作成者: Mark Russinovich
公開日: 2025 年 12 月 16 日
 Coreinfo(3 MB)
Coreinfo(3 MB)
はじめに
Coreinfo は、論理プロセッサと、それらが存在する物理プロセッサ、NUMA ノード、ソケットの間のマッピングと、各論理プロセッサに割り当てられたキャッシュを示すユーティリティです。 低レベルの Windows API (ユーザー モードとカーネル モード) を使用して、オペレーティング システムから直接詳細な CPU トポロジ情報を取得します。 コマンド ライン バージョンでは、"*" などのアスタリスクを持つ論理プロセッサへのマッピングの表現が出力されます。 この UI には、論理コアと物理コア、NUMA ノード、ソケット、キャッシュ階層、リアルタイム パフォーマンス メトリックなど、システムの CPU トポロジのさまざまな側面を調べるために、複数の特殊なビューが用意されています。 Coreinfo は、システムのプロセッサとキャッシュ トポロジに関する分析情報を得るために役立ちます。
インストール
アーカイブをディレクトリに抽出し、アーキテクチャに応じてそのディレクトリ Coreinfo / Coreinfo64 または Coreinfo64aから入力して Coreinfo を実行します。 UI バージョンの CoreInfoEx / CoreInfoEx64 / CoreInfoEx64a を起動します。
メモ: 一部の機能では、情報を完全に取得するために管理特権が必要になる場合があります。
ユーザー インターフェイスの概要
Coreinfo UI は、いくつかの主要なコンポーネントで構成されています。
メイン ウィンドウのレイアウト
- 上部パネル: CPU 名、アーキテクチャ、コア数などのシステム情報を表示します
- ナビゲーション ウィンドウ (左): さまざまなビューにすばやくアクセスできます
- コンテンツ領域 (中央): 選択したビューのデータと視覚化を表示します
- 詳細ウィンドウ (下部): コアまたはセルが選択されている場合に詳細情報が表示されます
- 設定: アクセスの外観オプションとアプリケーションの基本設定
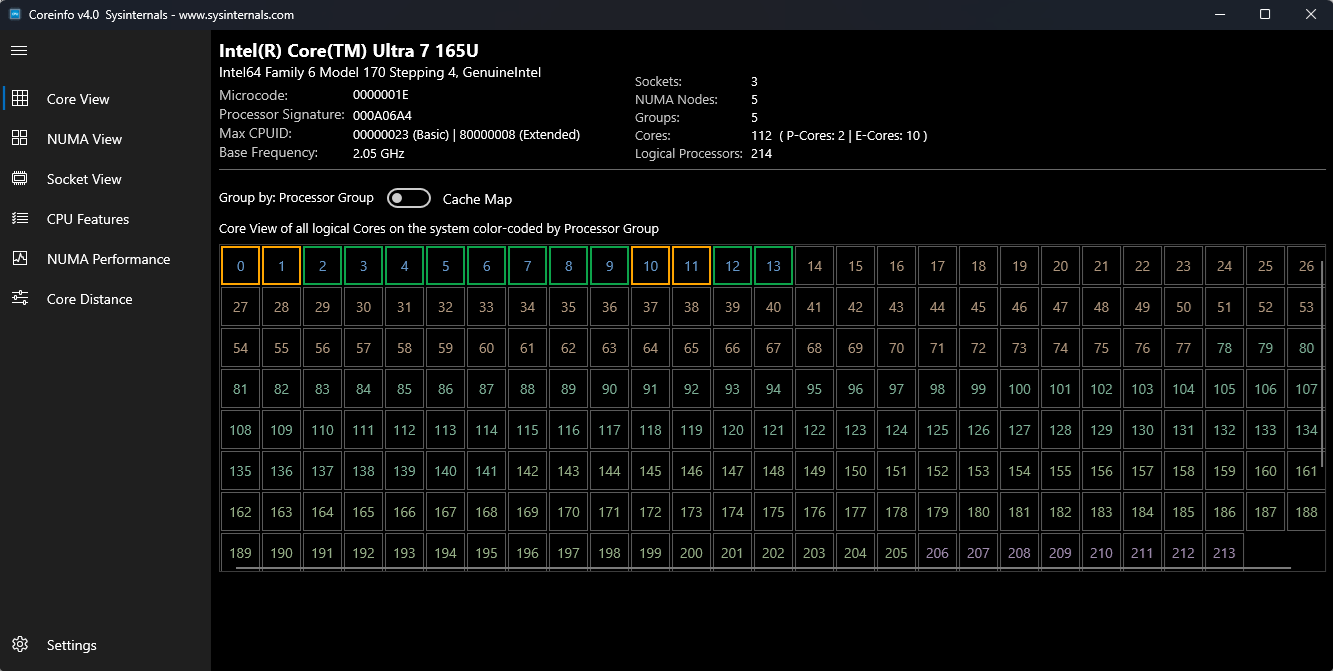 の完全な UI レイアウトを示すメイン ウィンドウ、ダーク モード
の完全な UI レイアウトを示すメイン ウィンドウ、ダーク モード
ナビゲーション画面
左側のナビゲーション ウィンドウでは、次の 6 つの特殊なビューにアクセスできます。
1. コア ビュー
コア ビューには、システム内のすべての論理プロセッサがグリッド レイアウトで表示され、論理コアとその物理リソースの関係が表示されます。
機能:
- グリッド レイアウト: 各セルは論理プロセッサを表します
-
コア タイプ インジケーター:
- P コア (パフォーマンス コア) - 明確に色分け
- E コア (効率コア) - 色が異なる
- 標準コア - 既定の色分け
- キャッシュ マッピングの切り替え: 既定のビューとキャッシュ階層ビューを切り替える
- 対話型選択: コアをクリックすると、下部ウィンドウに詳細情報が表示されます
表示される情報:
- 論理プロセッサ番号
- コアの種類 (該当する場合は P-Core/E-Core)
- 関連するキャッシュ レベル (L1、L2、L3)
- NUMA ノードの割り当て
- ソケットの割り当て
- グループ割り当て
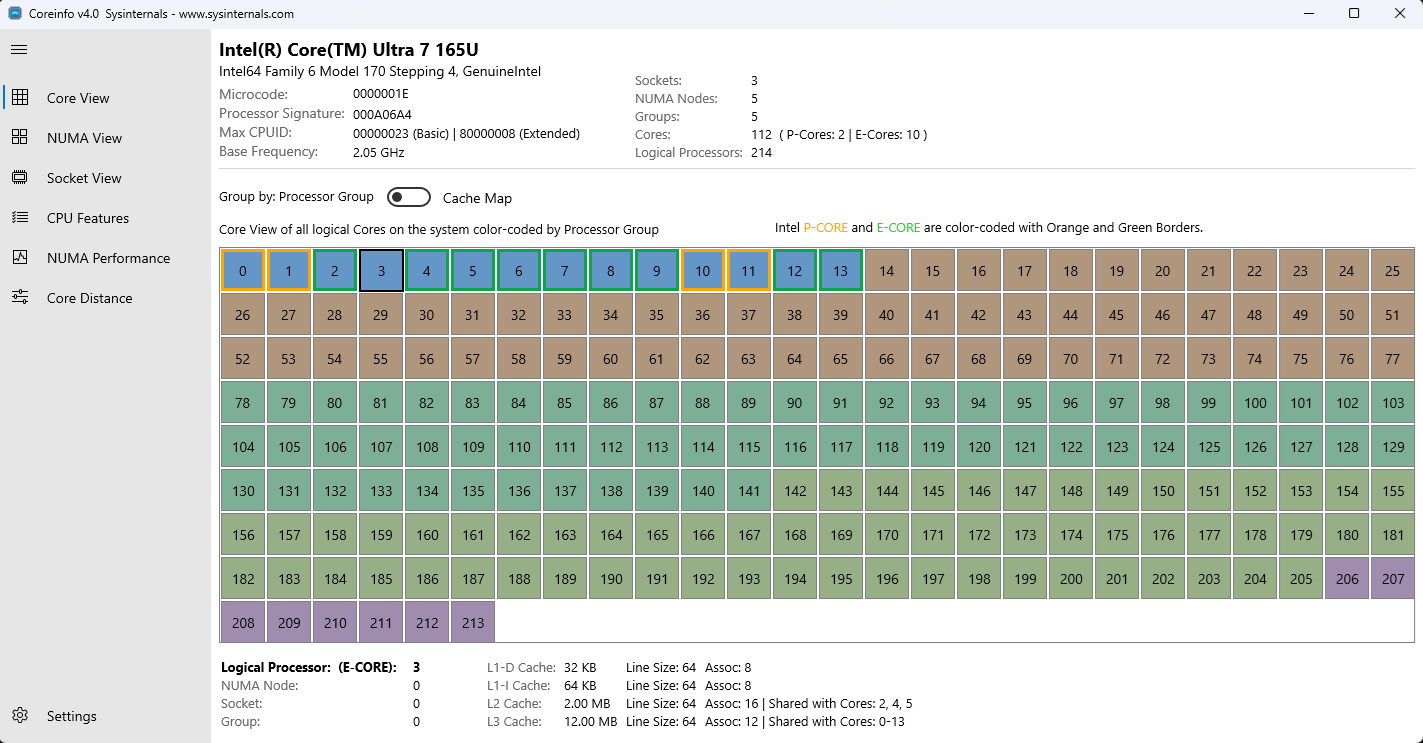 グリッド レイアウトの論理プロセッサを示すコア ビュー コア ビュー
グリッド レイアウトの論理プロセッサを示すコア ビュー コア ビュー
詳細ペイン情報 (コアが選択されている場合):
- プロセッサ マスクとアフィニティ
- キャッシュ階層 (データ キャッシュ、命令キャッシュ、統合キャッシュ)
- キャッシュ のサイズと結合性
- キャッシュ ライン のサイズ
2. NUMA ビュー
NUMA (一様でないメモリ アクセス) ビューでは、NUMA ノードの割り当てによってコアが整理されるため、メモリの局所性とアクセス パターンを簡単に理解できます。
機能:
- ノードベースの構成: NUMAノードごとにグループ化されたコア群
- 物理コアと論理コア: 各ノードの両方のカウントが表示されます
- メモリ情報: NUMA ノードごとに使用可能なメモリを表示します
-
