事前構築済みモデルを使用する
Azure ドキュメント インテリジェンスの事前構築済みモデルを使用すると、独自のモデルをトレーニングすることなく、一般的なフォームの種類からデータを抽出できます。 Microsoft では、これらのモデルを多数のサンプル ドキュメントでトレーニングしているため、標準のドキュメントの種類に対して正確で信頼性の高い結果が期待できます。
ドキュメント分析モデル
ドメイン固有の事前構築済みモデルを見る前に、それらを支えるドキュメント分析モデルを理解することが重要です。
読み取りモデル
読み取りモデルは、ドキュメントや画像から印刷されたテキストと手書きのテキストを抽出します。 各テキスト行の言語を検出し、テキストが手書きか印刷かを分類します。 読み取りモデルは、他のすべてのドキュメント インテリジェンス モデルでテキスト抽出の基礎として使用されます。
複数ページの PDF または TIFF ファイルの場合は、要求で pages パラメーターを使用して、分析用のページ範囲を指定できます。
読み取りモデルは、固定構造または予測可能な構造を持たないドキュメントから単語や行を抽出する場合に最適です。
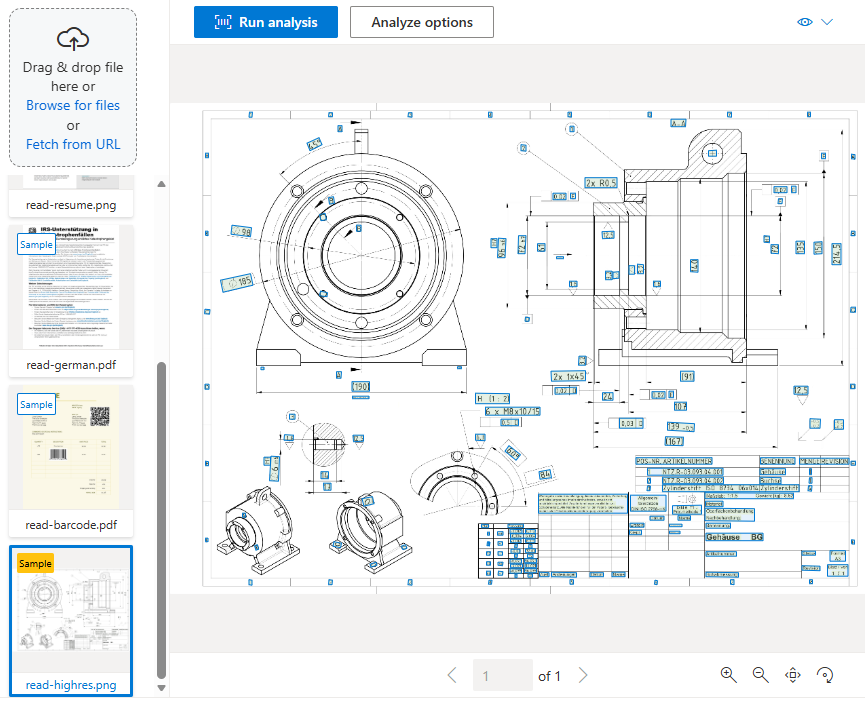
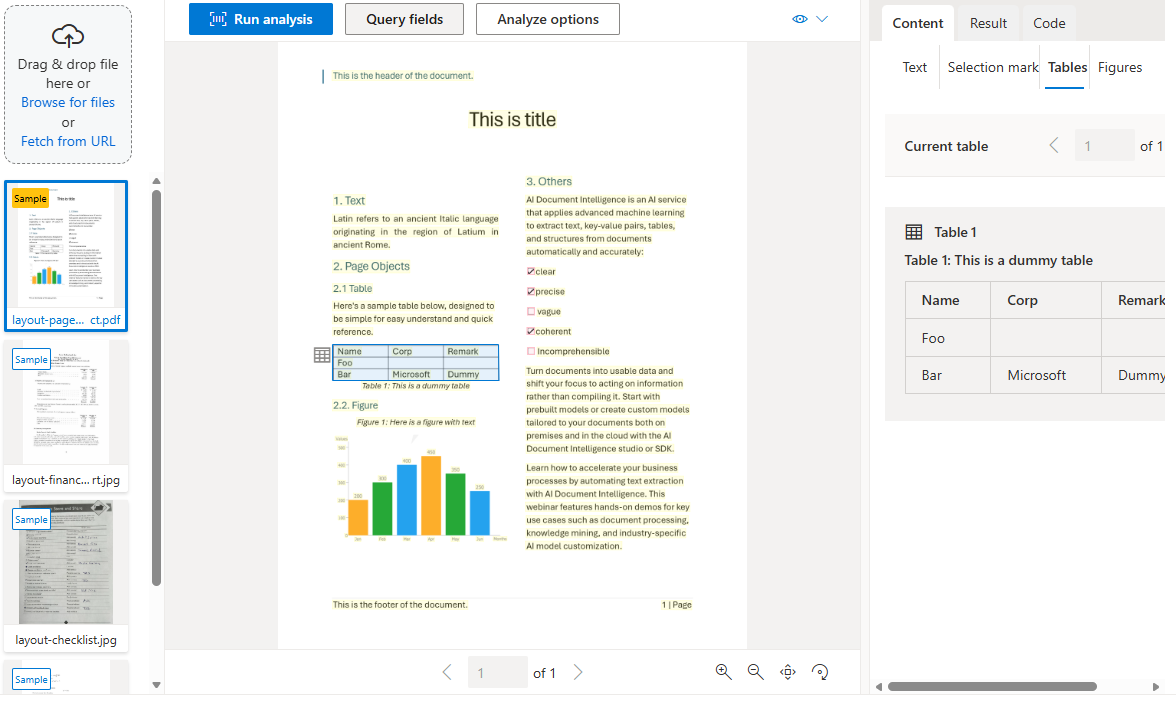
レイアウト モデル
レイアウト モデルは、選択マーク、テーブル、ドキュメント構造情報の検出を使用して、読み取りモデルのテキスト抽出を拡張します。 また、キーと値のペアを抽出するオプションの keyValuePairs 機能もサポートしています。
ドキュメントをデジタイズすると、角度が付いている場合や、結合されたセルや不完全な行を含む複雑な構造がテーブルに含まれる場合があります。 レイアウト モデルでは、これらの問題を処理できます。 各テーブル セルは、その内容、境界ボックスの位置、および行/列インデックスで抽出されます。
選択マーク (チェックボックスとラジオ ボタン) は、境界ボックス、信頼度、および選択されているかどうかの情報と共に抽出されます。
注
一般的なドキュメント モデルは、以前のバージョンのドキュメント インテリジェンスで使用できるようになりましたが、2023-10-31-preview リリースでは非推奨となりました。 キーと値のペアとエンティティ抽出の機能は、レイアウト モデルやその他の機能に組み込まれています。
特定のドキュメントの種類の事前構築済みモデル
Azure ドキュメント インテリジェンスには、特定のドキュメントの種類でトレーニングされた事前構築済みモデルが含まれています。 次の事前構築済みモデルは、一般的なビジネス ドキュメントからフィールドを抽出するために使用できるいくつかの例です。
財務および法的ドキュメント
| Model | 説明 |
|---|---|
| 請求書 | 顧客名、仕入先の詳細、発注書番号、請求書と期限、請求先住所と配送先住所、品目、合計を抽出します。 |
| 領収書 | 販売者の詳細、取引日時、品目、合計を抽出します。 単一ページのホテルレシート処理をサポートします。 |
| 銀行取引明細書 | 口座情報、期首残高と終了残高、トランザクションの詳細を抽出します。 |
| 確認事項 | 支払い先、金額、日付、およびその他の関連情報を抽出します。 |
