自然言語処理 (NLP) に使用されるトランスフォーマー アーキテクチャについて理解する
自然言語処理 (NLP) における最新のブレークスルーは、トランスフォーマー アーキテクチャの開発に負うところが大きいといえます。
トランスフォーマーは、Vaswaniらによる2017年の論文「Attention is all you need」で紹介されました。 トランスフォーマー アーキテクチャは、NLP を実行するための リカレント ニューラル ネットワーク (RNNS) に代わる手段を提供します。 RNN は単語を順番に処理するためコンピューティング集中型ですが、トランスフォーマーは単語を順番に処理するのではなく、 注意を使用して各単語を並列に処理します。
テキストの意味を理解するうえで、文中の単語の位置と単語の順序は重要です。 この情報を含めるために、テキストを順番に処理しなくても、トランスフォーマーは 位置エンコードを使用します。
位置エンコードについて理解する
トランスフォーマーより前の言語モデルでは、単語埋め込みを使ってテキストをベクトルにエンコードしていました。 Transformer アーキテクチャでは、 位置エンコード を使用してテキストをベクターにエンコードします。 位置エンコードは、単語埋め込みベクトルと位置ベクトルの和です。 これにより、エンコードされたテキストには、文内の単語の意味 と 位置に関する情報が含まれます。
文内の単語の位置をエンコードするには、1 つの数値を使ってインデックス値を表すことができます。 例えば次が挙げられます。
| トークン | インデックス値 |
|---|---|
| この | 0 |
| 作業 | 1 |
| of | 2 |
| ウィリアム | 3 |
| Shakespeare | 4 |
| inspired | 5 |
| many | 6 |
| movies | 7 |
| ... | ... |
