抽出された情報をナレッジ ストアに保持する
ヒント
詳細については、「 テキストと画像 」タブを参照してください。
インデックスはインデックス作成プロセスの主な出力と見なせますが、それに含まれるエンリッチされたデータも他の方法で役立てることができます。 例えば次が挙げられます。
- インデックスは基本的に、インデックス付きレコードを表す JSON オブジェクトのコレクションであるため、抽出、変換、読み込み (ETL) 操作のデータ オーケストレーション プロセスに統合するための JSON ファイルとしてオブジェクトをエクスポートすると便利な場合があります。
- 分析とレポートのために、インデックス レコードをテーブルのリレーショナル スキーマに正規化することができます。
- インデックス作成プロセスでは埋め込み画像をドキュメントから抽出するので、それらの画像をファイルとして保存することもできます。
Azure AI 検索は、エンリッチメント パイプラインをカプセル化するスキルセットで "ナレッジ ストア" を定義できるようにすることで、このようなシナリオをサポートしています。 ナレッジ ストアは、エンリッチされたデータの "プロジェクション" で構成されています。これは、JSON オブジェクト、テーブル、画像ファイルのいずれかです。 インデクサーでパイプラインが実行されて、インデックスが作成または更新されると、プロジェクションが生成され、ナレッジ ストアに保持されます。
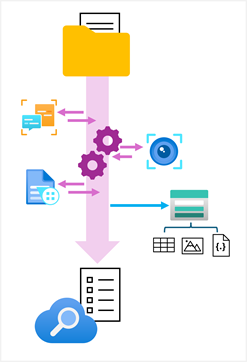
ヒント
ナレッジ ストアの使用の詳細については、 Azure AI 検索 ドキュメントの Azure AI 検索 のナレッジ ストア を参照してください。