Azure OpenAI サービスを使用して埋め込みを生成する
ベクトル (埋め込み、またはベクトル埋め込みとも呼ばれます) は、高次元空間でのデータの数学的表現です。 各ディメンションは、この空間内のデータの特徴に対応しており、高度なデータを表すために何万ものディメンションが使用される場合があります。 この空間内のベクトルの位置は、その特性を表します。 単語、フレーズ、またはドキュメント全体、画像、オーディオ、その他の種類のデータはすべてベクター化できます。 データはベクターとして表されるため、ベクター検索では、異なるデータ型間で一致するデータを識別できます。
埋め込みは、機械学習モデルとアルゴリズムが効率的に利用できるデータ表現形式です。 埋め込みは、テキストの一部分のセマンティックな意味を高い情報密度で表現したものです。 各埋め込みは、浮動小数点数のベクトルです。 したがって、ベクター空間内の 2 つの埋め込みの間の距離は、元の形式の 2 つの入力間のセマンティック類似性と相関します。
Azure OpenAI を使用して埋め込みを生成する
Azure OpenAI は、OpenAI の高度な言語モデルを Microsoft の Azure プラットフォームと統合する最先端のサービスであり、開発者向けにセキュリティで保護されたスケーラブルな環境を提供します。 この強力な組み合わせにより、自然言語処理、テキスト要約、感情分析などのタスクに不可欠な、人間のようなテキストを理解して生成できるインテリジェントなアプリケーションを作成できます。 Azure OpenAI の基本的なアプリケーションは、複雑なクエリを処理し、パーソナライズされた応答を提供し、他のサービスとシームレスに統合できる、高度な仮想アシスタント (Generative AI アプリケーション) を構築することです。 埋め込みモデルを使用することで、開発者はテキスト データのベクター表現を生成し、Azure Cosmos DB for NoSQL などのベクター ストアに格納できます。 このアプローチにより、効率的で正確な類似性検索が容易になり、関連する情報を取得し、コンテキストに応じて豊富な対話を提供する Generative AI アプリケーションの機能が大幅に強化されます。
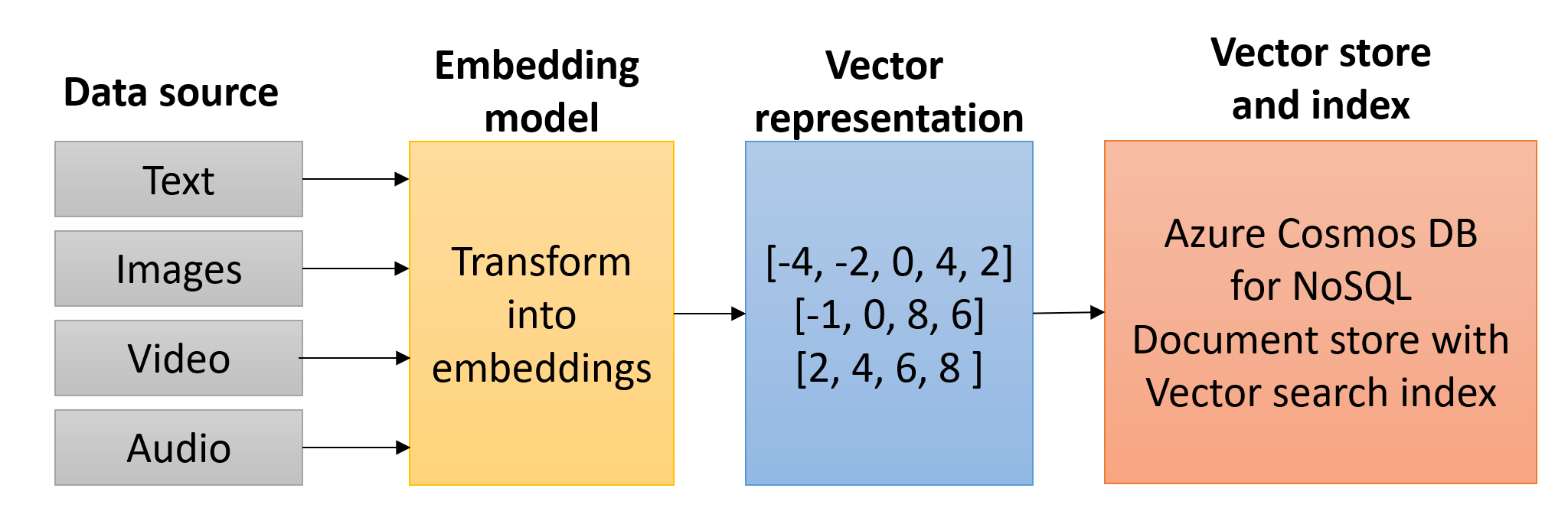
埋め込みは、データを埋め込みモデルに送信することによって生成され、そこでベクターに変換されます。 Azure OpenAI には、 text-embedding-ada-002、 text-embedding-3-small、 text-embedding-3-large モデルなど、埋め込みを作成するためのモデルがいくつか用意されています。 Azure OpenAI SDK for Python を使用して、埋め込みを生成する方法を提供する Azure OpenAI クライアントを作成できます。
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
from openai import AzureOpenAI
# Enable Microsoft Entra ID RBAC authentication
credential = DefaultAzureCredential()
token_provider = get_bearer_token_provider(
credential,
"https://cognitiveservices.azure.com/.default"
)
# Instantiate an Azure OpenAI client
client = AzureOpenAI(
api_version = AZURE_OPENAI_API_VERSION,
azure_endpoint = AZURE_OPENAI_ENDPOINT,
azure_ad_token_provider = token_provider
)
# Generate embeddings for input text
response = client.embeddings.create(