テキストまたはシーケンスが長いほど、インデックス値が大きくなる可能性があります。 テキスト内の各位置に対して一意の値を使うのはシンプルなアプローチですが、その値は意味を持たなくなり、値が大きくなるとモデルのトレーニング中に不安定が生じるおそれがあります。
提案されたソリューションは、Attention is all you need 論文でシンプルに示されたもので、サイン関数とコサイン関数を用いるものであり、ここでposは位置、iは次元を表します。
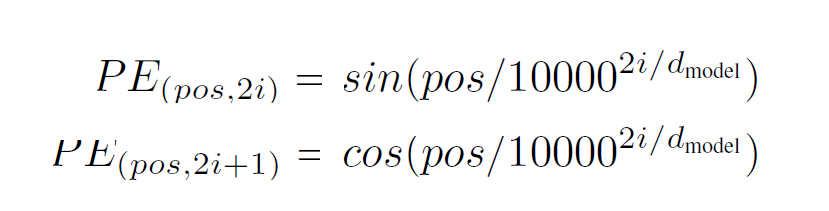
これらの定期的な関数を一緒に使用して作成する場合は、各位置に固有のベクトルを作成できます。 その結果、値は範囲内にあり、大きなテキストをエンコードしてもインデックスは大きくなりません。 また、これらの位置ベクトルにより、モデルは文内の異なる単語の位置を計算して比較しやすくなります。
マルチヘッド アテンションについて理解する
トランスフォーマーがテキストを処理するために使う最も重要な手法は、再帰ではなくアテンションを使うことです。
注意 (自己注意または内部注意とも呼ばれます) は、新しい情報が何を必要とするのかを理解するために、学習した情報に新しい情報をマップするために使用されるメカニズムです。
トランスフォーマーはアテンション 関数を使用します。ここで、新しい単語は (位置エンコードを使用して) エンコードされ、 クエリとして表されます。 エンコードされた単語の出力は、関連付けられた値を持つキーです。
アテンション関数で使われる 3 つの変数 (クエリ、キー、値) を説明するために、簡略化された例を見てみましょう。 文のエンコードを想像してみてください Vincent van Gogh is a painter, known for his stunning and emotionally expressive artworks. クエリ Vincent van Goghをエンコードするときに、出力がキーとして Vincent van Gogh され、関連付けられた値として painter される場合があります。 アーキテクチャによってキーと値がテーブルに格納され、将来のデコードのために使用できます。
