バッチ エンドポイントを理解して作成する
モデルを取得してバッチ予測を生成するには、モデルをバッチ エンドポイントにデプロイします。
非同期バッチ スコアリングにバッチ エンドポイントを使用する方法について説明します。
バッチ予測
バッチ予測を取得するには、エンドポイントにモデルをデプロイします。 エンドポイント は、バッチ スコアリング ジョブをトリガーするために呼び出すことができる HTTPS エンドポイントです。 このようなエンドポイントの利点は、Azure Synapse Analytics や Azure Databricks などの別のサービスからバッチ スコアリング ジョブをトリガーできることです。 バッチ エンドポイントを使用すると、バッチ スコアリングを既存のデータ インジェストおよび変換パイプラインと統合できます。
エンドポイントが呼び出されるたびに、バッチ スコアリング ジョブが Azure Machine Learning ワークスペースに送信されます。 ジョブは通常、コンピューティング クラスター を使用して複数の入力をスコア付けします。 結果は、Azure Machine Learning ワークスペースに接続されたデータストアに格納できます。
バッチ エンドポイントを作成する
モデルをバッチ エンドポイントにデプロイするには、まずバッチ エンドポイントを作成する必要があります。
バッチ エンドポイントを作成するには、BatchEndpoint クラスを使用します。 バッチ エンドポイント名は、Azure リージョン内で一意である必要があります。
エンドポイントを作成するには、次のコマンドを使用します。
# create a batch endpoint
endpoint = BatchEndpoint(
name="endpoint-example",
description="A batch endpoint",
)
ml_client.batch_endpoints.begin_create_or_update(endpoint)
ヒント
Python SDK v2 を使用してバッチ エンドポイント作成するためのリファレンス ドキュメントを確認します。
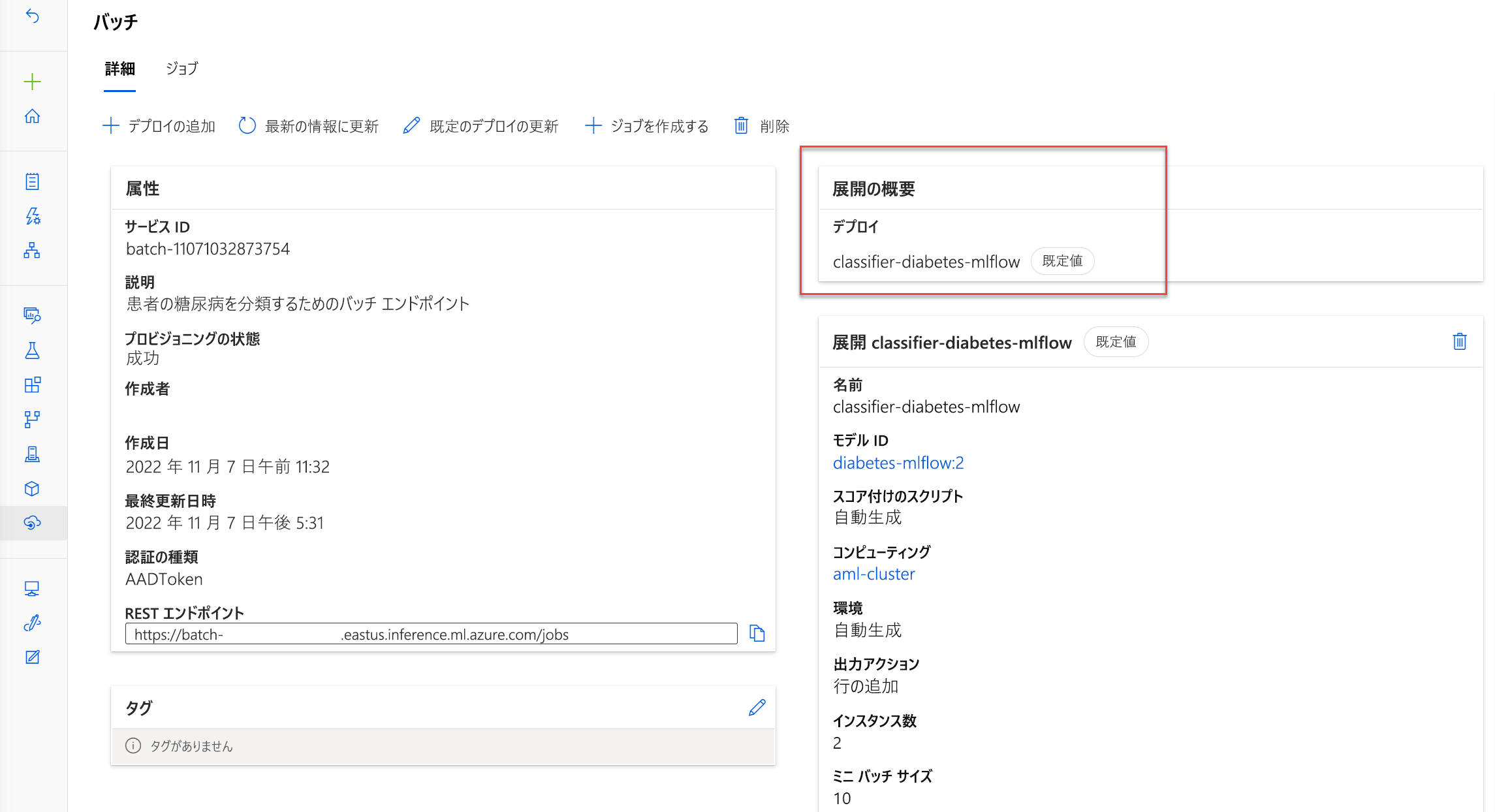
バッチ エンドポイントにモデルをデプロイする
複数のモデルをバッチ エンドポイントにデプロイできます。 バッチ スコアリング ジョブをトリガーするバッチ エンドポイントを呼び出すたびに、特に指定がない限り、既定のデプロイ が使用されます。
バッチ デプロイにコンピューティング クラスターを使用する
バッチ デプロイに使用する理想的なコンピューティングは、Azure Machine Learning コンピューティング クラスターです。 バッチ スコアリング ジョブで新しいデータを並列バッチで処理する場合は、複数の最大インスタンスを含むコンピューティング クラスターをプロビジョニングする必要があります。
コンピューティング クラスターを作成するには、AMLCompute クラスを使用できます。
from azure.ai.ml.entities import AmlCompute
cpu_cluster = AmlCompute(
name="aml-cluster",
type="amlcompute",
size="STANDARD_DS11_V2",
min_instances=0,
max_instances=4,
idle_time_before_scale_down=120,
tier="Dedicated",
)
cpu_cluster = ml_client.compute.begin_create_or_update(cpu_cluster)