Azure 仮想マシンでの高可用性 SAP HANA の実装と検証
オンプレミス開発の場合、HANA システム レプリケーションまたは共有記憶域を使用して、SAP HANA の高可用性を実現できます。 Azure 仮想マシン (VM) 上では、Azure VM HANA システム レプリケーションが現在サポートされている唯一の高可用性機能です。 SAP HANA レプリケーション は、1 つのプライマリ ノードと、少なくとも 1 つのセカンダリ ノードで構成されています。 プライマリ ノードのデータに対する変更は、セカンダリ ノードに同期的または非同期的にレプリケートされます。
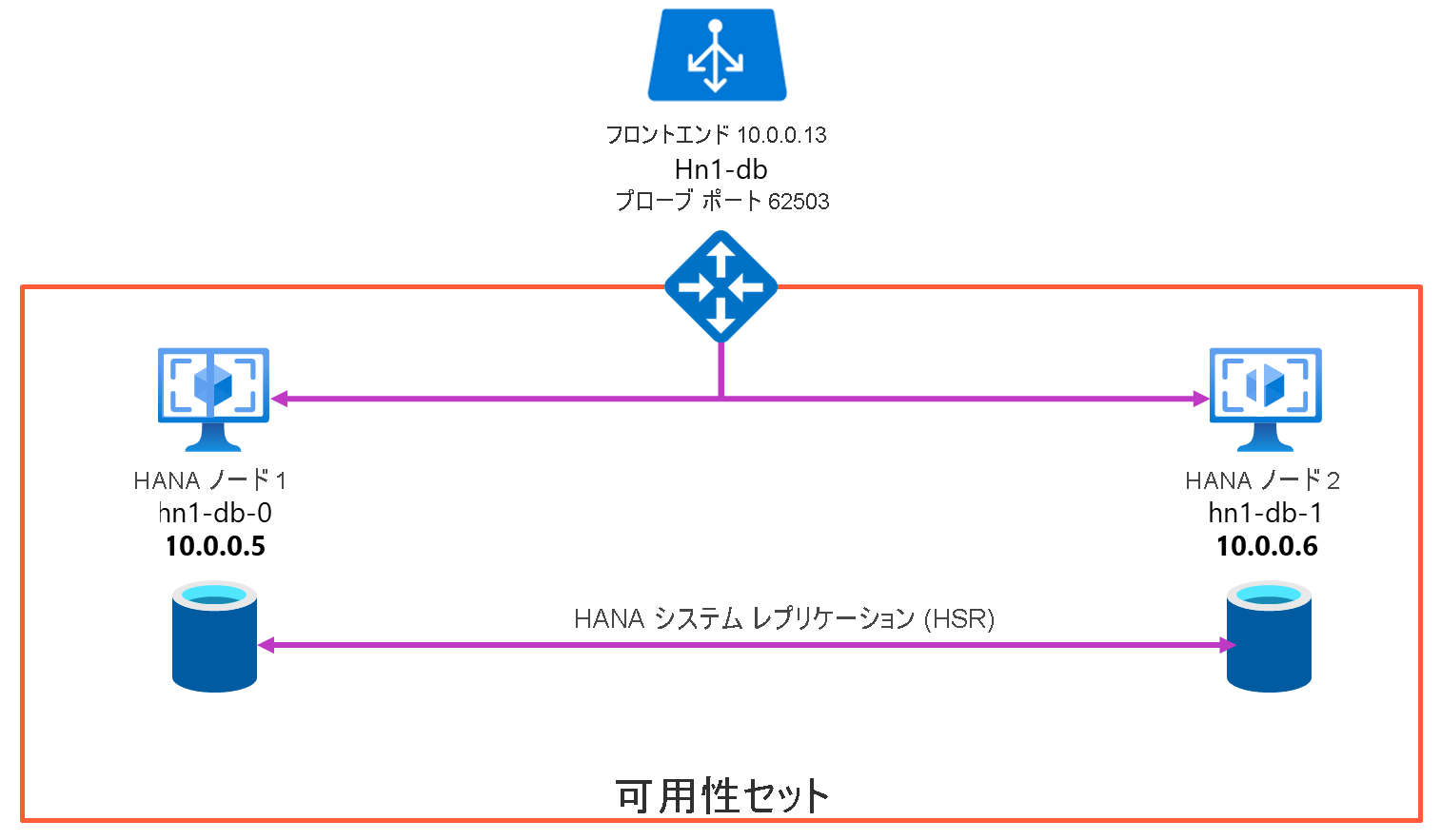
以下の手順では、SUSE Linux Enterprise Server を実行する Azure VM をデプロイして構成し、クラスター フレームワークをインストールし、SAP HANA システム レプリケーションをインストールして構成する方法について説明します。 サンプルの構成では、インストールのコマンドで、インスタンス番号として 03、HANA システム ID として HN1 が使用されています。
Red Hat Enterprise Linux を実行している Azure VM での同様な手順については、「Red Hat Enterprise Linux 上の Azure VM での SAP HANA の高可用性」を参照してください
高可用性を実現するために、SAP HANA は 2 台の仮想マシンにインストールされます。 データは、HANA システム レプリケーションを使用してレプリケートされます。
SAP HANA システム要件の設定では、専用の仮想ホスト名と仮想 IP アドレスが使用されます。 Azure では、仮想 IP アドレスを使用するためにロード バランサーが必要になります。 ロード バランサーの構成を次に示します。
- フロントエンド構成:IP アドレス 10.0.0.13 (hn1-db)
- バックエンド構成:HANA システム レプリケーションに含める必要のあるすべての仮想マシンのプライマリ ネットワーク インターフェイスに接続済み
- プローブ ポート:ポート 62503
- 負荷分散規則:30313 TCP、30315 TCP、30317 TCP
Azure リソースをプロビジョニングする
SAP HANA のリソース エージェントは、SUSE Linux Enterprise Server for SAP Applications に含まれています。 Azure Marketplace には、SUSE Linux Enterprise Server for SAP Applications 12 のイメージが含まれており、新しい仮想マシンのデプロイに使用できます。
テンプレートを使用したデプロイ
GitHub にあるいずれかのクイック スタート テンプレートを使用して、必要なすべてのリソースをデプロイできます。 テンプレートをデプロイするには、次の手順に従います。
Azure portal で、データベース テンプレートまたは集約型テンプレートを開きます。 データベース テンプレートでは、データベース用の負荷分散規則のみが作成されます。 統合テンプレートでは、ASCS/SCS および ERS (Linux のみ) インスタンス用の負荷分散規則も作成されます。 SAP NetWeaver ベースのシステムをインストールする予定があり、同じコンピューターに ASCS/SCS インスタンスをインストールする場合は、集約型テンプレートを使用します。
次のパラメーターを入力します。
- [Sap System Id](SAP システム ID) :インストールする SAP システムの SAP システム ID を入力します。 この ID は、デプロイされるリソースのプレフィックスとして使われます。
- [スタックの種類] :(このパラメーターは、集約型テンプレートを使用する場合にのみ適用されます)。SAP NetWeaver のスタックの種類を選択します。
- [OS Type](OS の種類) :いずれかの Linux ディストリビューションを選択します。 この例では、SLES 12 を選択します。
- [Db Type](データベースの種類) : [HANA] を選択します。
- [Sap System Size](SAP システムのサイズ) :新しいシステムが提供する SAPS の数を入力します。 システムに必要な SAPS の数がわからない場合は、SAP のテクノロジ パートナーまたはシステム インテグレーターにお問い合わせください。
- [System Availability](システムの可用性) : [HA] を選択します。
- [管理ユーザー名] と [管理パスワード] :オペレーティング システムへのサインインに使用できる新しい管理ユーザー アカウントです。
- [New Or Existing Subnet](新規または既存のサブネット) :新しい仮想ネットワークとサブネットを作成するか、既存のサブネットを使用するかを決定します。 オンプレミス ネットワークに接続している仮想ネットワークが既にある場合は、 [Existing](既存) を選択します。