| キー | 価値観 |
|---|---|
| Vincent Van Gogh | Painter |
| William Shakespeare | Playwright |
| Charles Dickens | 作家 |
Shakespeare's work has influenced many movies, mostly thanks to his work as a ...のように新しい文が表示されるたびに。 モデルは、クエリとして Shakespeare を取得し、キーと値のテーブルで 検索 することで、文を完成させることができます。 Shakespeare クエリはキー William Shakespeare に最も近いため、関連付けられた値 playwright が出力として表示されます。
スケーリングされたドット積を使用してアテンション関数を計算する
アテンション関数を計算するために、クエリ、キー、値はすべてベクトルにエンコードされます。 次に、アテンション関数は、クエリのベクトルとキーのベクトルの間のスケーリングされたドット積を計算します。
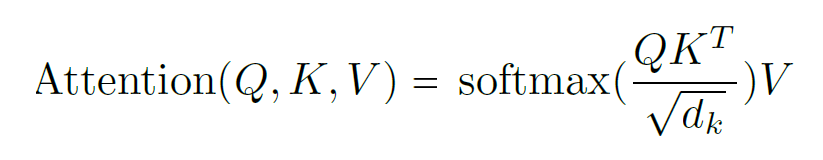
ドット積は、トークンを表すベクトル間の角度を計算し、ベクトルがより整列されたときに積が大きくなります。
softmax 関数は、ベクトルのスケールされたドット積に対してアテンション関数内で使用され、可能な結果を持つ確率分布を作成します。 言い換えると、ソフトマックス関数の出力には、どのキーがクエリに最も近いかが含まれています。 その後、最も高い確率のキーが選択され、関連付けられた値がアテンション関数の出力になります。
トランスフォーマー アーキテクチャでは、マルチヘッド アテンションが使われます。つまり、トークンはアテンション関数によって複数回並列に処理されます。 そうすることで、単語または文を複数回、さまざまな方法で処理し、文からさまざまな種類の情報を抽出することができます。
