バッチ処理とストリーム処理を理解する
データ処理とは、プロセスを通じて生データを意味のある情報に変換することです。 データを処理するには、2 つの一般的な方法があります。
- "バッチ処理" では、複数のデータ レコードが収集されて格納された後、1 回の操作でまとめて処理されます。
- "ストリーム処理" では、データのソースが常に監視されており、新しいデータ イベントが発生するとリアルタイムで処理されます。
バッチ処理の概要
バッチ処理では、新しく到着したデータ要素が収集および格納され、グループ全体がバッチとしてまとめて処理されます。 各グループが処理される正確なタイミングは、さまざまな方法で決まります。 たとえば、スケジュールされた時間間隔 (たとえば、1 時間ごと) に基づいてデータを処理することや、特定の量のデータを受信したとき、または他のイベントの結果としてトリガーすることができます。
たとえば、道路上の車の数をカウントして交通量を分析する場合を考えてください。 これをバッチ処理で行うと、駐車場に車を集めてから、そこに止まっている間に 1 回の操作でカウントする必要があります。
多数の車が頻繁に行き交う混雑した道路の場合、この方法は実際的ではない可能性があります。また、一群の車を停車させてカウントするまで結果が得られないことに注意してください。
実際のバッチ処理の例としては、クレジット カード会社による請求の処理方法があります。 顧客は、クレジット カードの購入ごとに請求書を受け取るのではなく、その月のすべての購入について 1 か月分の請求書を受け取ります。
バッチ処理には次のような利点があります。
- 大量のデータを都合の良いときに処理できます。
- コンピューターまたはシステムが夜間などのアイドル状態になる可能性があるとき、またはオフピーク時に実行するようにスケジュールできます。
バッチ処理には次のような欠点があります。
- データの取り込みから結果の取得までの待機時間が長い。
- バッチを処理する前に、バッチ ジョブのすべての入力データの準備ができている必要があります。 つまり、データを慎重に確認する必要があります。 バッチ ジョブ中に発生するデータ、エラー、プログラム クラッシュの問題により、プロセス全体が停止します。 ジョブを再実行する前に、入力データを慎重に確認する必要があります。 小さなデータ エラーでも、バッチ ジョブの実行を妨げる可能性があります。
ストリーム処理について理解する
ストリーム処理では、新しいデータを受信するたびに処理されます。 バッチ処理とは異なり、次のバッチ処理間隔まで待つ必要はありません。データは、一度にバッチで処理されるのではなく、個々の単位としてリアルタイムで処理されます。 ストリーム データ処理は、新しい動的データが継続的に生成されるシナリオで役立ちます。
たとえば、自動車をカウントする問題の例に対するさらに優れたアプローチとしては、通過する車をリアルタイムでカウントする "ストリーミング" アプローチの適用が考えられます。
このアプローチでは、すべての車が駐車するまで待ってから処理を始める必要はなく、たとえば 1 分ごとに通過する車の数をカウントするように、一定の間隔でデータを集計できます。
現実の世界でのストリーミング データの例としては、次のようなものがあります。
- 金融機関では、株式市場の変化をリアルタイムで追跡し、バリューアットリスクを計算し、株価の変動に基づいてポートフォリオを自動的に再調整します。
- オンライン ゲーム会社では、プレーヤーとゲームの相互作用に関するリアルタイム データを収集し、そのデータをゲーム プラットフォームにフィードします。 次に、データをリアルタイムで分析し、インセンティブとダイナミックなエクスペリエンスを提供してプレーヤーを引き付けます。
- モバイル デバイスからのデータのサブセットを追跡し、地理的位置に基づいて訪問する物件をリアルタイムで推奨する不動産 Web サイト。