- サブネット ID:割り当てるべきサブネットが定義されている既存の仮想ネットワークに VM をデプロイする必要がある場合、その特定のサブネットの ID を指定します。 ID は、通常、次のようになります。
/subscriptions/subscription ID/resourceGroups/resource group name/providers/Microsoft.Network/virtualNetworks/virtual network name/subnets/subnet name
手動デプロイ (Azure portal を使用)
リソース グループを作成します。
仮想ネットワークを作成します。
可用性セットを作成します。
- 最大更新ドメインを設定します。
ロード バランサー (内部) を作成します。
- 手順 2 で作成した仮想ネットワークを選択します。
仮想マシン 1 を作成します。
- 選択した VM タイプの SAP HANA でサポートされている Azure ギャラリー内の SLES4SAP イメージを使用します。
- 手順 3 で作成した可用性セットを選択します。
仮想マシン 2 を作成します。
- 選択した VM タイプの SAP HANA でサポートされている Azure ギャラリー内の SLES4SAP イメージを使用します。
- 手順 3 で作成した可用性セットを選択します。
データ ディスクを追加します。
ロードバランサーを構成します。 まず、フロントエンド IP プールを作成します:
- Azure portal でロード バランサーを開き、フロントエンド IP プールを選択して、[追加] を選択します。
- 新規のフロントエンド IP プールの名前を入力します (例: hana-frontend)。
- [Assignment](割り当て) を [Static](静的) に設定し、IP アドレスを入力します (例: 10.0.0.13)。
- 新しいフロントエンド IP プールが作成されたら、プールの IP アドレスを書き留めます。
次に、バックエンド プールを作成します。
- ロードバランサーを開き、 [backend pools](バックエンド プール) を選択し、 [Add](追加) を選択します。
- 新しいバックエンド プールの名前を入力します (例: hana-backend)。
- [Add a virtual machine](仮想マシンの追加) を選択します。
- 手順 3 で作成した可用性セットを選択します。
- SAP HANA クラスターの仮想マシンを選択します。
次に、正常性プローブを作成します。
- ロード バランサーを開き、[health probes](正常性プローブ) を選択して [追加] を選択します。
- 新しい正常性プローブの名前を入力します (例: hana-hp)。
- プロトコルとして [TCP] を選択し、ポート 62503 を選択します。 [Interval](間隔) の値を 5 に設定し、 [Unhealthy threshold](異常しきい値) の値を 2 に設定します。
- [OK] を選択します。
SAP HANA 1.0 の場合は、負荷分散規則を作成します。
- ロード バランサーを開き、[load balancing rules](負荷分散規則) を選択して [追加] を選択します。
- 新しいロード バランサー規則の名前を入力します (例: hana-lb-30315)。
- 前の手順で作成したフロントエンド IP アドレス、バックエンド プール、正常性プローブを選択します (例: hana-frontend)。
- [Protocol](プロトコル) を [TCP] に設定し、ポート 303 15 を入力します。
- [idle timeout](アイドル タイムアウト) を 30 分に増やします
- Floating IP を有効にします。
- ポート 30317 について、これらの手順を繰り返します。
SAP HANA 2.0 の場合は、システム データベースの負荷分散規則を作成します。
- ロード バランサーを開き、[load balancing rules](負荷分散規則) を選択して [追加] を選択します。
- 新しいロード バランサー規則の名前を入力します (例: hana-lb-30313)。
- 前の手順で作成したフロントエンド IP アドレス、バックエンド プール、正常性プローブを選択します (例: hana-frontend)。
- [Protocol](プロトコル) を [TCP] に設定し、ポート 303 13 を入力します。
- [idle timeout](アイドル タイムアウト) を 30 分に増やします
- Floating IP を有効にします。
- ポート 30314 について、これらの手順を繰り返します。
SAP HANA 2.0 の場合は、まずテナント データベースの負荷分散規則を作成します。
- ロード バランサーを開き、[load balancing rules](負荷分散規則) を選択して [追加] を選択します。
- 新しいロード バランサー規則の名前を入力します (例: hana-lb-30340)。
- 前の手順で作成したフロントエンド IP アドレス、バックエンド プール、正常性プローブを選択します (例: HANA-frontend)。
- [Protocol](プロトコル) を [TCP] に設定し、ポート 303 40 を入力します。