対話型ナビゲーション:
- NUMA ノードを 1 回クリックすると、その詳細が下部の詳細ウィンドウに表示されます
- 選択した NUMA ノードのすべてのコアを表示するコア ビューに移動するには、NUMA ノードをダブルクリックします。
- 階層表示: NUMA ノードとコア間の関係を示します
表示される情報:
- NUMA ノードの数
- NUMA ノードあたりのコア数 (物理および論理)
- ノードあたりのメモリ容量
- ノード間のコア分散
- 効率コア数 (該当する場合)
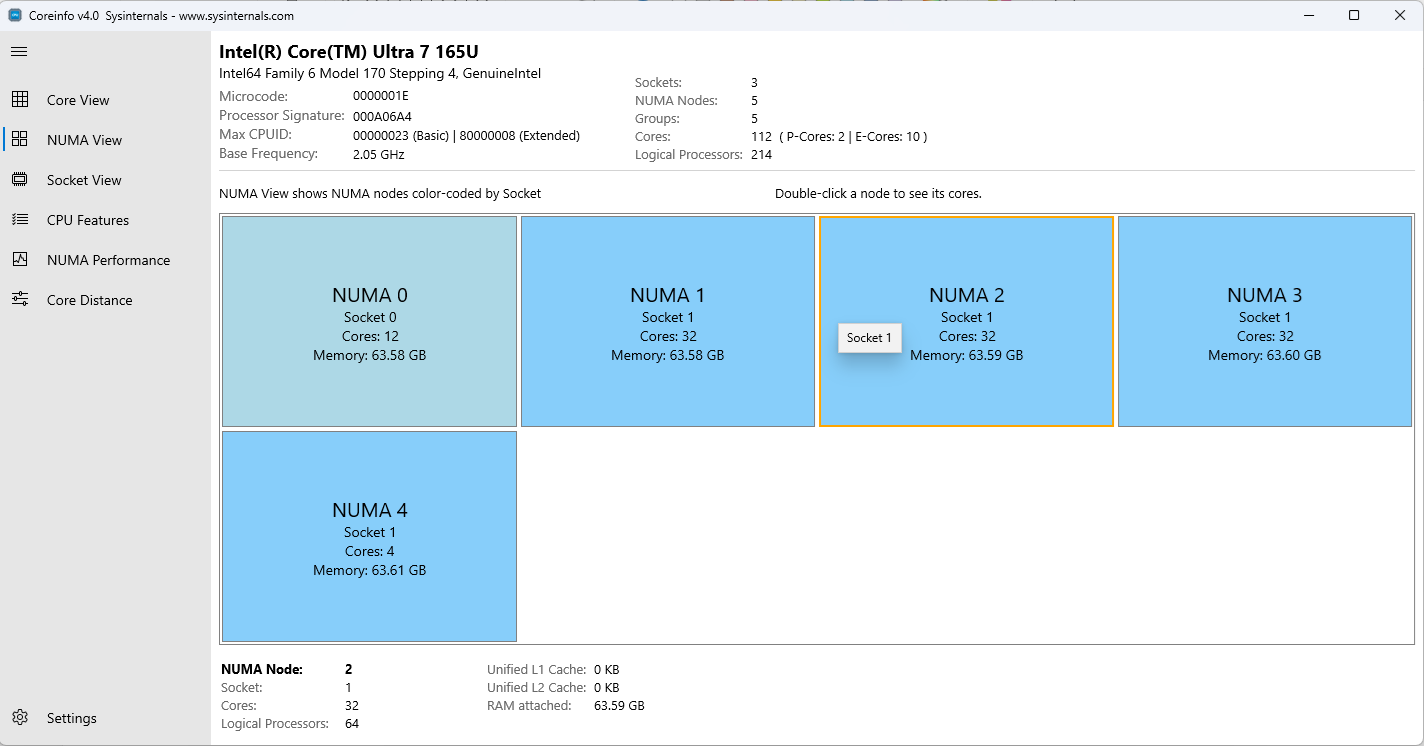 ノード別に整理されたコアを示す NUMA ビュー NUMA ビュー
ノード別に整理されたコアを示す NUMA ビュー NUMA ビュー
ユースケース:
- メモリ アクセス パターンの最適化
- NUMA 対応アプリケーションのパフォーマンスについて
- 最適なパフォーマンスを得るためのスレッド/プロセス配置の計画
3. ソケット ビュー
ソケット ビューには、物理 CPU ソケット別に整理されたコアが表示され、マルチソケット システムとソケット レベルのリソース分散を理解するのに役立ちます。
機能:
- ソケットベース配置: 物理ソケットごとに配置されたコア
- ソケット情報: ソケット数とコア分散
-
対話型ナビゲーション:
- ソケットを 1 回クリックすると、その詳細が下部の詳細ウィンドウに表示されます
- ソケットをダブルクリックして、選択したソケットのすべてのコアを表示するコア ビューに移動します
- キャッシュ共有: ソケット レベルのキャッシュを共有するコアを視覚化する
表示される情報:
- 物理ソケットの数
- ソケットあたりのコア数 (物理および論理)
- ソケット レベルのキャッシュ情報
- ソケットあたりの NUMA ノード数
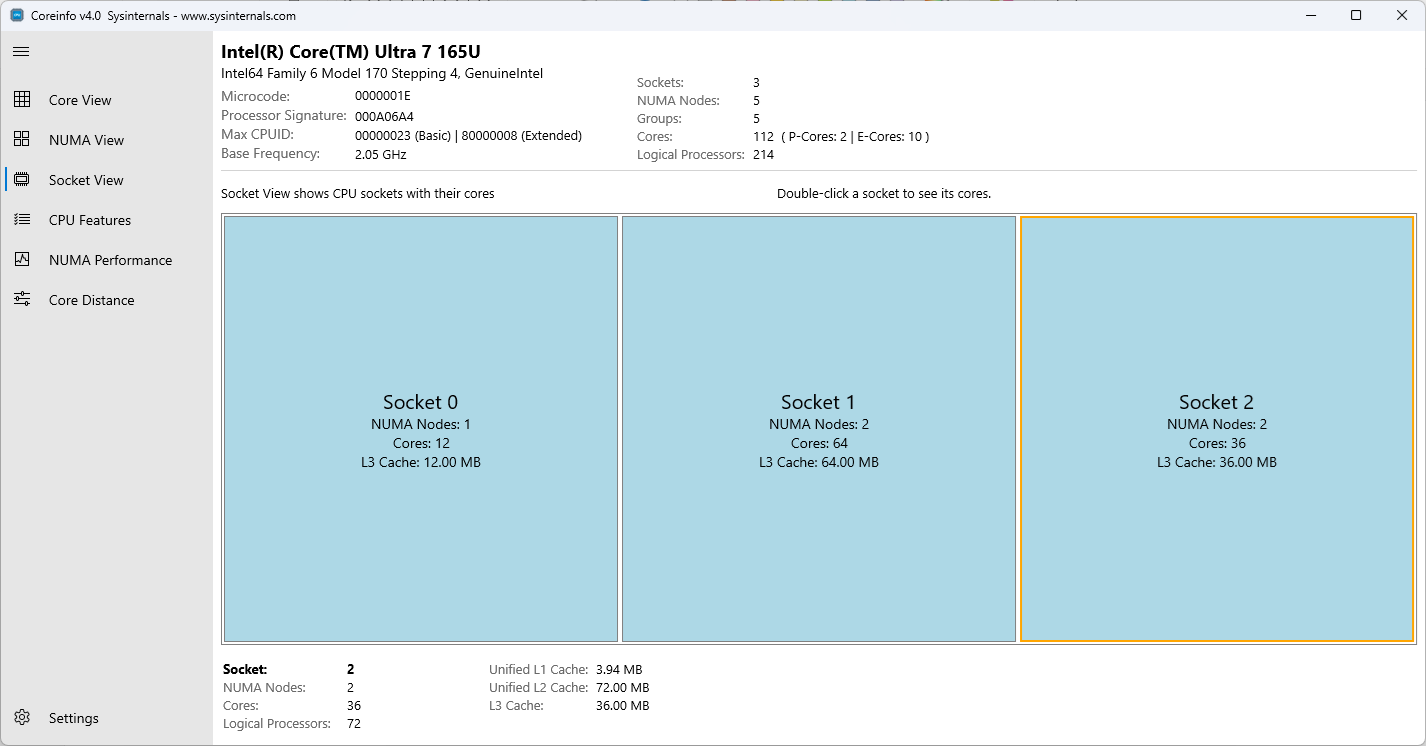 CPU ソケット別に編成されたコアを示すソケット ビュー
CPU ソケット別に編成されたコアを示すソケット ビュー
利用事例:
- マルチソケットシステム分析
- クロスソケット通信コストについて
- マルチソケット サーバーでのワークロード分散の計画
4. CPU 機能ビュー
CPU 機能ビューには、CPU でサポートされているプロセッサ機能、命令セット拡張機能、ハードウェア機能の包括的な一覧が表示されます。
機能:
- 検索可能なリスト: 検索バーを使用して特定の CPU 機能をすばやく見つける
-
ステータス インジケーター: カラー コーディングを使用して、サポートされている機能またはサポートされていない機能の視覚的な表示をクリアする
- サポートされている機能は通常の色で表示されます
- サポートされていない機能または無効な機能が淡色表示される
-
機能カテゴリ:
- 仮想化 (VMX、SVM、ハイパーバイザー)
- 64 ビットサポート (EM64T、NX)
- 命令セット (SSE、AVX、AES など)
- 電源管理 (EIST、ACPI、サーマル)
- セキュリティ機能 (SMX、SKINIT)
- メモリ機能 (PAE、PAT、PSE)
- デバッグ機能と監視機能
表示される情報:
- 機能の略語
- 機能の状態 (サポート/サポートされていません)
- 完全な機能の説明 (詳細ウィンドウ)
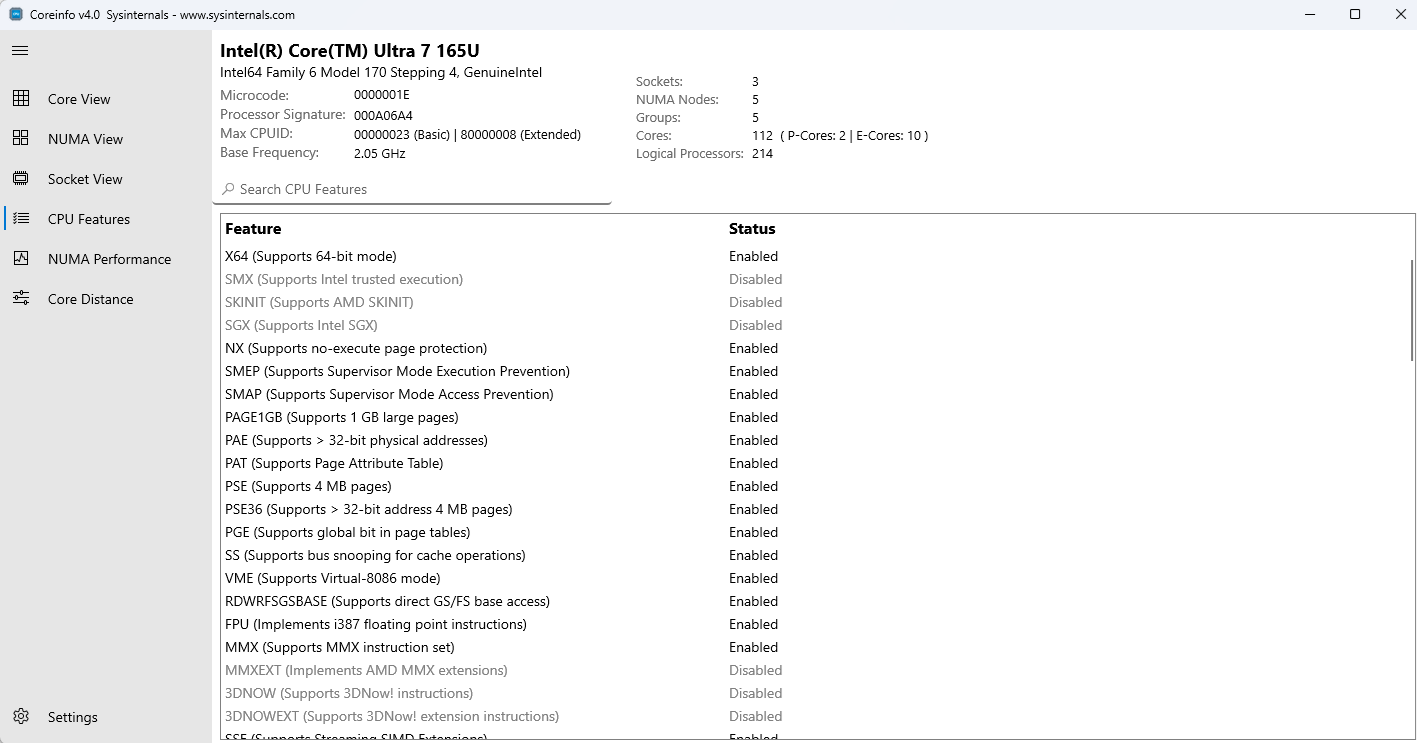 の一覧を示す CPU 機能ビュー CPU 機能ビュー
の一覧を示す CPU 機能ビュー CPU 機能ビュー
メモ: 一部の仮想化機能 (VMX、SVM など) は、ハイパーバイザーがアクティブな状態で実行されている場合、または仮想マシン内から実行されている場合に、誤って使用できないと報告されることがあります。 正確な結果を得るには、ハイパーバイザーが実行されていないシステムで Coreinfo を実行する必要があります。
ユースケース:
- アプリケーションをデプロイする前の命令セットの可用性の確認
- 仮想化のサポートの確認
- プロセッサの生成と機能について
- 不足している CPU 機能に関連するパフォーマンスの問題のデバッグ
5. NUMA パフォーマンス ビュー
NUMA パフォーマンス ビューは、NUMA ノード間のメモリ アクセス コストを示すグリッド視覚化を提供し、NUMA システムのパフォーマンスのボトルネックを特定するのに役立ちます。
機能:
- グリッドの視覚化: NUMA ノード間の相対的なメモリ アクセス コストを表示するマトリックス
- 対話型マトリックス: セルの上にマウス ポインターを合わせると、パフォーマンスに関する詳細な情報が表示されます
- Real-Time 更新: [更新] ボタンを選択してパフォーマンス データを動的に更新する
- 相対コスト表示: 異なる NUMA ノードからメモリにアクセスするための相対的なコストを示します
表示される情報:
- NxN 行列 (N = NUMA ノードの数)
- ソース NUMA ノード (行) から宛先 NUMA ノード (列) へのメモリ アクセス コスト
- 相対的なパフォーマンス コストを示す数値
- 対角線セルにローカル メモリ アクセスが表示される (通常はコストが最も低い)
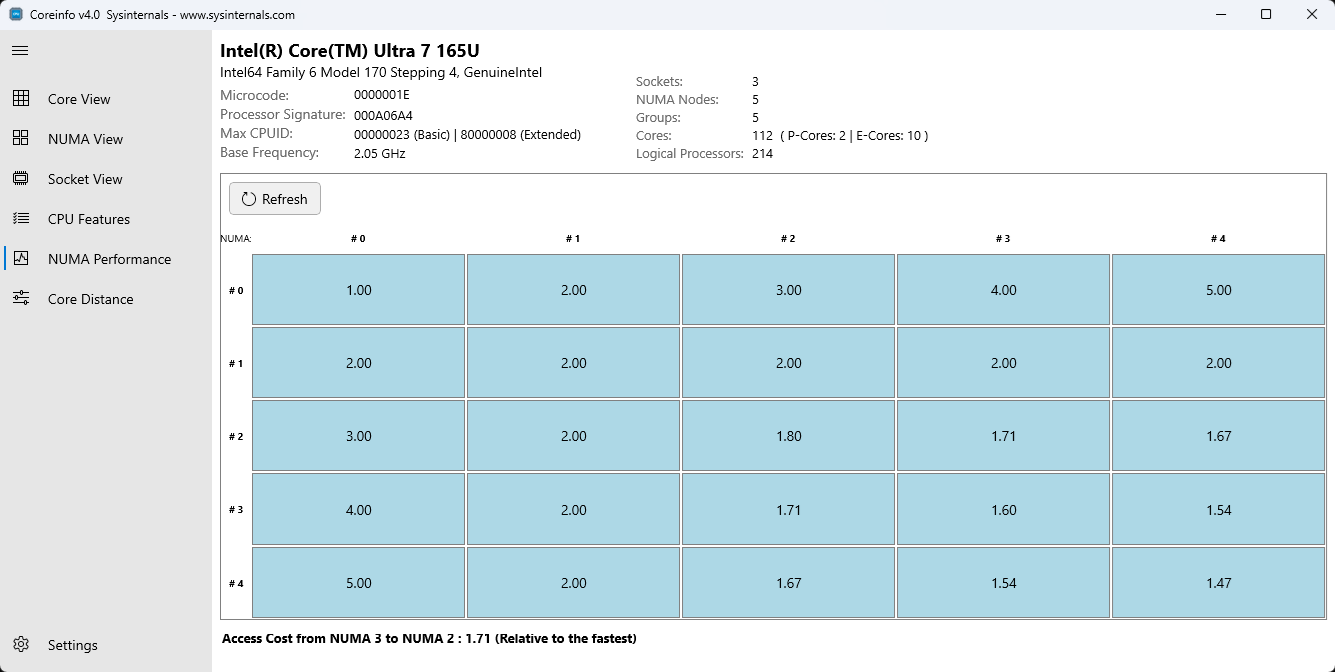 NUMAパフォーマンスグリッドがメモリアクセスコストを示します
NUMAパフォーマンスグリッドがメモリアクセスコストを示します
グリッドについて:
- 対角線要素: ローカル メモリ アクセス (独自のメモリにアクセスするノード) を表します。通常は最小値です
- 対角線以外の要素: 相対的なコストが高いリモート メモリ アクセスを表します
- 対称性: アクセス コストは方向によって異なる可能性があるため、マトリックスが完全に対称でない場合があります
ユースケース:
- NUMA 関連のパフォーマンスのボトルネックの特定
- メモリ割り当て戦略の最適化
- NUMA システムのプロセス/スレッドのピン留めを計画する
- クロスノード メモリ アクセスのペナルティについて
6. コア距離ビュー
コア距離ビューには、個々の CPU コア間の通信コストの詳細なヒート マップが表示され、コアからコアへの待機時間と通信効率に関する分析情報が提供されます。
機能:
-
Core-Level ヒート マップ: コア間の相対距離を示す色分けされたマトリックス
- 緑/青 = 待機時間が短い (同じコア クラスター、共有キャッシュ)
- 黄/オレンジ = 中待機時間 (同じソケット、異なるクラスター)
- 赤 = 待機時間が長い (異なるソケットまたは NUMA ノード)
- 対話型探索: グリッド キャンバスにカーソルを合わせると、詳細な距離情報が表示されます
- 詳細な分析: コアとコアの関係を最も細かく表示します
- 動的更新: 更新ボタンを使用して更新されたコア距離データを動的に取得する
表示される情報:
- NxN 行列 (N = 論理プロセッサの数)
- ソース コア (行) から宛先コア (列) までの相対距離/待機時間
- コア リレーションシップを視覚的に簡単に識別するための色分け
- 詳細ウィンドウの詳細距離メトリック
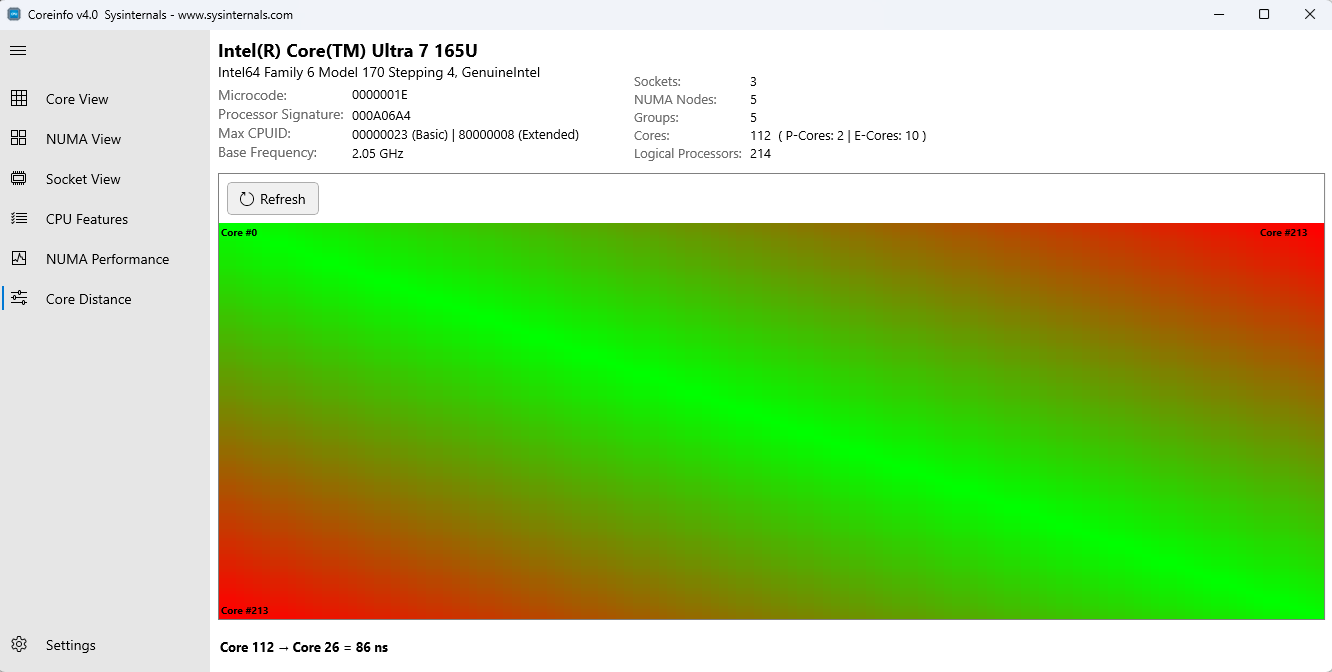 コア距離ヒートマップは、コア間通信コストを示します
コア距離ヒートマップは、コア間通信コストを示します
距離マップについて:
- 対角要素: 常にゼロ (自身へのコア)
- 低距離 (緑): コア共有 L2 または L3 キャッシュ
- 中距離 (黄色): 同じソケット上のコアだが異なるキャッシュドメイン
- 高距離 (赤): 異なるソケットまたは NUMA ノード上のコア
ユースケース:
- スレッド アフィニティの最適化
- キャッシュの一貫性ドメインについて
- スレッドを通信するための最適なコア ペアの識別
- マルチスレッド アプリケーションのパフォーマンスの分析
- 待機時間の短いアプリケーションの CPU ピン留め戦略の計画
対話型機能
コアの選択と詳細
任意のビュー (コア、NUMA、またはソケット) でコアをクリックすると、下部の詳細ウィンドウに詳細情報が表示されます。
- プロセッサ情報: 論理プロセッサ番号、マスク、アフィニティ
-
キャッシュ階層:
- L1 データ キャッシュ (サイズ、結合規則、行サイズ)
- L1 命令キャッシュ (サイズ、結合規則、行サイズ)
- L2 キャッシュ (サイズ、結合規則、行サイズ)
- L3 キャッシュ (サイズ、結合規則、行サイズ)
- トポロジ情報: NUMA ノード、ソケット、およびグループの割り当て
- コアの種類: P-Core、E-Core、または標準コアの指定
検索機能
CPU 機能ビューには、特定のプロセッサ機能をすばやく検索できる検索バーが含まれています。
- 検索アイコンをクリックする
- 機能名または省略形を入力します
