Speech to Text API を使用する
ヒント
詳細については、「 テキストと画像 」タブを参照してください。
Foundry Tools の Azure Speech では、Speech to text* API を使用した音声認識がサポートされています。 具体的な詳細は、使用されている SDK (Python、C# など) によって異なります。 音声テキスト 変換 API を使用するための一貫したパターンがあります。
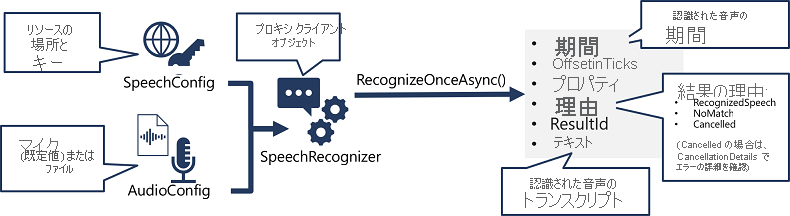
- SpeechConfig オブジェクトを使用して、Foundry リソースへの接続に必要な情報をカプセル化します。 具体的には、 そのエンドポイント (または リージョン) と キーです。
- 必要に応じて、AudioConfig を使用して、変換される音声の入力ソースを定義します。 既定では、これが既定のシステムのマイクですが、音声ファイルを指定することもできます。
- SpeechConfig と AudioConfig を使用して SpeechRecognizer オブジェクトを作成します。 このオブジェクトは、 Speech to Text API のプロキシ クライアントです。
- SpeechRecognizer オブジェクトのメソッドを使用して、基になる API 関数を呼び出します。 たとえば、 RecognizeOnceAsync() メソッドは、Azure Speech サービスを使用して、1 つの発話を非同期的に文字起こしします。
- 応答を処理します。
RecognizeOnceAsync() メソッドの場合、結果は次のプロパティを含む SpeechRecognitionResult オブジェクトになります。
- 期間
- OffsetInTicks
- プロパティ
- 理由
- ResultId
- テキスト
操作が成功した場合、 Reason プロパティには列挙値 RecognizedSpeech があり、 Text プロパティには文字起こしが含まれます。 Result に指定できるその他の値には、NoMatch (オーディオが正常に解析されたが、音声が認識されなかったことを示す) や Canceled (エラーが発生したことを示す値) があります (その場合は、CancellationReason プロパティの Properties コレクションを確認して、問題が発生したことを確認できます)。
例 - オーディオ ファイルの文字起こし
次の Python の例では、Foundry Tools の Azure Speech を使用して、オーディオ ファイルで音声を文字起こしします。
import azure.cognitiveservices.speech as speech_sdk
# Speech config encapsulates the connection to the resource
speech_config = speech_sdk.SpeechConfig(subscription="YOUR_FOUNDRY_KEY",
endpoint="YOUR_FOUNDRY_ENDPOINT")
# Audio config determines the audio stream source (defaults to system mic)
file_path = "audio.wav"
audio_config = speech_sdk.audio.AudioConfig(filename=file_path)
# Use a speech recognizer to transcribe the audio
speech_recognizer = speech_sdk.SpeechRecognizer(speech_config=speech_config,
audio_config=audio_config)
result = speech_recognizer.recognize_once_async().get()
# Did it succeeed
if result.reason == speech_sdk.ResultReason.RecognizedSpeech:
# Yes!
print(f"Transcription:\n{result.text}")
else:
# No. Try to determine why.
print("Error transcribing message: {}".format(result.reason))