- [idle timeout](アイドル タイムアウト) を 30 分に増やします
- Floating IP を有効にします。
- ポート 30341 と 30342 について、これらの手順を繰り返します。
SAP HANA に必要なポートの詳細については、SAP Note #2388694 を参照してください。
重要
Azure ロード バランサーの背後に配置された Azure VM では TCP タイムスタンプを有効にしないでください。 TCP タイムスタンプを有効にすると正常性プローブが失敗することになります。 パラメーター net.ipv4.tcp_timestamps は 0 に設定します。
Pacemaker クラスターの作成
「Setting up Pacemaker on Red Hat Enterprise Linux in Azure」 (Azure で Red Hat Enterprise Linux に Pacemaker を設定する) の手順に従って、この HANA サーバーに対して基本的な Pacemaker クラスターを作成します。 SAP HANA および SAP NetWeaver (A) SCS に対して同じ Pacemaker クラスターを使用することができます。
SAP HANA のインストール
このセクションの手順では、次のプレフィックスを使用します。[A]: この手順はすべてのノードに適用されます。 [1] :この手順はノード 1 にのみ適用されます。 [2] :この手順は Pacemaker クラスターのノード 2 にのみ適用されます。
[A] 論理ボリューム マネージャー (LVM) を使用してディスクのレイアウトを設定します。 データおよびログ ファイルを格納するボリュームには、LVM を使用することをお勧めします。 次の例では、2 つのボリュームの作成に使用する 4 つのデータ ディスクが Azure VM にアタッチされていると仮定しています。
- 使用可能なすべてのディスクの一覧を取得します
ls /dev/disk/azure/scsi1/lun*- 使用するすべてのディスクの物理ボリュームを作成します
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3- データ ファイル用のボリューム グループを作成します。 ログ ファイルには 1 つのボリューム グループを使用し、もう 1 つは SAP HANA の共有ディレクトリに使用します
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3- 論理ボリュームを作成します。
-iスイッチを指定せずにlvcreateを使用すると、線形のボリュームが作成されます。 I/O パフォーマンスを向上させるためにストライプ ボリュームを作成することをお勧めします。この場合、-i 引数には基になる物理ボリュームの数を指定する必要があります。 この例では、データ ボリュームに 2 つの物理ボリュームを使用するため、-i スイッチ引数は 2 に設定します。 1 つの物理ボリュームはログ ボリュームに使用されるため、-i スイッチは明示的には使用されていません。 データ、ログ、または共有ボリュームごとに複数の物理ボリュームを使用する場合は、-i スイッチを使用して、基になる物理ボリュームの数を設定します。
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_HN1 /dev/disk/azure/scsi1/lun3- マウント ディレクトリを作成し、すべての論理ボリュームの UUID をコピーします
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 sudo mkdir -p /hana/shared/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data, /dev/vg_hana_log_HN1/hana_log, and /dev/vg_hana_shared_HN1/hana_shared sudo blkid- 3 つの論理ボリュームの fstab エントリを作成します
sudo vi /etc/fstab- /etc/fstab ファイルに次の行を挿入します。
/dev/disk/by-uuid/[UUID of /dev/mapper/vg_hana_data_HN1-hana_data] /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/[UUID of /dev/mapper/vg_hana_log_HN1-hana_log] /hana/log/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/[UUID of /dev/mapper/vg_hana_shared_HN1-hana_shared] /hana/shared/HN1 xfs defaults,nofail 0 2- 新しいボリュームをマウントします。
sudo mount -a[A] ディスク レイアウトを設定します。
- デモ システムの場合、ご自身の HANA のデータとログ ファイルを 1 つのディスクに配置することができます。 /dev/disk/azure/scsi1/lun0 にパーティションを作成し、xfs でフォーマットします。
