ディープ ラーニングの概念について理解する
あなたの脳にはニューロンと呼ばれる神経細胞があり、電気化学信号をネットワーク経由で通過する神経拡張機能によって相互に接続されています。

ネットワーク内の最初のニューロンが刺激されると、入力信号が処理され、特定のしきい値を超えると、ニューロンが アクティブになり 、そのニューロンが接続されているニューロンにシグナルが渡されます。 これらのニューロンは、順番に活性化され、ネットワークの残りの部分を介して信号を渡すことができます. 時間の経過と同時に、ニューロン間の接続は、効果的に応答する方法を学習する際に頻繁に使用することで強化されます。 たとえば、ペンギンの画像が表示されている場合、ニューロン接続を使用すると、画像内の情報とペンギンの特性に関する知識を処理して、その情報を識別できます。 時間の経過とともに、さまざまな動物の複数の画像が表示されている場合、その特性に基づいて動物を識別することに関与するニューロンのネットワークが強くなります。 言い換えると、異なる動物を正確に識別する方が優れています。
ディープ ラーニングは、電気化学刺激ではなく数値入力を処理する人工ニューラル ネットワークを使用して、この生物学的プロセスをエミュレートします。
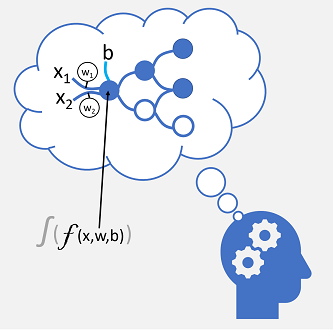
受信神経接続は、通常 x として識別される数値入力に置き換えられます。 複数の入力値がある場合、 x は x1、 x2 などの要素を持つベクトルと見なされます。
各 x 値に関連付けられる 重み (w) は、学習をシミュレートするために x 値の効果を強化または弱めるために使用されます。 さらに、 バイアス (b) 入力が追加され、ネットワークに対するきめ細かな制御が可能になります。 トレーニング プロセス中に、 w と b の値は、正しい出力を生成するために "学習" するようにネットワークを調整するように調整されます。
ニューロン自体は、 x、 w、 および b の加重合計を計算する関数をカプセル化します。 この関数は、結果 (多くの場合、0 から 1 の間の値) を制約して、ニューロンがネットワーク内のニューロンの次の層に出力を渡すかどうかを判断する 活性化関数 で囲まれます。
ディープ ラーニング モデルのトレーニング
ディープ ラーニング モデルは、複数 の層 の人工ニューロンで構成されるニューラル ネットワークです。 各レイヤーは、関連付けられた w 重みと b バイアスを持つ x 値に対して実行される関数のセットを表し、モデルが予測する y ラベルの出力に対する最終的なレイヤーの結果を表します。 分類モデル (入力データの最も可能性の高いカテゴリまたはクラスを予測する) の場合、出力は、可能な各クラスの確率を含むベクトルです。
次の図は、4 つの特徴 ( x 値) に基づいてデータ エンティティのクラスを予測するディープ ラーニング モデルを表しています。 モデルの出力 ( y 値) は、3 つの可能なクラス ラベルのそれぞれに対する確率です。
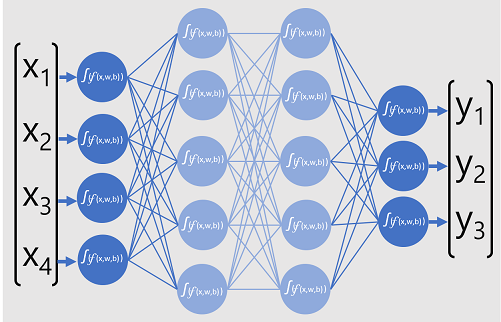
モデルをトレーニングするために、ディープ ラーニング フレームワークは入力データの複数のバッチ (実際のラベル値が既知) をフィードし、すべてのネットワーク レイヤーで関数を適用し、出力確率とトレーニング データの実際の既知のクラス ラベルの差を測定します。 予測出力と実際のラベルの集計された差は 、損失と呼ばれます。
ディープ ラーニング フレームワークでは、データのすべてのバッチの集計損失を計算した後、 オプティマイザーを使用 して、全体的な損失を減らすためにモデルの重みとバイアスを調整する方法を決定します。 これらの調整は、ニューラル ネットワーク モデル内のレイヤーに バックプロパティされ 、データが再びネットワーク経由で渡され、損失が再計算されます。 このプロセスは、損失が最小限に抑えられ、モデルが正確に予測できるように適切な重みとバイアスを "学習" するまで、複数回繰り返されます (各反復は エポックと呼ばれます)。
各エポックでは、損失を最小限に抑えるために重みとバイアスが調整されます。 調整される量は、オプティマイザーに指定した 学習率 によって制御されます。 学習率が低すぎると、最適な値を判断するのにトレーニング プロセスに時間がかかる場合があります。ただし、値が大きすぎると、オプティマイザーで最適な値が見つからない可能性があります。