生成 AI を評価する
評価は、生成型 AI アプリケーションのパフォーマンス、信頼性、有効性を評価する体系的なプロセスです。 これらの評価には、AI モデルが意図したタスクをどれだけ適切に実行しているかを定量化するように設計された一連のテストとメトリックが含まれます。 目標は、AI アプリケーションが期待どおりに動作し、さまざまなシナリオで正確で関連性の高い出力を提供することです。
評価は、いくつかの理由で重要です。
- 品質保証: AI システムが必要な精度と信頼性の基準を満たしていることを確認するのに役立ちます。
- パフォーマンス メトリック: 評価は、AI アプリの出力の有効性に関する重要なデータを提供し、改善のための領域を強調します。
- バイアス検出: AI モデルに存在するバイアスの有病率を特定して測定し、改善のための領域を強調するのに役立ちます。
- ユーザー信頼: 一貫して適切に実行される AI アプリケーションは、ユーザーとの信頼を構築し、より高い満足度と使用状況を得るのに役立ちます。
Azure での AI 支援評価
生成 AI モデルの評価は、動的でクリエイティブな出力が多いため、固有の課題を提示します。 従来の評価方法では、生成モデルの複雑さを完全に把握できない可能性があるため、より特殊なアプローチが必要になります。 そのため、機械学習手法を使用して評価プロセスを拡張する AI 支援評価を提供します。 AI 支援評価のモデルを選択すると、結果に大きな影響を与える可能性があります。 そのため、評価をテストし、計算のためにサポートされている GPT 3.5、GPT 4、または Davinci モデルと比較することをお勧めします。
Azure AI Foundry の UI を使用するか、Azure AI Evaluation SDK を使用してプログラムを使用して、Azure で評価を実行する柔軟性があります。 どちらのツールも、パフォーマンスと品質とリスクと安全性に関する一連のメトリックにアクセスできます。 ただし、プログラムを使用して、独自のコード ベースおよびプロンプト ベースのカスタム エバリュエーターを作成したり、カスタム エバリュエーターを Azure AI プロジェクトに記録したりすることもできます。
Azure AI Foundry を使用して評価する
Azure AI Foundry では、手動評価と自動評価の両方の実行がサポートされています。 手動評価を使用すると、人間の採点者は、手動入力エントリとアップロードされたデータセットの両方について、生成された出力を手動でスコア付けできます。 評価を実行した後、各応答にサムアップまたはダウン評価を指定して、プロンプト出力を評価できます。 特定のリスクを軽減する場合は、自動評価に進む前にリスクの証拠が観察されなくなるまで、小さなデータセットに対して手動で進行状況をチェックし続けると便利です。