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstab- /etc/fstab ファイルにこの行を挿入します。
/dev/disk/by-uuid/[UUID] /hana xfs defaults,nofail 0 2- ターゲット ディレクトリを作成してディスクをマウントします。
sudo mkdir /hana sudo mount -a[A] すべてのホストに対してホスト名解決を設定します。 DNS サーバーを使用するか、すべてのノードの /etc/hosts ファイルを変更することができます。
[A] SAP HANA 高可用性パッケージをインストールします
sudo zypper install SAPHanaSR[A] HANA のインストール メディアから hdblcm プログラムを実行します。 プロンプトで次の値を入力します。
- Choose installation (インストールの選択):1 を入力します。
- インストールするその他のコンポーネントを選択します:「1」と入力します。
- Enter Installation Path [/hana/shared] (インストール パス [/hana/shared] を入力): Enter キーを押します。
- Enter Local Host Name [..] (ローカル ホスト名 [..] を入力): Enter キーを押します。
- Do you want to add additional hosts to the system? (システムに別のホストを追加しますか?) (y/n) \[n]:Enter キーを押します。
- Enter SAP HANA System ID (SAP HANA のシステム ID を入力):HANA の SID を入力します。例:HN1。
- Enter Instance Number [00] (インスタンス番号 (00) を入力): HANA のインスタンス番号を入力します。 Azure テンプレートを使用した場合、またはこの記述の手動デプロイに関するセクションに従った場合は、「03」を入力します。
- [データベース モード] を選択し、[インデックス] に「[1]」と入力します。Enter キーを押します。
- Select System Usage / Enter Index [4] \(システム使用率の選択/インデックス (4) の入力):システムの使用率の値を選択します。
- Enter Location of Data Volumes (データ ボリュームの場所の入力) [/hana/data/HN1]:Enter キーを押します。
- Enter Location of Log Volumes (ログ ボリュームの場所の入力) [/hana/log/HN1]:Enter キーを押します。
- Restrict maximum memory allocation? (メモリの最大割り当てを制限しますか?) \[n]:Enter キーを押します。
- Enter Certificate Host Name For Host '...' [...] (ホスト '...' の証明書のホスト名 [...] を入力): Enter キーを押します。
- Enter SAP Host Agent User (sapadm) Password (SAP ホスト エージェントのユーザー (sapadm) パスワードを入力): ホスト エージェントのユーザー パスワードを入力します。
- Confirm SAP Host Agent User (sapadm) Password (SAP ホスト エージェント ユーザー (sapadm) のパスワードを確認): 確認用にホスト エージェント ユーザーのパスワードを再入力します。
- Enter System Administrator (hdbadm) Password (システム管理者 (hdbadm) のパスワードを入力): システム管理者のパスワードを入力します。
- Confirm System Administrator (hdbadm) Password (システム管理者 (hdbadm) のパスワードを確認): 確認用にシステム管理者のパスワードを再入力します。
- Enter System Administrator Home Directory [/usr/sap/HN1/home] (システム管理者のホーム ディレクトリ [/usr/sap/HN1/home] を入力): Enter キーを押します。
- Enter System Administrator Login Shell [/bin/sh] (システム管理者のログイン シェル [/bin/sh] を入力): Enter キーを押します。
- Enter System Administrator User ID [1001] (システム管理者のユーザー ID [1001] を入力): Enter キーを押します。
- Enter ID of User Group (sapsys) [79] (ユーザー グループ (sapsys) の ID [79] を入力): Enter キーを押します。