| 給与明細 | 賃金、時間、控除、手取り額、その他の一般的な給与明細書フィールドを抽出します。 |
| クレジット カード | 支払いカード情報を抽出します。 |
| 契約 | 契約および当事者の詳細を抽出します。 |
米国税務書類
| Model | 説明 |
|---|---|
| 米国の統一税 | サポートされている米国税フォームの種類から抽出される 1 つのモデル。 |
| W-2 | 課税対象の報酬の詳細を抽出します。 |
| 1098 とバリエーション | 住宅ローンの利息と関連する詳細を抽出します。 |
| 1099 とバリエーション | さまざまなソースから収入を抽出します。 |
| 1040 とバリエーション | 個々の所得確定申告の詳細を抽出します。 |
米国の住宅ローン ドキュメント
| Model | 説明 |
|---|---|
| 1003 (URLA) | ローン申請の詳細を抽出します。 |
| 1004 (URAR) | プロパティ評価から情報を抽出します。 |
| 1005 | 雇用確認情報を抽出します。 |
| 1008 | ローン送金の詳細を抽出します。 |
| クロージング開示 | 最終締結ローン条件を抽出します。 |
本人確認書類
| Model | 説明 |
|---|---|
| 身分証明書 | 米国の運転免許証、欧州連合 ID と運転免許証、および国際パスポートから詳細を抽出します。 名前、生年月日、ドキュメント番号、保証または制限が含まれます。 |
| 医療保険カード | 米国の医療保険カードから共通フィールドを抽出します。 |
| 結婚証明書 | 認証された結婚情報を抽出します。 |
Important
ID ドキュメント モデルは、ほとんどの管轄区域でデータ保護法の対象となる個人情報を抽出します。 データを格納するための個人のアクセス許可を持ち、該当するすべての法的要件に準拠していることを確認します。
事前構築済みモデルの機能
事前構築済みモデルは、ドキュメントからさまざまな種類のデータを抽出するように設計されています。 次のような機能が含まれています。
- テキスト抽出: すべての事前構築済みモデルは、手書きテキストと印刷されたテキストから行と単語を抽出します。
- キーと値のペア: ラベルとその応答を識別するテキストのスパン。 たとえば、 Weight と 31 kg です。
- 選択マーク: チェック ボックスとラジオ ボタン (選択されているかどうかなど)。
- テーブル: 列と行の数、列と行の見出し、結合されたセルを含む、セル内のデータ。
-
フィールド: 特定のフォームの種類に対してトレーニングされたモデルは、固定されたフィールドのセットを識別します。 たとえば、請求書モデルは
CustomerNameとInvoiceTotalを抽出します。
事前構築済みモデルとカスタム モデルを使用する場合
事前構築済みモデルは、最も一般的なドキュメントの種類を対象とします。 業界固有または一意のフォームの種類がある場合は、カスタム モデルでより正確な結果が得られる可能性があります。 ただし、カスタム モデルでは、トレーニングに時間とサンプル データが必要です。 カスタム モデル開発に投資する前に、シナリオに事前構築済みモデルが存在するかどうかを常に確認してください。