- 一覧は自動的にフィルター処理され、一致する機能が表示されます
- 検索をクリアして完全なリストを復元する
キャッシュ マップの切り替え
コア ビューで、次の 2 つの視覚化モードを切り替えます。
- 既定のモード: 論理配置のコアを表示します
- キャッシュ マップ モード: コアを再構成してキャッシュ共有リレーションシップを視覚化する
ビュー間でのナビゲーション
- 左側のナビゲーション ウィンドウを使用してビューを切り替える
- 特定の NUMA ノードまたはソケットを表示すると、同じビューをもう一度クリックすると、全体ビューに戻ります
- ナビゲーション ウィンドウで現在のビューが強調表示されている
設定とカスタマイズ
ナビゲーション メニューの [設定] オプションを使用して設定にアクセスします。
外観の設定
テーマのオプション:
- ライト:明るい環境のために最大限に活用されるライト配色
- 濃色: 目の歪みを軽減する濃色配色
- システムの既定値: Windows テーマの設定に自動的に一致する
ファイルに保存
コア トポロジ データのエクスポート:
- [ 保存先 ] オプションを使用してコア トポロジ データをファイルにダンプする
- 出力形式は、コマンド ライン ツールの出力と同じです
システム トポロジについて
コアの種類 (ハイブリッド アーキテクチャ)
最新の CPU には、コアの種類が異なるハイブリッド アーキテクチャが搭載されている場合があります。
- P コア (パフォーマンス):シングルスレッドで要求の厳しいワークロード向けに最適化された高パフォーマンス コア
- E コア (効率):バックグラウンド タスクとマルチスレッド ワークロード向けに最適化されたエネルギー効率の高いコア
Coreinfo UI は、該当するすべてのビューでこれらのコア型を明確に識別し、区別します。
NUMA アーキテクチャ
NUMA とは 非均一メモリ アクセス (NUMA) は、各プロセッサが迅速にアクセスできるローカル メモリと、プロセッサ間通信を必要とするリモート メモリを備えるメモリ設計です。
重要な理由:
- ローカル メモリ アクセスは、リモート アクセスよりも大幅に高速です
- アプリケーションのパフォーマンスは、NUMA の配置によって大幅に影響を受ける可能性があります
- NUMA トポロジを理解することは、ハイ パフォーマンス コンピューティングに不可欠です
NUMA 最適化に Coreinfo UI を使用する:
- NUMA ビューを使用してシステムの NUMA トポロジを理解する
- NUMA パフォーマンス ビューでメモリ アクセス コストを確認する
- NUMA ノードの割り当てに基づいてスレッド/プロセスの配置を最適化する
- コア距離ビューを使用して、NUMA ノード内および NUMA ノード間のコア間通信を理解する
キャッシュ階層
キャッシュ レベル:
- L1 キャッシュ: 最小かつ最速、データキャッシュと命令キャッシュに分割
- L2 キャッシュ: 大規模な統合キャッシュ (通常は各コアに対してプライベート)
- L3 キャッシュ: 多くの場合、複数のコア間で共有される最大の統合キャッシュ
キャッシュ情報の使用:
- キャッシュ リソースを共有するコアを理解する
- キャッシュ共有コアのデータの局所性を最適化する
- コア ビューでキャッシュ マップ モードを使用してキャッシュ ドメインを視覚化する
コマンド ラインからの Coreinfo の使用
リソースごとに、指定されたリソースに対応する、OS に表示されるプロセッサのマップが表示され、該当するプロセッサを表す '*' が表示されます。 たとえば、4 コア システムでは、キャッシュ出力の行と、コア 3 と 4 で共有されるマップが含まれます。
使用法:
coreinfo [-c][-f][-g][-l][-n][-s][-m][-v]
| パラメーター | 説明 |
|---|---|
| -c | コアに関する情報をダンプします。 |
| -f | コア機能情報をダンプします。 |
| -g | グループに関する情報をダンプします。 |
| -l | キャッシュに関する情報をダンプします。 |
| -n | NUMA ノードに関する情報をダンプします。 |
| -s | ソケットに関する情報をダンプします。 |
| -m | NUMA アクセス コストに関する情報をダンプします。 |