- Enter Database User (SYSTEM) Password (データベース ユーザー (SYSTEM) のパスワードを入力): データベース ユーザーのパスワードを入力します。
- Confirm Database User (SYSTEM) Password (データベース ユーザー (SYSTEM) のパスワードを確認): 確認用にデータベース ユーザーのパスワードを再入力します。
- Restart system after machine reboot? (コンピューターの再起動後にシステムを再起動しますか?) \[n]:Enter キーを押します。
- Do you want to continue? (続行してもよろしいですか?) (y/n):概要を確認します。 「y」と入力して続行します。
[A] SAP Host Agent をアップグレードします。 SAP Software Center から最新の SAP Host Agent アーカイブをダウンロードし、次のコマンドを実行してエージェントをアップグレードします。 アーカイブのパスを置き換えて、ダウンロードしたファイルを示すようにします。
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive [path to SAP Host Agent SAR]
SAP HANA 2.0 システム レプリケーションの構成
[1] テナント データベースを作成します。 SAP HANA 2.0 または MDC を使用している場合は、ご自身の SAP NetWeaver システムに対してテナント データベースを作成します。 NW1 をご自身の SAP システムの SID に置き換えます。
hanasidadmとして次のコマンドを実行します。hdbsql -u SYSTEM -p "passwd" -i 03 -d SYSTEMDB 'CREATE DATABASE NW1 SYSTEM USER PASSWORD "passwd"'[1] 最初のノードでシステム レプリケーションを構成します
hanasidadmとしてデータベースをバックアップします。
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')" hdbsql -d NW1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupNW1')"- システム PKI ファイルをセカンダリ サイトにコピーします。
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/- プライマリ サイトを作成します。
hdbnsutil -sr_enable --name=SITE1[2] 2 番目のノードでシステム レプリケーションを構成します。 2 番目のノードを登録して、システム レプリケーションを開始します。
hanasidadm管理者として次のコマンドを実行します。sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
SAP HANA 1.0 システム レプリケーションの構成
[1] 必要なユーザーを作成します。 ルートとして次のコマンドを実行します。
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbsql -u system -i 03 'CREATE USER hdbhasync PASSWORD "passwd"' hdbsql -u system -i 03 'GRANT DATA ADMIN TO hdbhasync' hdbsql -u system -i 03 'ALTER USER hdbhasync DISABLE PASSWORD LIFETIME'[A] キーストア エントリを作成します。 root として次のコマンドを実行して、新しいキーストア エントリを作成します。
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbuserstore SET hdbhaloc localhost:30315 hdbhasync passwd[1] データベースをバックアップします。
- root としてデータベースをバックアップします。
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbsql -d SYSTEMDB -u system -i 03 "BACKUP DATA USING FILE ('initialbackup')"- マルチテナント インストールを使用する場合は、テナント データベースもバックアップします。
hdbsql -d HN1 -u system -i 03 "BACKUP DATA USING FILE ('initialbackup')"[1] 最初のノードでシステム レプリケーションを構成します。
hanasidadmとしてプライマリ サイトを作成します。su - hdbadm hdbnsutil -sr_enable –-name=SITE1[2] セカンダリ ノードでシステム レプリケーションを構成します。
hanasidadmとしてセカンダリ サイトを登録します。sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