input = "Build Generative AI applications with Python and Azure Cosmos DB for NoSQL",
model = "text-embedding-3-large"
)
# Retrieve the generated embedding
embedding = response.data[0].embedding
モデルによって生成されるディメンションの数を把握することは、Azure Cosmos DB for NoSQL でコンテナー ベクター ポリシーを定義する際に重要です。 また、適切なベクター インデックス作成ポリシーを選択する際にも役割を果たします。 作成されるベクトルの次元は、生成に使用されるモデルによって決まります。 前の例では、 text-embedding-3-large モデルが使用されました。既定では、3,072 次元を含むベクターが作成されています。 コンテナー ベクター ポリシーを定義する場合は、 Dimensions プロパティでその数値を指定する必要があります。 同様に、使用されるディメンションの数をサポートするインデックスの種類を選択する必要があります。
作成後、埋め込みをベクター データベース (Azure Cosmos DB for NoSQL など) に格納できます。
ベクターを生成および格納するための一般的な開発パターン
ベクター埋め込みを生成して格納するために Azure OpenAI と Azure Cosmos DB for NoSQL を統合するには、通常、効率、リアルタイム処理、シームレスな統合を保証する自動化されたワーカー プロセスが必要です。 この統合を実現するために使用される一般的なパターンには、次のようなものがあります。
Cosmos DB 変更フィード トリガーを使用した Azure 関数
データが Cosmos DB に挿入されるときに埋め込みを生成するための効果的なパターンには、Cosmos DB 変更フィードと組み合わせて Azure 関数を使用することが含まれます。 コンテナーにドキュメントが挿入または更新されると、関数の Cosmos DB トリガーが呼び出されます。 この関数は、Azure OpenAI 埋め込みモデルを呼び出してベクターを作成し、これらの埋め込みでドキュメントを更新し、Cosmos DB に書き戻します。 このアプローチにより、リアルタイム処理と、後続の検索のためのベクター埋め込みの即時可用性が保証されます。
Azure Data Factory を使用したバッチ処理
バッチ処理は、ドキュメントが Cosmos DB コンテナーに既に存在しているか、別のデータ ストアに存在しているかに関係なく、ドキュメントに対する一括データ操作の効率的なアプローチです。 Azure Data Factory を使用して、ベクター埋め込みを生成するプロセスを調整できます。 Data Factory では、ソースからデータを抽出し、それを Azure OpenAI に送信して生成を埋め込み、エンリッチされたデータを Cosmos DB に書き込むことができます。 この方法は、リアルタイム処理が重要でない初期データ読み込みまたは定期的な更新に役立ちます。
マイクロサービス アーキテクチャ
マイクロサービス アーキテクチャでは、関連するプロセスをより細かく制御できるソリューションを提供できます。 埋め込み生成は、専用マイクロサービス内にカプセル化できます。 このサービスは Azure OpenAI および Cosmos DB と対話し、必要に応じてベクター埋め込みを生成します。 他のサービスでは、埋め込みを更新または取得する必要があるときにいつでもこのマイクロサービスを呼び出すことができます。これにより、モジュール式で保守可能なシステム設計が保証されます。
これらのパターンを採用することで、アプリケーションは、Azure OpenAI と Cosmos DB for NoSQL の機能を使用して、ベクター埋め込みを効率的に統合して、検索とデータ分析を強化できます。