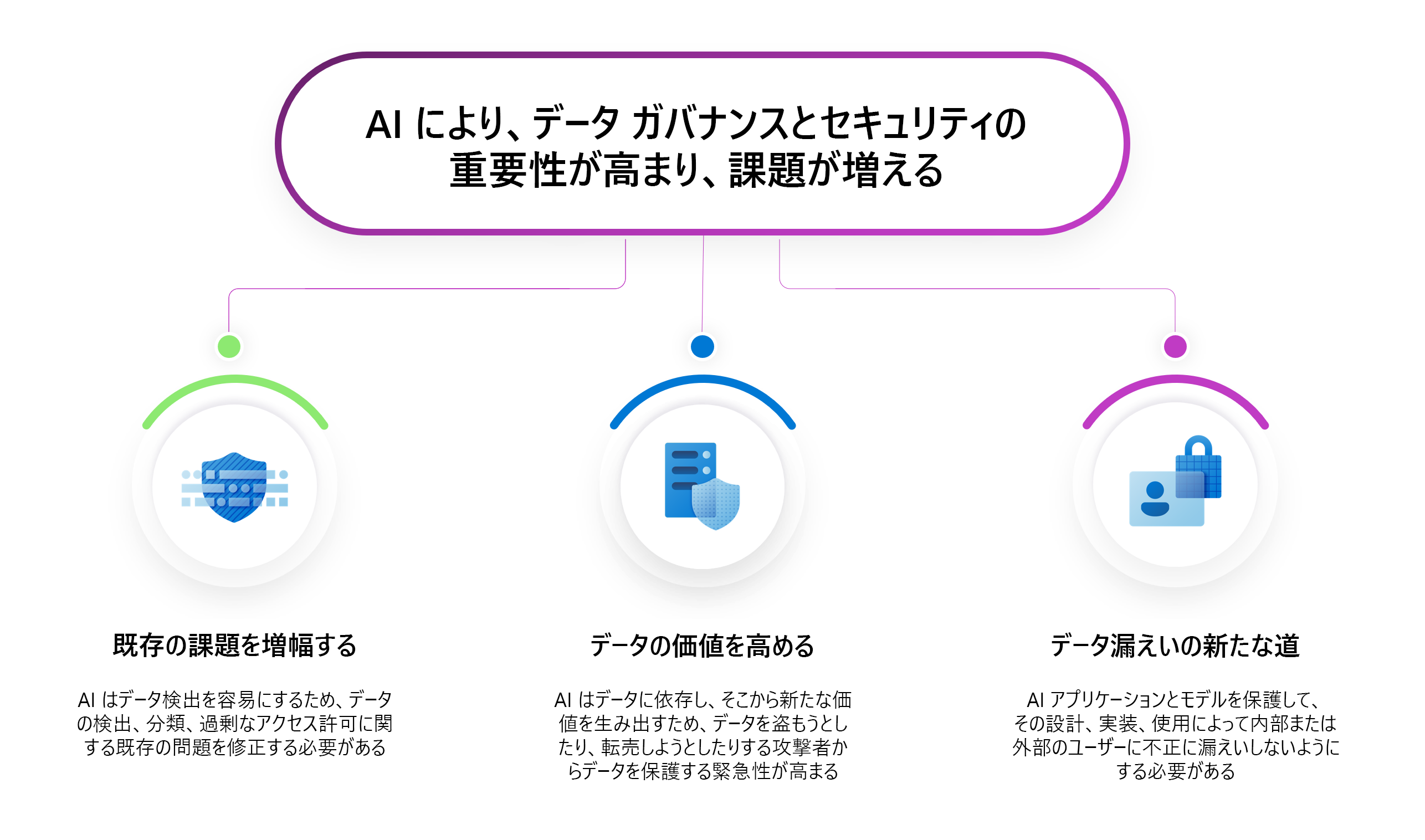
AI データ セキュリティを実装する
AI システムは、データの分類、アクセス許可、ガバナンスによって既存の課題を増幅するため、AI にとってデータ セキュリティは重要です。 AI を使用すると、データの検出が容易になります。つまり、データ処理に関する問題が拡大され、データ漏えいや不正アクセスが発生する可能性があります。 AI はデータに依存するだけでなく、時間の経過とともに価値を得る新しいデータを作成し、攻撃者のターゲットにしています。 データ セキュリティは新しい分野ではありませんが、AI によってデータ セキュリティを正しく確保することがさらに重要になります。
AI データ セキュリティの基本的な原則は、 アクセス制御の決定を AI システムにデボルブしてはならないということです。 AI は、ユーザーの代理として機能しているのと同じデータにのみアクセスできる必要があります。
AI システムのデータランドスケープを理解する
生成 AI システムは、保護を必要とするさまざまなデータ型と対話します。
- トレーニング データ: モデルの構築と微調整に使用されるデータセット。このデータセットには、独自の情報、個人データ、または著作権で保護された資料が含まれている可能性があります
- グラウンド データ: AI が取得拡張生成 (RAG) などの手法を使用して実行時に取得するドキュメント、データベース、ナレッジ ベース
- 相互作用データ: ユーザー プロンプト、モデル応答、会話履歴、使用中に生成されたツール呼び出しペイロード
- 生成された出力: 概要、コード、レポート、および AI によって作成されるその他の成果物。複数の機密ソースからの情報を組み合わせることがあります
各データ型には、異なるセキュリティ要件、アクセス パターン、規制への影響があります。 包括的な AI データ セキュリティ戦略は、それらすべてに対処します。
生成AIが使用するデータの種類を示したスクリーンショットで、消費、作成、アクセスされたデータのカテゴリが含まれています。
エージェント ID を使用してアクセス制御を実装する
AI が代理として機能するユーザーと同じデータにのみアクセスする必要があるという原則は、簡単に状態を示しますが、それを実装するには専用の ID 管理が必要です。 エージェント ID フレームワークは、AI エージェントを管理、認証、承認するための標準化された方法を提供します。
エージェント ID フレームワークでは、通常、次の 2 つの認証モードがサポートされます。