| -v | 第 2 レベルのアドレス変換のサポートなど、仮想化関連の機能のみをダンプします。 (Intel システムに対する管理者権限が必要)。 |
既定では、 -v を除くすべてのオプションが選択されます。
Coreinfo の出力:
Coreinfo v4.0 - Dump information on system CPU and memory topology
Copyright © 2008-2025 Mark Russinovich
Sysinternals - www.sysinternals.com
Intel(R) Core(TM) Ultra 7 165U
Intel64 Family 6 Model 170 Stepping 4, GenuineIntel
Microcode signature: 0000001E
Processor signature: 000A06A4
Maximum implemented CPUID leaves: 00000023 (Basic), 80000008 (Extended).
Maximum implemented address width: 48 bits (virtual), 46 bits (physical).
HTT * Hyperthreading enabled
CET * Supports Control Flow Enforcement Technology
Kernel CET - Kernel-mode CET Enabled
User CET * User-mode CET Allowed
X64 * Supports 64-bit mode
SMX - Supports Intel trusted execution
SKINIT - Supports AMD SKINIT
SGX - Supports Intel SGX
NX * Supports no-execute page protection
SMEP * Supports Supervisor Mode Execution Prevention
SMAP * Supports Supervisor Mode Access Prevention
PAGE1GB * Supports 1 GB large pages
PAE * Supports > 32-bit physical addresses
PAT * Supports Page Attribute Table
PSE * Supports 4 MB pages
PSE36 * Supports > 32-bit address 4 MB pages
PGE * Supports global bit in page tables
SS * Supports bus snooping for cache operations
VME * Supports Virtual-8086 mode
RDWRFSGSBASE * Supports direct GS/FS base access
FPU * Implements i387 floating point instructions
MMX * Supports MMX instruction set
MMXEXT - Implements AMD MMX extensions
3DNOW - Supports 3DNow! instructions
3DNOWEXT - Supports 3DNow! extension instructions
SSE * Supports Streaming SIMD Extensions
SSE2 * Supports Streaming SIMD Extensions 2
SSE3 * Supports Streaming SIMD Extensions 3
SSSE3 * Supports Supplemental SIMD Extensions 3
SSE4a - Supports Streaming SIMDR Extensions 4a
SSE4.1 * Supports Streaming SIMD Extensions 4.1
SSE4.2 * Supports Streaming SIMD Extensions 4.2
AES * Supports AES extensions
AVX * Supports AVX instruction extensions
AVX2 * Supports AVX2 instruction extensions