SAP HANA クラスター リソースの作成
最初に、HANA トポロジを作成します。 Pacemaker クラスター ノードのいずれかで、次のコマンドを実行します。
sudo crm configure property maintenance-mode=true # Replace the bold string with your instance number and HANA system ID sudo crm configure primitive rsc_SAPHanaTopology_HN1_HDB03 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HN1_HDB03-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HN1" InstanceNumber="03" sudo crm configure clone cln_SAPHanaTopology_HN1_HDB03 rsc_SAPHanaTopology_HN1_HDB03 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"次に、HANA リソースを作成します。
Note
この記事には、Microsoft が使用しなくなった "スレーブ" という用語への言及が含まれています。 ソフトウェアからこの用語が削除された時点で、この記事から削除します。
# Replace the bold string with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer. sudo crm configure primitive rsc_SAPHana_HN1_HDB03 ocf:suse:SAPHana \ operations \$id="rsc_sap_HN1_HDB03-operations" \ op start interval="0" timeout="3600" \ op stop interval="0" timeout="3600" \ op promote interval="0" timeout="3600" \ op monitor interval="60" role="Master" timeout="700" \ op monitor interval="61" role="Slave" timeout="700" \ params SID="HN1" InstanceNumber="03" PREFER_SITE_TAKEOVER="true" \ DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false" sudo crm configure ms msl_SAPHana_HN1_HDB03 rsc_SAPHana_HN1_HDB03 \ meta is-managed="true" notify="true" clone-max="2" clone-node-max="1" \ target-role="Started" interleave="true" sudo crm configure primitive rsc_ip_HN1_HDB03 ocf:heartbeat:IPaddr2 \ meta target-role="Started" is-managed="true" \ operations \$id="rsc_ip_HN1_HDB03-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.0.0.13" sudo crm configure primitive rsc_nc_HN1_HDB03 anything \ params binfile="/usr/bin/nc" cmdline_options="-l -k 62503" \ op monitor timeout=20s interval=10 depth=0 sudo crm configure group g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 rsc_nc_HN1_HDB03 sudo crm configure colocation col_saphana_ip_HN1_HDB03 4000: g_ip_HN1_HDB03:Started \ msl_SAPHana_HN1_HDB03:Master sudo crm configure order ord_SAPHana_HN1_HDB03 Optional: cln_SAPHanaTopology_HN1_HDB03 \ msl_SAPHana_HN1_HDB03 # Clean up the HANA resources. The HANA resources might have failed because of a known issue. sudo crm resource cleanup rsc_SAPHana_HN1_HDB03 sudo crm configure property maintenance-mode=false sudo crm configure rsc_defaults resource-stickiness=1000 sudo crm configure rsc_defaults migration-threshold=5000クラスターの状態が正常であることと、すべてのリソースが起動されていることを確認します。 