ストリーム処理は、即時のリアルタイム応答を必要とするタイムクリティカルな操作に最適です。 たとえば、建物の煙と熱を監視するシステムでは、火災が発生した場合に住民がすぐに脱出できるように、アラームをトリガーしてドアのロックを解除する必要があります。
バッチ データとストリーミング データの違いの概要
バッチ処理とストリーミング処理には、データを処理する方法以外にも違いがあります。
"データ スコープ": バッチ処理では、データセット内のすべてのデータを処理できます。 ストリーム処理では、通常、受信した最新のデータ、またはローリング期間内 (最後の 30 秒など) にのみアクセスできます。
"データ サイズ": バッチ処理は、大規模なデータセットを効率的に処理する場合に適しています。 ストリーム処理は、個々のレコードまたは少数のレコードで構成される "マイクロバッチ" を対象としています。
パフォーマンス: 待機時間は、データの受信と処理にかかった時間です。 通常、バッチ処理の待機時間は数時間です。 通常、ストリーム処理は直ちに実行され、待機時間は数秒または数ミリ秒です。
分析: 通常、複雑な分析を実行する場合はバッチ処理を使用します。 ストリーム処理は、単純な応答関数、集計、またはローリング平均などの計算に使用されます。
バッチ処理とストリーム処理を組み合わせる
多くの大規模な分析ソリューションでは、バッチ処理とストリーム処理が組み合わされており、履歴データとリアルタイム データの両方を分析できます。 一般的なストリーム処理ソリューションでは、リアルタイム データをキャプチャし、フィルターや集計によって処理して、リアルタイムのダッシュボードと視覚化でそれを表示しながら (たとえば、現在の 1 時間以内に道路を通過した車の累計を示します)、同時に処理された結果を、バッチ処理されたデータと合わせた履歴分析用に、データ ストアに保持します (たとえば、過去 1 年間の交通量を分析できるようにします)。
リアルタイム分析やデータの視覚化が不要な場合でも、ストリーミング テクノロジは、リアルタイム データをキャプチャし、後のバッチ処理用にデータ ストアに格納するために使用されることがよくあります (これは、道を走っているすべての車を、それらをカウントする前に駐車場に入れるのと同じです)。
次の図は、大規模なデータ分析アーキテクチャでバッチ処理とストリーム処理を組み合わせる方法を示したものです。
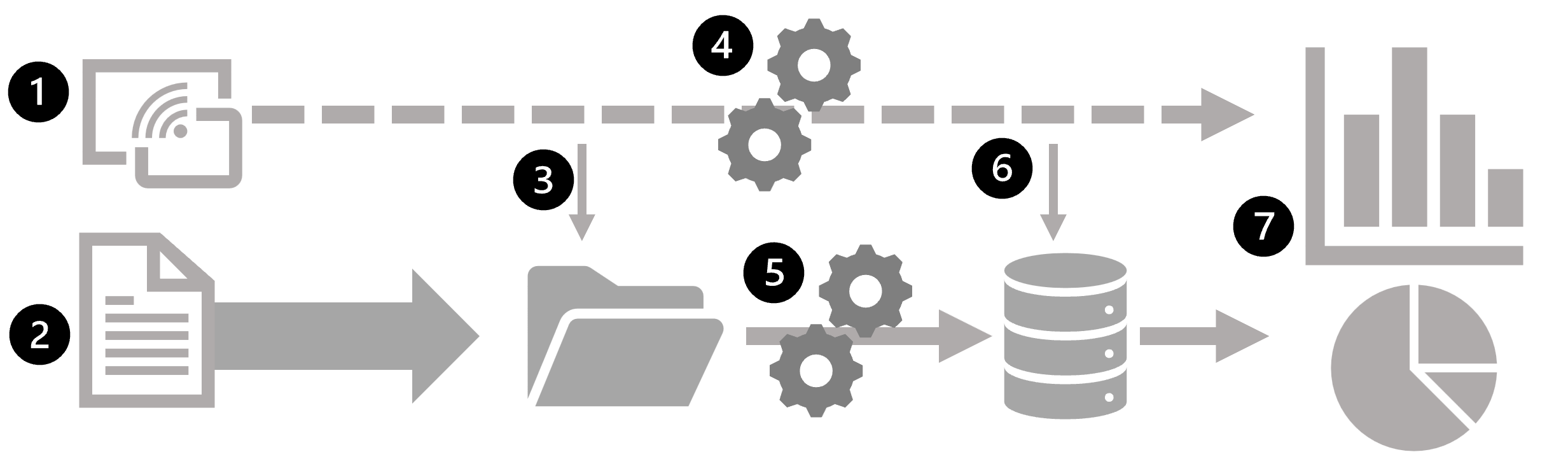
- ストリーミング データ ソースからのデータ イベントがリアルタイムでキャプチャされます。
- 他のソースからのデータは、バッチ処理のためにデータ ストア (多くの場合 "データ レイク") に取り込まれます。
- リアルタイム分析が必要ない場合、キャプチャされたストリーミング データは、後のバッチ処理のためにデータ ストアに書き込まれます。
- リアルタイム分析が必要な場合は、ストリーム処理テクノロジを使用して、リアルタイム分析または視覚化のためにストリーミング データが準備されます。多くの場合、一定期間のデータがフィルター処理または集計されます。
- 非ストリーミング データは、定期的にバッチ処理されて分析用に準備され、結果は履歴分析のために分析データ ストア ("データ ウェアハウス" とよく呼ばれます) に保持されます。
- ストリーム処理の結果も、履歴分析をサポートするために分析データ ストアに保持される場合があります。
- 分析ツールと視覚化ツールを使用して、リアルタイム データと履歴データの表示と探索が行われます。
注
バッチとストリームを組み合わせたデータ処理に一般に使用されるソリューション アーキテクチャとしては、"ラムダ" アーキテクチャと "デルタ" アーキテクチャがあります。 これらのアーキテクチャの詳細は、このコースの範囲を超えていますが、それらには大規模なバッチ データ処理とリアルタイム ストリーム処理の両方のテクノロジが組み込まれ、エンドツーエンドの分析ソリューションが作成されます。