クラウドのプログラミング モデル
- 13 分
大規模な計算システムを構築するときに、概念を具体化し、開発者をサポートするツールを提供するのがプログラミング モデルです。 特に、分散型のプログラミング モデルでは、逐次アルゴリズムから、分散システム上で実行できる分散プログラムへの変換を簡単に行うことができます。 モデルの設計によって、プログラマがどれだけ簡単にアルゴリズムを分散プログラムとして指定できるかが決まります。 簡単に使用できると考えられるモデルは、アーキテクチャやハードウェアの詳細を抽象化し、計算を自動的に並列化して分散し、フォールト トレランスを透過的にサポートするモデルです。
ただし、モデルの効率は、基になる手法の有効性に左右されます。 分散コンピューターから成るシステムで実行されている分散プログラムの場合、重要な要件が 1 つあります。それは、複数のネットワーク リソース間でコンポーネント タスクを調整できる通信メカニズムです。 メッセージ パッシングと共有メモリという 2 つの従来型のモデルは、比較的基本的な形式においてではありますが、このニーズを満たしています。 クラウド環境で一般的な分散プログラムにおけるその他の課題から、より高度なプログラミング モデルが生まれました。それは、分散型の分析エンジンとして実装することで、タスクを自動的に並列化して分散し、フォールト トレランスを実現できるモデルです。
共有メモリ モデル
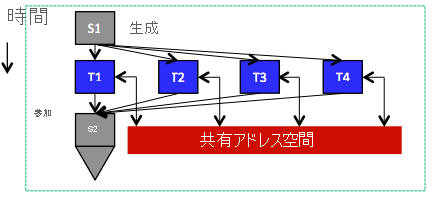
図 4: 並列で実行されてアドレス空間を共有しているタスク
共有メモリ モデルの主要な抽象化では、すべてのタスクから、アプリケーションの分散メモリ空間内の任意の場所にアクセスできるとしています。 したがって、タスクの通信は、分散メモリ空間のメモリ位置に対する読み取りと書き込みによって行われます。これは、すべてのスレッドがプロセスのアドレス空間を共有する (図 4)、単一プロセス内のスレッドの場合と同じです。 共有メモリを使用することで、タスク間のデータ交換は、明示的にメッセージを送受信することによってではなく、共有を通して暗黙的に行われます。 このため、共有メモリ モデルでは同期メカニズムがサポートされています。同期メカニズムは、さまざまなタスクでの読み取り操作や書き込み操作の実行順序を制御するために、分散プログラムで使用する必要があります。 特に、共有データの場所に複数のタスクから同時に書き込むことが可能であってはなりません。データが破損したり不整合になったりする可能性があるからです。 この目標は一般的に、セマフォ、ロック、またはバリアの 1 つ以上を使用して実現できます。 セマフォは、2 つの並列または分散タスクに対するポイントツーポイントの同期メカニズムです。 セマフォでは、post と wait という 2 つの操作が使用されます。 post は、トークンをデポジットするのと同様に動作し、データが生成されたことを通知する操作です。 wait は、データの使用を開始できることが post 操作によって通知されるまでブロックする操作です。 ロックによって、一度に 1 つのタスクのみがアクセス (通常は書き込み) できる領域であるクリティカル セクションが保護されます。 ロックには、クリティカル セクションに関連付けられているロックを取得および解放するための、ロックとロック解除という 2 つの操作があります。 ロックは一度に 1 つのタスクによってのみ保持され、他のタスクは、そのロックが解放されるまでロックを取得できません。 最後に、バリアとは、他のすべてのタスクがそのポイントに到達するまでタスクを続行できないポイントを定義するものです。 セマフォ、ロック、バリアの効率は、共有メモリ プログラミング モデルの分散または並列プログラムを開発する際の、重要かつ課題を伴う目標です。
図 5 に、共有メモリ プログラミング モデルを使用して単純な逐次プログラムを分散プログラムに変換する例を示します。 逐次プログラムは、b と c という 2 つの配列の要素を加算し、結果を配列 a に格納します。 その後、a の 0 より大きいすべての要素が総計に追加されます。 対応する分散バージョンでは、2 つのタスクのみが想定され、それらの間で作業が均等に分割されます。 すべてのタスクについて、(共有) 配列のインデックスを正しく作成し、データを取得して、指定されたアルゴリズムを適用するために、開始変数と終了変数が指定されます。 総計は明らかにクリティカル セクションであるため、ロックによって保護されます。 また、どのタスクも、他のすべてのタスクの作業が完了する前に総計を出力することはできないため、出力ステートメントの前にバリアが挿入されます。 プログラムに示されているように、2 つのタスク間の通信は (共有の配列と変数への読み取りと書き込みを使用して) 暗黙的に行われ、同期は (ロックとバリアによって) 明示的に行われます。 最後に、前に指摘したように、基になる分散システムによってデータ共有機能が提供されている必要があります。 具体的には、システム内のすべてのコンピューターのメモリが、すべてのタスクからアドレス指定できる 1 つの共有空間を形成しているという錯覚が、インフラストラクチャによって提供される必要があります。 (LAN によって接続された) コンピューターのクラスター上で、このような基になる共有 (仮想) アドレス空間を提供するシステムの一般的な例は、DSM と呼ばれます。1、2 DSM およびその他の分散共有システムで使用できる一般的なプログラミング言語は、OpenMP です。3

図 5: 逐次 (a) バージョンと共有メモリ (b) バージョン
メッセージ パッシング プログラミング モデル