リソースがどのノードで実行されているかは重要ではありません。
sudo crm_mon -r # Online: [ hn1-db-0 hn1-db-1 ] # # Full list of resources: # # stonith-sbd (stonith:external/sbd): Started hn1-db-0 # rsc_st_azure (stonith:fence_azure_arm): Started hn1-db-1 # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] # Started: [ hn1-db-0 hn1-db-1 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] # Masters: [ hn1-db-0 ] # Slaves: [ hn1-db-1 ] # Resource Group: g_ip_HN1_HDB03 # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 # rsc_nc_HN1_HDB03 (ocf::heartbeat:anything): Started hn1-db-0
クラスターの設定をテストする
移行をテストします。 テストを開始する前に、(crm_mon -r を使用して) Pacemaker に何か失敗したアクションが存在しないこと、予期しない場所の制約 (たとえば、移行テストの影響など) が存在しないこと、そして HANA が (たとえば、'SAPHanaSR-showAttr' などと) 同期状態であることを確認します。
aspx-csharp SAPHanaSR-showAttr- SAP HANA マスター ノードは、次のコマンドを実行すると移行できます。
crm resource migrate msl_SAPHana_HN1_HDB03 hn1-db-1- AUTOMATED_REGISTER="false" を設定した場合、この一連のコマンドにより、SAP HANA マスター ノードと、仮想 IP アドレスを含むグループが hn1-db-1 に移行します。 移行の完了後、crm_mon -r の出力は次のようになります。
Online: [ hn1-db-0 hn1-db-1 ] Full list of resources: stonith-sbd (stonith:external/sbd): Started hn1-db-1 Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Stopped: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:anything): Started hn1-db-1 Failed Actions: * rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none', last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms- hn1-db-0 の SAP HANA リソースは、セカンダリとしての起動に失敗します。 その場合は、次のコマンドを実行して HANA のインスタンスをセカンダリとして構成してください。
su - hn1adm # Stop the HANA instance just in case it's running hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr 03 -function StopWait 600 10 hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1- 移行では場所の制約が作成されますが、これは再度削除する必要があります。
# Switch back to root and clean up the failed state exit hn1-db-0:~ # crm resource unmigrate msl_SAPHana_HN1_HDB03- また、セカンダリ ノードのリソースの状態をクリーンアップする必要があります。
hn1-db-0:~ # crm resource cleanup msl_SAPHana_HN1_HDB03 hn1- db-0- crm_mon -r を使用して HANA リソースの状態を監視します。 HANA が hn1-db-0 で開始すると、出力は次のようになります。
Online: [ hn1-db-0 hn1-db-1 ] Full list of resources: stonith-sbd (stonith:external/sbd): Started hn1-db-1 Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:anything): Started hn1-db-1(SBD ではなく) Azure フェンス エージェントをテストする