AVX-512-F - Supports AVX-512 Foundation instructions
AVX-512-DQ - Supports AVX-512 double and quadword instructions
AVX-512-IFAMA - Supports AVX-512 integer Fused multiply-add instructions
AVX-512-PF - Supports AVX-512 prefetch instructions
AVX-512-ER - Supports AVX-512 exponential and reciprocal instructions
AVX-512-CD - Supports AVX-512 conflict detection instructions
AVX-512-BW - Supports AVX-512 byte and word instructions
AVX-512-VL - Supports AVX-512 vector length instructions
FMA * Supports FMA extensions using YMM state
MSR * Implements RDMSR/WRMSR instructions
MTRR * Supports Memory Type Range Registers
XSAVE * Supports XSAVE/XRSTOR instructions
OSXSAVE * Supports XSETBV/XGETBV instructions
RDRAND * Supports RDRAND instruction
RDSEED * Supports RDSEED instruction
CMOV * Supports CMOVcc instruction
CLFSH * Supports CLFLUSH instruction
CX8 * Supports compare and exchange 8-byte instructions
CX16 * Supports CMPXCHG16B instruction
BMI1 * Supports bit manipulation extensions 1
BMI2 * Supports bit manipulation extensions 2
ADX * Supports ADCX/ADOX instructions
DCA - Supports prefetch from memory-mapped device
F16C * Supports half-precision instruction
FXSR * Supports FXSAVE/FXSTOR instructions
FFXSR - Supports optimized FXSAVE/FSRSTOR instruction
MONITOR * Supports MONITOR and MWAIT instructions
MOVBE * Supports MOVBE instruction
ERMSB * Supports Enhanced REP MOVSB/STOSB
PCLMULDQ * Supports PCLMULDQ instruction
POPCNT * Supports POPCNT instruction
LZCNT * Supports LZCNT instruction
SEP * Supports fast system call instructions
LAHF-SAHF * Supports LAHF/SAHF instructions in 64-bit mode
HLE - Supports Hardware Lock Elision instructions
RTM - Supports Restricted Transactional Memory instructions
DE * Supports I/O breakpoints including CR4.DE
DTES64 - Can write history of 64-bit branch addresses
DS - Implements memory-resident debug buffer
DS-CPL - Supports Debug Store feature with CPL
PCID * Supports PCIDs and settable CR4.PCIDE