トランスフォーマー アーキテクチャを調べる
注意が必要な論文では、提案されたトランスフォーマーアーキテクチャは次のようにモデル化されています。
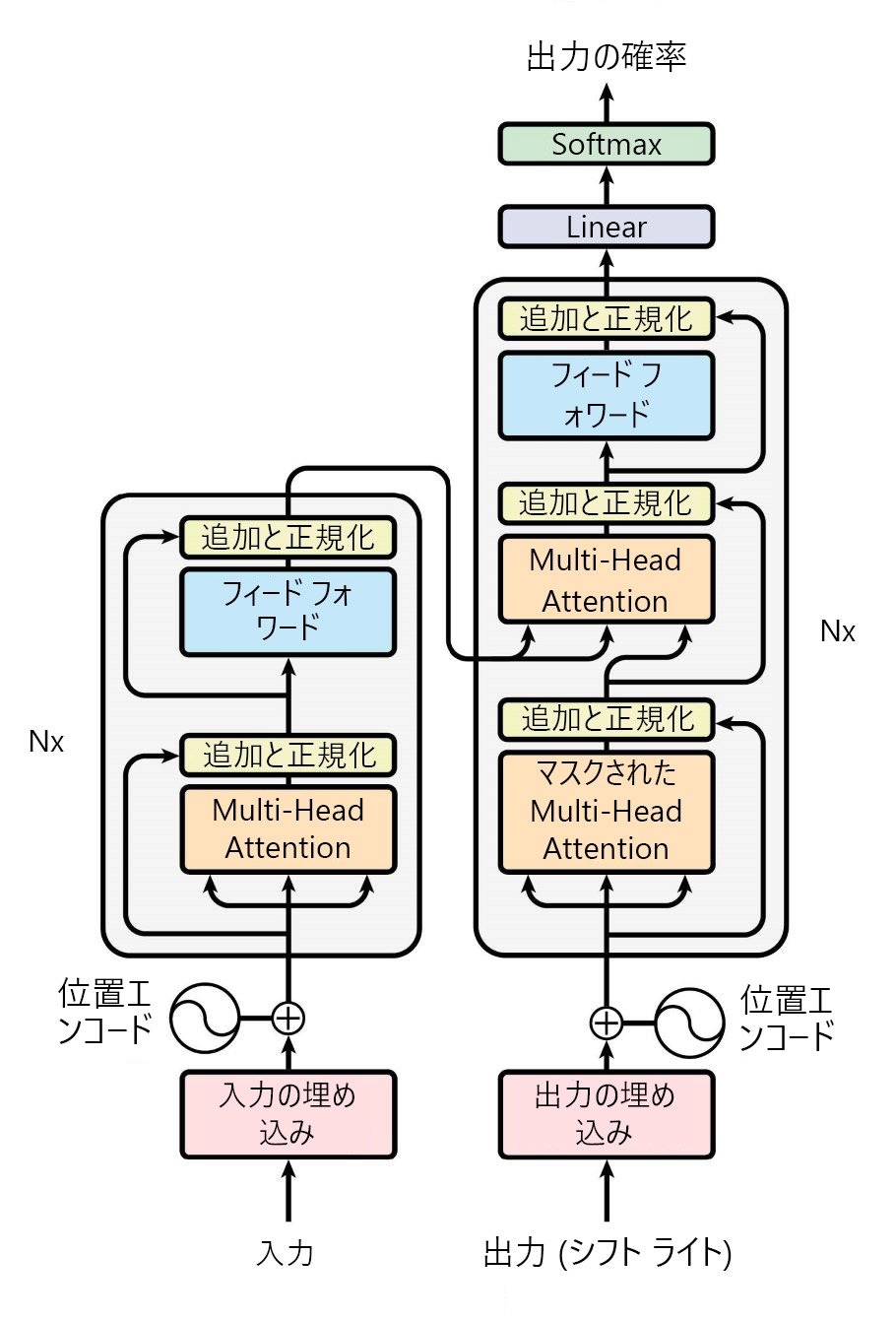
元のトランスフォーマー アーキテクチャには、次の 2 つのメイン コンポーネントがあります。
- エンコーダー: 入力シーケンスを処理し、各トークンのコンテキストをキャプチャする表現を作成します。
- デコーダー: エンコーダーの表現に参加し、シーケンス内の次のトークンを予測することで、出力シーケンスを生成します。
トランスフォーマー アーキテクチャで示された最も重要なイノベーションは、 位置エンコード と マルチヘッドの注意でした。 これらの 2 つのコンポーネントに焦点を当てたアーキテクチャの簡略化された表現は、次のようになります。
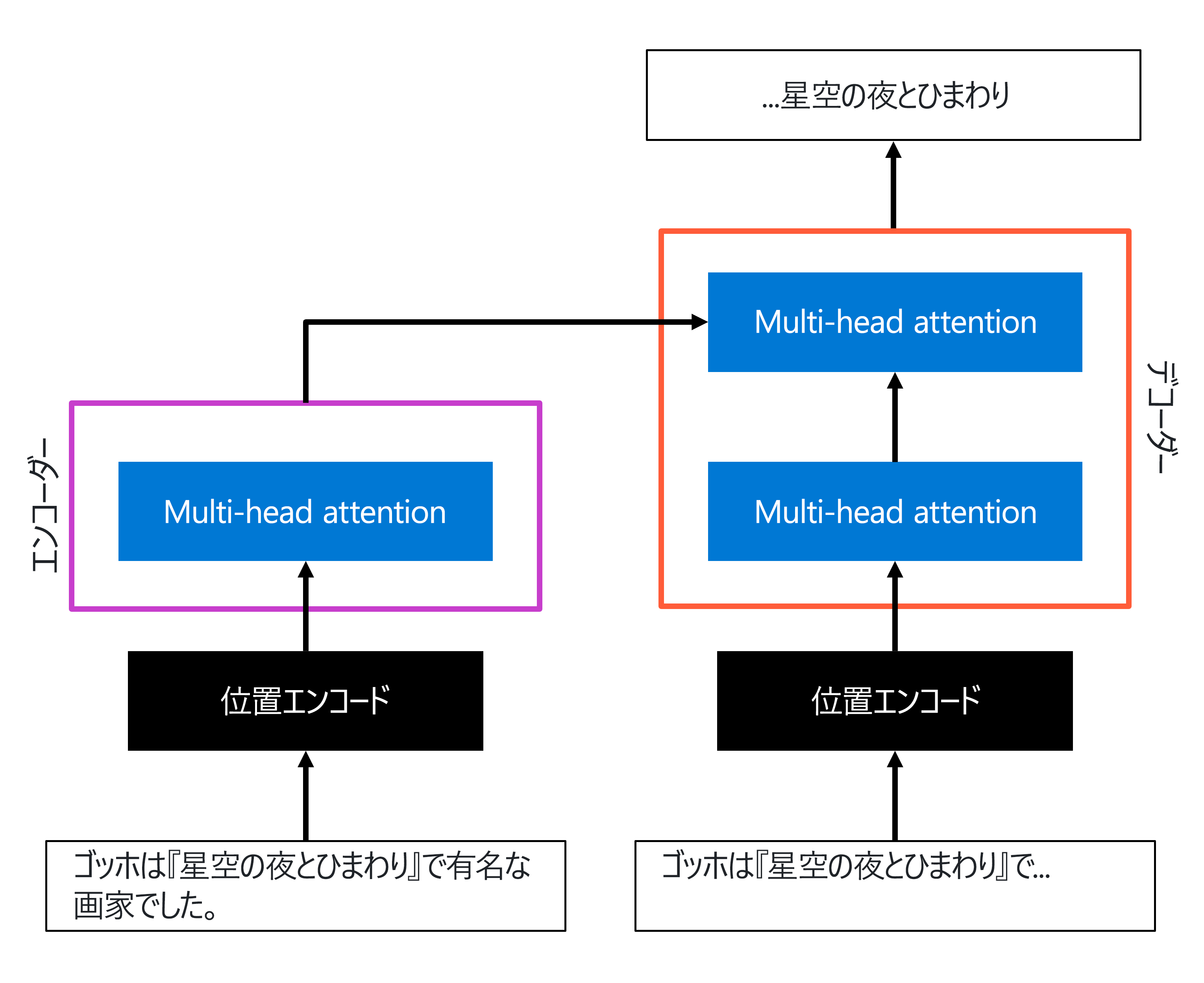
- エンコーダー レイヤーでは、入力シーケンスが位置エンコードでエンコードされ、その後、マルチヘッド アテンションを使用してテキストの表現が作成されます。
- デコーダー層では、最初に位置エンコードを使用してからマルチヘッド アテンションを使用して、(不完全な) 出力シーケンスも同様の方法でエンコードされます。 その後、デコーダー内でマルチヘッド アテンションのメカニズムをもう一度使って、エンコーダーの出力と、デコーダー部に入力として渡されたエンコードされた出力シーケンスの出力を組み合わせます。 その結果、出力を生成できます。
Transformer アーキテクチャでは、テキストを理解して生成するモデルの能力を大幅に向上させる概念が導入されました。 特定の NLP タスクに合わせて最適化するように適合させたトランスフォーマー アーキテクチャを使って、さまざまなモデルがトレーニングされています。