- Azure フェンス エージェントの設定をテストするには、hn1-db-0 ノードでネットワーク インターフェイスを無効にします。
sudo ifdown eth0- クラスターの構成によっては、仮想マシンが再起動するか停止します。 stonith-action 設定をオフに設定すると、仮想マシンが停止し、実行中の仮想マシンにリソースが移行されます。
- AUTOMATED_REGISTER="false" を設定した場合、仮想マシンを再起動した後、SAP HANA リソースがセカンダリとしての起動に失敗します。 その場合は、次のコマンドを実行して HANA のインスタンスをセカンダリとして構成してください。
su - hn1adm # Stop the HANA instance just in case it's running sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1 # Switch back to root and clean up the failed state exit crm resource cleanup msl_SAPHana_HN1_HDB03 hn1-db-0SBD フェンスをテストする
- SBD の設定をテストするには、inquisitor プロセスを強制終了します。
hn1-db-0:~ # ps aux | grep sbd root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8 root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd hn1-db-0:~ # kill -9 1912 Cluster node hn1-db-0 should be rebooted. The Pacemaker service might not get started afterward. Make sure to start it again.手動フェールオーバーをテストする
- hn1-db-0 ノードで Pacemaker サービスを停止することで、手動フェールオーバーをテストできます。
service pacemaker stop- フェールオーバー後、サービスを再度開始できます。 AUTOMATED_REGISTER="false" を設定した場合、hn1-db-0 ノードの SAP HANA リソースがセカンダリとしての起動に失敗します。 その場合は、次のコマンドを実行して HANA のインスタンスをセカンダリとして構成してください。
service pacemaker start su - hn1adm # Stop the HANA instance just in case it's running sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1 # Switch back to root and clean up the failed state exit crm resource cleanup msl_SAPHana_HN1_HDB03 hn1-db-0
SUSE のテスト
ユース ケースに応じて、「SAP HANA SR Performance Optimized Scenario」(SAP HANA SR パフォーマンス最適化シナリオ) ガイドまたは「SAP HANA SR Cost Optimized Scenario」(SAP HANA SR コスト最適化シナリオ) ガイドに記載されているすべてのテスト ケースを実行します。 以下のテストは、『SUSE Linux Enterprise Server for SAP Applications 12 SP4 ガイド』の「SAP HANA SR Performance Optimized Scenario」 (SAP HANA SR のパフォーマンス最適化のシナリオ) に記載されているテストの説明のコピーです。 最新バージョンについては、常にガイドも参照してください。 テストを開始する前に常に HANA が同期していることを確認し、Pacemaker の設定が正しいことを確認してください。 これ以降のテストの説明では、PREFER_SITE_TAKEOVER="true" および AUTOMATED_REGISTER="false" が設定されていると仮定しています。 注:次のテストは、順番に実行されるように設計されており、前のテストの終了状態によって異なります。
- テスト 1:ノード 1 上のプライマリ データベースを停止する
- テスト 2:ノード 2 上のプライマリ データベースを停止する
- テスト 3:ノードのプライマリ データベースをクラッシュさせる
- テスト 4:ノード 2 上のプライマリ データベースをクラッシュさせる
- テスト 5:プライマリ サイト ノード (ノード 1) をクラッシュさせる
- テスト 6:セカンダリ サイト ノード (ノード 2) をクラッシュさせる
- テスト 7:ノード 2 上のセカンダリ データベースを停止する
- テスト 8:ノード 2 上のセカンダリ データベースをクラッシュさせる
- テスト 9:セカンダリ HANA データベースを実行しているセカンダリ サイト ノード (ノード 2) をクラッシュさせる