INVPCID * Supports INVPCID instruction
PDCM * Supports Performance Capabilities MSR
RDTSCP * Supports RDTSCP instruction
TSC * Supports RDTSC instruction
TSC-DEADLINE * Local APIC supports one-shot deadline timer
TSC-INVARIANT * TSC runs at constant rate
xTPR * Supports disabling task priority messages
EIST * Supports Enhanced Intel Speedstep
ACPI * Implements MSR for power management
TM * Implements thermal monitor circuitry
TM2 * Implements Thermal Monitor 2 control
APIC * Implements software-accessible local APIC
x2APIC * Supports x2APIC
CNXT-ID - L1 data cache mode adaptive or BIOS
MCE * Supports Machine Check, INT18 and CR4.MCE
MCA * Implements Machine Check Architecture
PBE * Supports use of FERR#/PBE# pin
PSN - Implements 96-bit processor serial number
HTT * Hyperthreading
PREFETCHW * PrefetchW instruction support
HYPERVISOR * Hypervisor is present
VMX - Supports Intel hardware-assisted virtualization
EPT - Supports Intel extended page tables (SLAT)
URG - Supports Intel unrestricted guest
Logical to Physical Processor Map:
**------------ Physical Processor 0 (Hyperthreaded)
--*----------- Physical Processor 1
---*---------- Physical Processor 2
----*--------- Physical Processor 3
-----*-------- Physical Processor 4
------*------- Physical Processor 5
-------*------ Physical Processor 6
--------*----- Physical Processor 7
---------*---- Physical Processor 8
----------**-- Physical Processor 9 (Hyperthreaded)
------------*- Physical Processor 10
-------------* Physical Processor 11
Logical Processor to Socket Map:
************** Socket 0
Logical Processor to NUMA Node Map:
************** NUMA Node 0
No NUMA nodes.
Logical Processor to Cache Map:
**------------ Data Cache 0, Level 1, 48 KB, Assoc 12, LineSize 64
**------------ Instruction Cache 0, Level 1, 64 KB, Assoc 16, LineSize 64
**------------ Unified Cache 0, Level 2, 2 MB, Assoc 16, LineSize 64
************-- Unified Cache 1, Level 3, 12 MB, Assoc 12, LineSize 64
--*----------- Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--*----------- Instruction Cache 1, Level 1, 64 KB, Assoc 8, LineSize 64
