中心のマッピング
OPENXML の flags パラメーターを 2 (XML_ELEMENTS) に設定すると、 要素中心 のマッピングが指定されます。 要素中心のマッピングは、次の相違点を除けば 属性中心 のマッピングと同じです。
列レベルのパターンが指定されていなければ、マッピングで通例行われる名前の対応 (同名の XML 要素への列のマッピング) によって、非複合サブ要素が選択されます。 取得のとき、サブ要素がさらにサブ要素を含んでいて複合型になっている場合、列は NULL に設定され、 含まれているサブ要素の属性値は無視されます。
同名のサブ要素が複数ある場合、最初のノードが返されます。