この画像は、キャンプ ストア チャットボットの AI アシスタントのセットアップと評価に焦点を当てた、Azure AI Foundry インターフェイスのスクリーンショットを示しています。 インターフェイスには、青色のアクセントを持つ明るい配色があります。 画面は、アシスタントのセットアップ、手動評価結果、評価テーブルという複数のセクションに分かれています。 インターフェイスには、ナビゲーションや操作のためのさまざまなアイコンとツールが含まれており、編集、再生、各応答のいいね/悪いねボタンなどがあります。 このスクリーンショットは、eコマースの特定のユース ケースに対する AI アシスタントの設定、トレーニング、評価のプロセスに関する分析情報を提供します。
自動評価を使用すると、テスト データセット内のデータ行ごとに出力を生成できます。 1 つ以上の組み込みの評価メトリックを選択して、さまざまな品質の出力を評価できます。
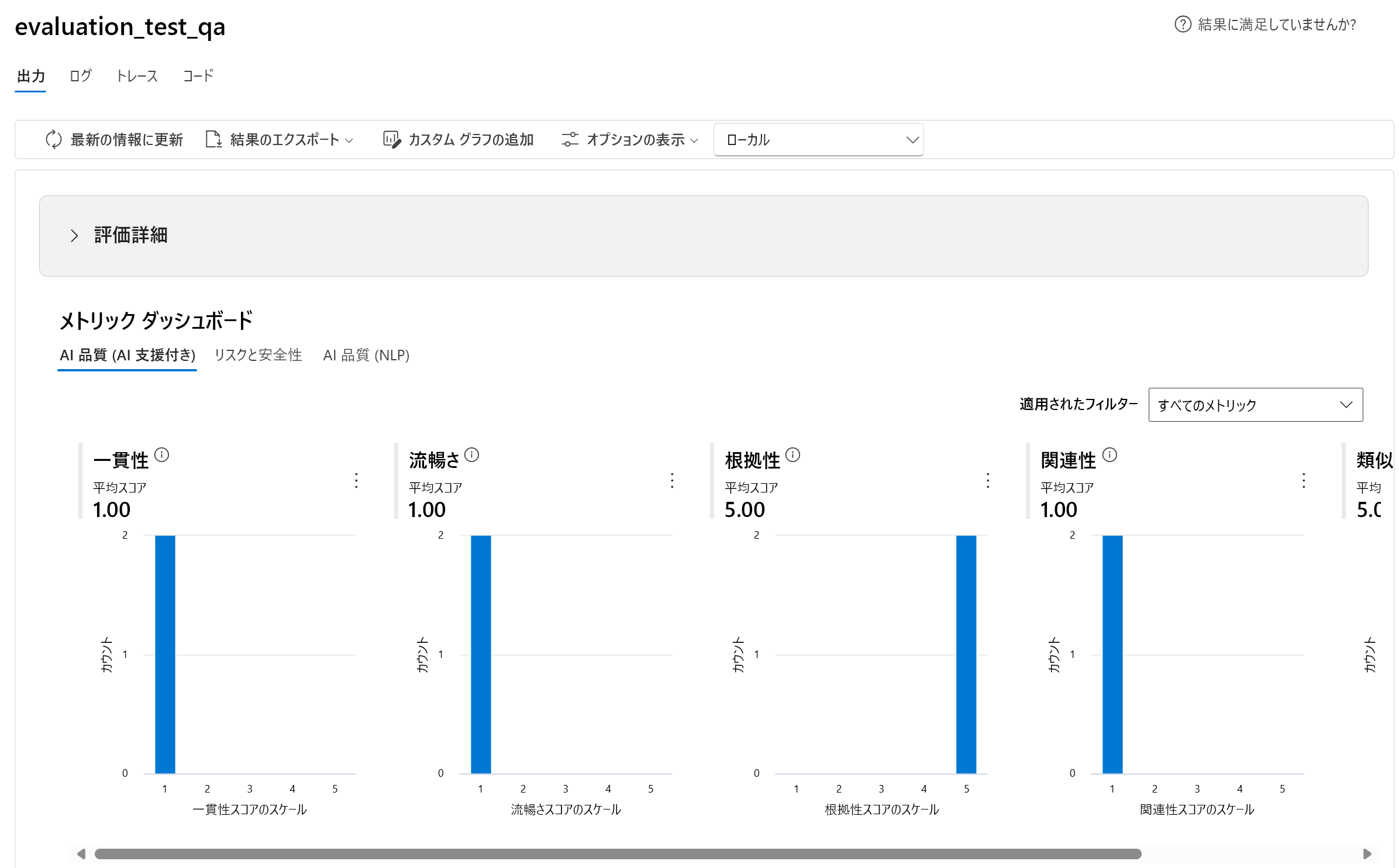
この画像は、Azure AI Foundry インターフェイスのスクリーンショットを示しています。"evaluation_test_qa" という名前のプロジェクトの評価ダッシュボードが表示されています。 インターフェイスは明るい配色のクリーンでモダンなデザインです。 画面の上部には、Azure AI Foundry のロゴ、プロジェクト名、通知、設定、プロジェクトの選択のためのさまざまなアイコンを含むヘッダーがあります。 メイン コンテンツ領域は、評価の詳細、メトリック ダッシュボードの 2 つのセクションに分かれています。 各メトリックの横に情報アイコンが表示され、追加の詳細が表示されます。 メトリック ダッシュボードの右上には、[適用されたフィルター] ドロップダウンが [すべてのメトリック] に設定されています。 画面の左側には、Azure AI Foundry 内のさまざまなセクションまたはツール用のさまざまなアイコンを含むナビゲーション メニューが含まれています。 このダッシュボードでは、複数の評価基準にわたる AI モデルのパフォーマンスの包括的なビューが提供され、開発者はモデルの出力品質を評価して改善できます。
Azure AI 評価 SDK を使用して評価する
テスト データセットまたはターゲットを指定すると、生成 AI アプリケーションのパフォーマンスが、数学ベースのメトリックと、AI 支援の品質および安全性エバリュエーターの両方で定量的に測定されます。 組み込みまたはカスタムのエバリュエーターを使用すると、アプリケーションの機能と制限に関する包括的な分析情報を得ることができます。 プログラムを使用して評価を実行すると、既存のワークフローやパイプラインと統合する柔軟性が得られます。 プログラムによる評価は Azure AI Foundry では実行されませんが、Azure AI Foundry プロジェクトで評価結果を追跡および比較できます。
一般に、自動化された評価と人間の評価のバランスを取る。 定量的分析情報と定性分析情報の両方をキャプチャするには、AI 支援評価と人間による評価の組み合わせを使用します。