- 委任されたアクセス (ユーザーに代わって): エージェントは、代理フローを使用して、サインインしているユーザーの ID で動作します。 エージェントは、ユーザーが同意し、承認されているアクセス許可のみを継承します。 これにより、AI がユーザーがアクセスできないデータにアクセスできないという原則が直接適用されます。
- アプリケーションのみのアクセス: エージェントは、独自のロールの割り当てによって管理される、独自の専用 ID の下で動作します。 このモードは、ユーザーが関与しないバックグラウンドワークフローまたは無人ワークフローに使用されます。
最新の AI プラットフォームでエージェントを作成すると、サービスはエージェント ID を自動的にプロビジョニングできます。 その後、管理者はロールベースのアクセス制御 (RBAC) を使用してその ID にロールを割り当て、エージェント レベルで最小限の特権アクセスを適用します。これは、作成した人間の開発者のアクセス許可とは別です。
この分離は監査容易性の問題です。AI エージェントによって実行された操作は、人間のユーザーのアカウントではなく、エージェントの ID の下のログに表示されるため、予期しないエージェントの動作を検出して調査できます。
たとえば、Microsoft Entra エージェント IDは、委任されたアクセス モードとアプリケーション専用アクセス モードの両方をサポートする AI エージェントの専用 ID を発行し、ロールの割り当てを Azure RBAC で管理することで、この機能を提供します。

データの分類とガバナンス
効果的な AI データ セキュリティには、強力なデータ ガバナンス プラクティスも必要です。
- AI がアクセスする前にデータを分類する: AI システムによってアクセスされるデータが、その秘密度レベルに従って分類およびラベル付けされていることを確認します。 AI は、存在するアクセス制御のみを適用できます。データが適切に分類されていない場合、AI は承認されていないユーザーに機密情報を表示する可能性があります。
- データ損失防止 (DLP) ポリシーを適用する: 既存の DLP ポリシーを拡張して、AI 対話チャネルをカバーします。 AI プロンプト、応答、ツール呼び出しペイロードに表示される機密データを監視します。
- 保持ポリシーと削除ポリシーを適用する: 対話データ (会話ログ、プロンプト履歴) を保持する期間を定義します。 不要になったデータを自動的に消去して、露出の期間を最小限に抑えます。
- 監査データ アクセス パターン: AI がアクセスするデータ、いつ、誰に代わってアクセスするかを監視します。 エージェントが通常のスコープ外の大量のデータに突然クエリを実行するなど、異常なアクセス パターンは、侵害を示している可能性があります。