メッセージ パッシング プログラミング モデルでは、分散タスクの通信はメッセージを送受信することによって行われます。 ここでは、分散タスクによって、互いのデータにアクセスできるアドレス空間は共有されません (図 6 を参照)。 主要な抽象化は、スレッドとは異なり、それぞれがプライベート メモリ空間を保持するプロセスに似ています。 このモデルでは、明示的なメッセージを使用してデータを送受信するために、通信のオーバーヘッドが発生します (たとえば、ネットワークの待ち時間が変動したり、データ転送が過剰になったりする可能性があります)。 これらのオーバーヘッドのバランスをとることで、明示的なメッセージ交換によって、通信を行うタスク間の操作の順序が暗黙的に同期されます。 図 7 は、図 5 (a) に示した逐次プログラムを、メッセージ パッシングを使用する分散バージョンに変換する例を示しています。 最初は、id = 0 のメイン タスクのみが配列 b と c にアクセスできます。 したがって、タスクが 2 つしか存在しない場合は、2 つのタスクの間で作業を均等に分割するために、メイン タスクが最初に配列の一部を (明示的な送信操作を使用して) 他のタスクに送信します。 2 番目のタスクでは、(明示的な受信操作を使用して) 必要なデータを受け取り、ローカルの合計を実行します。 ローカルの合計が終わると、2 番目のタスクがその合計をメイン タスクに送り返します。 同様に、メイン タスクがそのデータ部分に対してローカルの合計を実行し、他のタスクのローカルの合計を集計してから、総計を集計して印刷します。 このように、各送信操作には対応する受信操作があるため、明示的な同期は必要ありません。 最後に、メッセージ パッシング プログラミング モデルでは、基になる分散システムからのサポートは不要です。 具体的には、相互作用するタスクでは、共有アドレス空間を 1 つにする必要がありません。 メッセージ パッシング プログラミング モデルの一般的な例は、メッセージ パッシング インターフェイス (MPI) によって提供されます。4 MPI は、メッセージ パッシング プログラムを作成するための、業界標準のメッセージ パッシング ライブラリ (正確にはライブラリで実行できる内容を指定したもの) です。 高パフォーマンスで、幅広く移植可能な MPI の一般的な実装が MPICH です。5
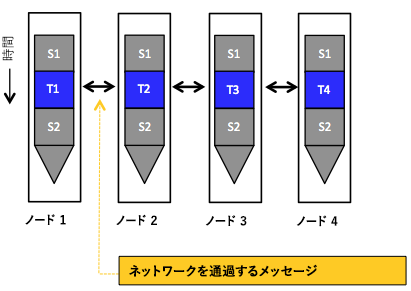
図 6: メッセージ パッシング プログラミング モデルを使用して並列で実行されるタスク。これにより、ネットワーク経由でメッセージを送受信するだけで相互作用が行われます
次の表では、開発作業、チューニング作業、通信、同期、ハードウェアのサポートという 5 つの側面から、共有メモリ モデルとメッセージ パッシング プログラミング モデルを比較しています。
共有メモリ プログラムは、データのレイアウトや伝達方法をプログラマが気にする必要がないため、最初は開発が簡単です。 さらに、共有メモリ プログラムのコード構造の多くは、それに対応するシーケンシャル プログラムのコード構造と非常によく似ています。 通常、プログラマは、並列または分散タスク、変数のスコープ、同期ポイントを指定するために、追加のディレクティブだけを挿入します。 これに対し、メッセージ パッシング プログラムでは、タスク間でデータをパーティション分割する方法、データを収集する方法、明示的なメッセージングを使用して結果を伝達および集計する方法を考えるように、プログラマの考え方を根本から切り替える必要があります。
データがどのようにレイアウトされ、どこに格納されるかは、データとリソースがスケールアップするにつれてパフォーマンスに大きく影響します。 たとえば、クラウドなどの大規模な分散システムでは、アクセスの遅延が均一ではありません (たとえば、リモート データへのアクセスはローカル データへのアクセスよりもはるかに時間がかかります)。そのため、プログラマには、データを、それが使用されるタスクの近くに保持することが推奨されます。 メッセージ パッシングのプログラマは、タスク間でデータをパーティション分割することを事前に計画する必要がありますが、共有メモリのプログラマは、通常はデータの移行やレプリケーションによって、開発後にイシューに対処することが多くなります。 この調整には、メッセージ パッシング設計と比較して、大きなチューニング作業が必要になる場合があります。
大規模なシステムでは、同期ポイントがパフォーマンスのボトルネックになる可能性があります。クリティカルなセクションにアクセスしようとしているユーザーの数が増えると、関連する遅延と待機も増加します。 今後のモジュールで、クラウドのプログラミングに関連する同期とその他の課題に戻ります。

図 7: 図 5 (a) のシーケンシャル プログラムに対応する、メッセージ パッシング プログラミング モデルを使用してコーディングされた分散プログラム
| 特徴 | 共有メモリ モデル | メッセージ パッシング モデル |
|---|---|---|
| 通信 | 暗黙 | 明示 |
| 同期 | 明示 | 暗黙 |
| ハードウェア サポート | 通常は必要 | 必要なし |
| 初期の開発作業 | 削減 | 増加 |
| スケール アップ時のチューニング作業 | 増加 | 削減 |
参考資料
- A. S. Tanenbaum (1994 年 9 月 4 日)。 「分散システム - 原理とパラダイム」 Prentice Hall、第 1 版
- K. Li (1986 年)。 「疎結合されたマルチプロセッサの共有仮想メモリ」 Yale University、New Haven、CT (USA)
- OpenMP
- メッセージ パッシング インターフェイス
- MPICH