--****-------- Unified Cache 2, Level 2, 2 MB, Assoc 16, LineSize 64
---*---------- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
---*---------- Instruction Cache 2, Level 1, 64 KB, Assoc 8, LineSize 64
----*--------- Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
----*--------- Instruction Cache 3, Level 1, 64 KB, Assoc 8, LineSize 64
-----*-------- Data Cache 4, Level 1, 32 KB, Assoc 8, LineSize 64
-----*-------- Instruction Cache 4, Level 1, 64 KB, Assoc 8, LineSize 64
------*------- Data Cache 5, Level 1, 32 KB, Assoc 8, LineSize 64
------*------- Instruction Cache 5, Level 1, 64 KB, Assoc 8, LineSize 64
------****---- Unified Cache 3, Level 2, 2 MB, Assoc 16, LineSize 64
-------*------ Data Cache 6, Level 1, 32 KB, Assoc 8, LineSize 64
-------*------ Instruction Cache 6, Level 1, 64 KB, Assoc 8, LineSize 64
--------*----- Data Cache 7, Level 1, 32 KB, Assoc 8, LineSize 64
--------*----- Instruction Cache 7, Level 1, 64 KB, Assoc 8, LineSize 64
---------*---- Data Cache 8, Level 1, 32 KB, Assoc 8, LineSize 64
---------*---- Instruction Cache 8, Level 1, 64 KB, Assoc 8, LineSize 64
----------**-- Data Cache 9, Level 1, 48 KB, Assoc 12, LineSize 64
----------**-- Instruction Cache 9, Level 1, 64 KB, Assoc 16, LineSize 64
----------**-- Unified Cache 4, Level 2, 2 MB, Assoc 16, LineSize 64
------------*- Data Cache 10, Level 1, 32 KB, Assoc 8, LineSize 64
------------*- Instruction Cache 10, Level 1, 64 KB, Assoc 8, LineSize 64
------------** Unified Cache 5, Level 2, 2 MB, Assoc 16, LineSize 64
-------------* Data Cache 11, Level 1, 32 KB, Assoc 8, LineSize 64
-------------* Instruction Cache 11, Level 1, 64 KB, Assoc 8, LineSize 64
Logical Processor to Group Map:
************** Group 0
Coreinfo(3 MB)今すぐSysinternals Live から実行します。
以下で実行されます。
- クライアント: Windows 11 以降。
- サーバー: Windows Server 2016 以降。