同期計算と非同期計算
次の図は、バルク同期並列 (BSP) モデルを示しています。
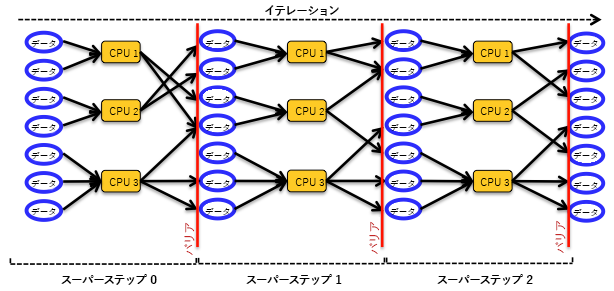
図 8:バルク同期並列モデル
開発者は、使用されているプログラミング モデルに関係なく、同期または非同期のいずれかとして分散計算を指定できます。 この区別は、タスクの操作を同期する (グローバルな) 調整メカニズムの有無を表します。 分散プログラムは、コンポーネント タスクがロックステップで動作する場合にのみ同期されます。 つまり、定数 $(c \geq 1)$ の場合、いずれかのタスクで $(c + 1)$ ステップが実行された場合にのみ、その他すべてのタスクで少なくとも $c$ ステップが実行されたことになります。1 その後、いずれかのタスクで $(c + 2)$ ステップが実行された場合、その他すべてのタスクでは少なくとも $(c + 1)$ ステップが実行されたはずです。 明らかに、この制約には、タスク アクティビティを同期してタイミングを適切に強制する調整メカニズムが必要です。 このようなメカニズムは通常、パフォーマンスに重要な影響を与えます。 一般的に同期プログラムでは、分散タスクは特定の計算が完了するまで、または特定のデータが到着するまで、事前に定義されたポイントで待機する必要があります。3 同期されないプログラムは、非同期プログラムです。 非同期プログラムでは、事前に定義されたポイントまたは特定のデータの到着を待機する必要がありません。 計算の非同期性は、明らかにパフォーマンスへの影響は比較的少ないですが、プログラムの正確性と有効性を評価する必要があることを意味します。
たとえば、MapReduce および Pregel プログラムには同期計算が含まれますが、GraphLab にあるプログラムは非同期です。 Pregel では、バルク同期並列 (BSP) モデル2 が採用されています。これは、分散プログラムを効果的に実装するために一般的に使用される同期モデルです。 BSP では、コンポーネント、ルーター、同期方法という 3 つの属性が組み合わされています。 BSP コンポーネントはプロセッサとローカル メモリの格納データで構成されますが、このモデルでは、その他の配置 (リモート メモリにデータを保持するなど) を除外していません。 BSP では、プロセッサ数は 2 個でも 100 万個でも、どちらでもかまいません。 また、BSP プログラムは、$(v > p)$ である場合に、$v$ 個の仮想分散プロセッサ用に記述して、$p$ 個の物理分散プロセッサ上で実行できます。
BSP は、メッセージ パッシング プログラミング モデルを基盤としており、ルーターを介してメッセージを送受信します。ルーターは原則として、コンポーネント ペア間のポイントツーポイントでのみ、メッセージを渡すことができます (このモデルでブロードキャスト機能は提供されませんが、開発者は複数のポイントツーポイント通信を使用してその機能を実装することができます)。同期を実現するために、BSP ではすべての計算をスーパーステップと呼ばれる一連のステップに分割します。 あらゆるスーパーステップ ($S$) において、(ローカル) 計算を含むタスクが各コンポーネントに割り当てられます。 $S$ 内のコンポーネントで、スーパーステップ $(S + 1)$ 内の $(c + 1)$ コンポーネントにメッセージを送信できます。また、スーパーステップ $(S-1)$ 内のコンポーネントからメッセージを受信することが暗黙的に許可されます。 すべてのスーパーステップで、タスクは同時に動作し、タスク間の相互通信は行われません。 複数のスーパーステップ全体で、タスクはロックステップ モードで進行します。$(S + 1)$ 内のタスクは、$S$ 内のすべてのタスクがコミットされる前に開始することはできません。 この条件を満たすために、BSP では図 8 に示すように、グローバルなバリア スタイルの同期メカニズムが適用されます。 BSP では単一のメモリ位置への同時アクセスが提供されないため、バリアを超えた同期メカニズムは必要ありません。
分散設定におけるもう 1 つの主な考慮事項は、個別のタスク間での不均一なメモリ アクセス待機時間や不均一な負荷によって計算が遅くならないように、データを割り当てることです。 BSP ではローカル データを使用してアクセス待機時間が均一になるようにします。データは、実際のタスクの計算をトリガーする前に、スーパーステップ間で伝達されます。そのため、このモデルでは計算と通信が切り離されます。 このような分離は、高スループットを実現するための要件以上に優先される特定のネットワーク トポロジはないことを示唆しています。 バタフライ、ハイパーキューブ、オプティカル クロスバーのすべてのトポロジを使用できます。
スーパーステップ内のタスク間では、データ ボリュームはまだ変化する可能性があり、タスクの読み込みは主に分散プログラムと、そのプログラムを構成するタスクに課せられる役割に依存します。 したがって、スーパーステップを完了するために必要な時間は、最も遅いタスクによって制約されます (最も遅いタスクが終了する前にスーパーステップをコミットすることはできません)。この制限は BSP モデルにとって大きな課題となります。この制限から負荷の不均衡が生じる可能性があり、それによって通常はパフォーマンスが低下するからです。 特にクラウド上で、異種クラスターによって負荷の不均衡が発生することもあります。 BSP では複数の設計の選択肢が提案されていますが、それらの使用が必須とされているわけではないことにご注意ください。 実際、BSP では多くの設計の選択肢が自由選択です (たとえば、バリアベースの同期でより細かい粒度で実装することも、特定のアプリケーションに対して不要な場合は完全にオフにすることもできます)。
関連項目
- A. S. Tanenbaum、M. V. Steen (2006 年 10 月 12 日)。 「分散システム: 原則とパラダイム」 Prentice Hall、第 2 版
- L. G. Valiant (1990 年)。 「並列計算のブリッジング モデル」 Communications of the ACM
- D. P. Bertsekas および J. N. Tsitsiklis (1997 年 1 月 1 日)。 Parallel and Distributed Computation: Numerical Methods (並列および分散計算: 数値メソッド) Athena Scientific、第 1 版