分散プログラミングを使用する理由は何ですか?
アルゴリズム レベルとコード レベルのさまざまな分析手法で逐次プログラムでありうる並列処理を特定できます1。原則として、逐次プログラムはすべて並列化できます。 その後、1 つのプログラムを図 3 のように直列部分と並列部分に分割できます。 並列部分は 1 台のコンピューターで同時実行するか、コンピューター間で分散できます。 プログラマは通常、主に計算速度やスループットを上げる目的で、逐次プログラムをその並列版に変換します。 理想の世界があるとすれば、逐次プログラムを n 個の分散プログラムに並列化し、実行時間を n 分の 1 に短縮するでしょう。 逐次プログラムではなく分散プログラムの使用が重要となる分野もあります。特に科学です。 たとえば、1 個のタンパク質の折りたたみをシミュレーションするとき、逐次の場合は数年かかりますが、並列で実行すれば数日だけです。 分野によっては科学的発見のペースは、特定の科学的問題を解決する時間の短さにかかっています。 また、一部のプログラムにはリアルタイムの制約があり、一定の時間内に計算できないと、プログラム全体が無意味になることがあります。 たとえば、天候モデリングを利用して竜巻や暴風の方向を予測するとき、速やかに実行しなければ予測が無駄になります。 実際、科学者やエンジニアは、ごく一部のみ挙げると量子力学、物理シミュレーション、天気予報、石油とガスの踏査、分子モデリングなど、重要で複雑な科学的問題を解決するため、長い間、分散プログラムに頼ってきました。 この傾向は少なくとも当面はおそらく続くでしょう。
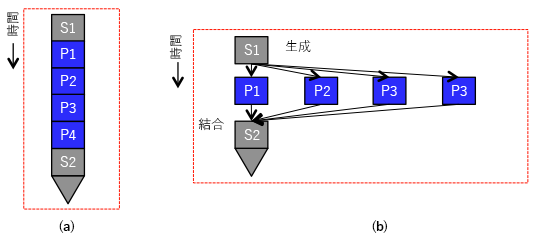
図 3: (a) 直列 (S1) 部分と並列 (P1) 部分からなる逐次プログラム。 (b) (a) の逐次プログラムに対応する並列または分散プログラム。並列部分はコンピューター間で分散するか、1 台のコンピューターで同時実行できます。
分散プログラムには、検索エンジン、Web サーバー、データベースなど、科学を超えた幅広い用途もあります。 1 つの例として、Folding@Home プロジェクトがあります。この場合は、スーパー コンピューターから個人用の PC まで、あらゆる種類のシステム上で分散コンピューティングを使用して、タンパク質動力学の分子動力学シミュレーションが実行されます。 並列化がなければ、Folding@Home では、ほぼ同数のコンピューティング リソースにアクセスすることは不可能でしょう。 たとえば、1 個の VM インスタンスで Hadoop MapReduce2 を実行することは、VM インスタンスの大規模クラスターでそれを実行することほど効果的ではありません。 もちろん、早い段階でジョブをクラウドに送るとコストの削減になり、それはクラウド利用者の重要な目標の 1 つです。
分散プログラムは、サブシステムのボトルネック緩和にも役立ちます。 たとえば、ディスクやネットワーク インターフェイス カードなど、出入力デバイスは通常、帯域幅、パフォーマンス、スループットの面で大きなボトルネックとなります。 コンピューター間で作業を分散することで、複数のディスクから同時にデータを提供できます。出入力の総帯域幅を増やし、パフォーマンスを改善し、スループットを最大まで上げます。 まとめると、分散プログラムは、計算処理に関連するさまざまな問題を短時間で解決し、リソース ボトルネックを効果的に軽減するために重要な役割を果たします。 この措置でパフォーマンスとスループットが上がり、特にクラウドにおいて、コストが下がります。
参考資料
- Y. Solihin (2009 年)。 「並列コンピューター アーキテクチャの基礎」 Solihin Books
- Apache Hadoop