ドキュメントから情報を抽出する
注
詳細については、「 テキストと画像 」タブを参照してください。
今日のビジネス プロセスは、フォーム、領収書、請求書などのドキュメントに含まれるデータに大きく依存しています。 手動処理では遅延やエラーが発生し、データ抽出の自動化がこれまで以上に重要になります。
Azure Content Understanding のしくみ
Azure Content Understanding は、構造化されていないコンテンツを取り込み、分析し、構造化データとして返すモデル駆動型抽出ワークフローに従います。
コンテンツを取り込む: コンテンツを Azure Content Understanding に送信します。
AI を利用した分析: このサービスでは、光学式文字認識 (OCR)、音声認識、自然言語理解、マルチモーダル AI モデルの組み合わせを使用してコンテンツを分析します。
構造化された出力: サービスは、モデルに一致する構造化された結果 (JSON など) を返します。そのため、データの格納、検索、またはダウンストリーム システムへの統合が簡単になります。
注
JSON (JavaScript Object Notation) は、システム間で構造化データを格納および交換するために使用されるテキストベースのデータ形式です。 人間は読み書きが簡単で、マシンが解析して生成するのは簡単です。
スキーマについて
OCR (光学式文字認識) を使用すると、コンピューターは、スキャンされたドキュメント、レシートの写真、印刷されたページの画像などの画像からテキストを読み取り、そのテキストを編集可能で検索可能なデジタル テキストに変換できます。 基本的な OCR は、印刷されたテキストを認識し、テキスト抽出に重点を置いていますが、単語間の意味、コンテキスト、または関係を理解しません。
Azure Content Understanding のドキュメント分析機能は、単純な OCR ベースのテキスト抽出を超えて、フィールドとその値の スキーマ ベース の抽出を含めます。 スキーマ駆動型のアプローチは、Azure Content Understanding と基本的な OCR または文字起こしサービスを区別する方法です。
スキーマは、 抽出する情報 とその 情報を構造化する方法を記述します。 スキーマを定義するときは、抽出するフィールドを指定します。 スキーマには、関心のある特定のフィールドまたはエンティティが一覧表示されます。
たとえば、請求書で通常見つかる共通フィールドを含むスキーマを定義するとします。次に例を示します。
- ベンダー名
- 請求書番号
- 請求日
- 顧客名
- カスタム アドレス
- アイテム - 注文されたアイテム。各アイテムには次のものが含まれます。
- 品目の説明
- 単価
- 注文済み数量
- 品目合計
- 請求書の小計
- 税金
- 送料
- 請求書の合計
次の請求書からこの情報を抽出する必要があるとします。
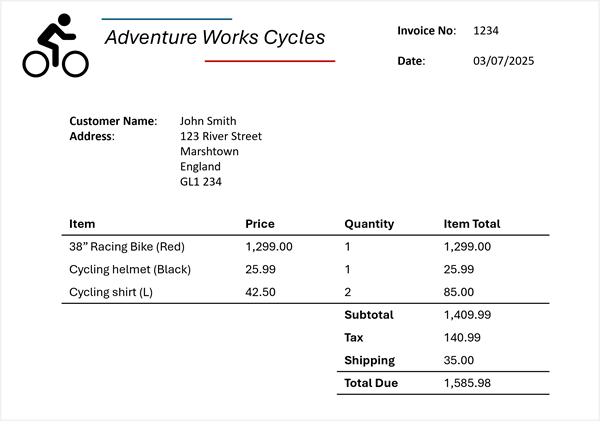
Azure Content Understanding では、請求書スキーマを請求書に適用し、異なる名前でラベル付けされている (またはまったくラベル付けされていない) 場合でも、対応するフィールドを識別できます。 結果の分析では、次のような結果が生成されます。

スキーマでは、フィールド構造も定義されます。 スキーマは、フラット テキストだけでなく、 構造化されたフィールドと入れ子になったフィールドをサポートします。 例えば次が挙げられます。
-
Itemsはコレクションです - 各項目には、
description、unit price、quantity、およびline total
構造化されたフィールドを識別すると、Azure Content Understanding は値間の関係を理解できます。OCR だけでは実行できません。
請求書の例では、検出された フィールドごとに、入れ子になった値を抽出できます。
- ベンダー名: Adventure Works Cycles
- 請求書番号: 1234
- 請求日: 2025 年 3 月 7 日
- 顧客名: John Smith
- カスタム アドレス: 123 River Street, Marshtown, England, GL1 234
-
アイテム:
- 項目 1:
- アイテムの説明: 38 インチ レーシング バイク (赤)
- 単価: 1299.00
- 注文数量: 1
- 明細合計: 1299.00
- 項目 2:
- アイテムの説明: サイクリング ヘルメット (黒)
- 単価: 25.99
- 注文数量: 1
- 明細合計: 25.99
- 項目 3:
- アイテムの説明: サイクリング シャツ (L)
- 単価: 42.50
- 注文数量: 2
- 明細合計: 85.00
- 項目 1:
- 請求書小計: 1409.99
- 税: 140.99
- 配送料: 35.00
- 請求書の合計: 1585.98
Azure Content Understanding では、ラベルだけでなく、期待される意味が抽出されます。 スキーマは 意味的に適用されます。つまり、次のようになります。
- ラベルが異なる場合でもフィールドを抽出できます
- ラベルがない場合でもフィールドを抽出できます
たとえば、 請求書番号、 請求書番号、ラベルなし番号はすべて、アナライザーが同じ概念を表していると判断した場合に InvoiceNumber にマップできます。
アナライザーについて
アナライザーは、入力を受け取り、AI 分析を適用し、構造化された結果を生成する Azure Content Understanding のユニットです。 アナライザーは、同じ抽出ロジックをすべての受信コンテンツに一貫して適用します。 構成が完了すると、アナライザーによって、すべての分析要求に対してスキーマが一貫して再利用されるようになります。 アナライザーでは、予測可能な JSON 結果も生成されます。 構造化された結果により、ダウンストリーム処理 (ストレージ、検索、自動化) が容易になります。
Azure Content Understanding には、一般的なシナリオ用の事前構築済みアナライザーが用意されており、ニーズに合わせて調整されたカスタム アナライザーがサポートされています。 概要:
- アナライザーを選択または作成します。
- アナライザーには、フィールドと構造を定義するスキーマが含まれています。
- 分析のためにコンテンツを送信する
- サービスがスキーマを適用する
- スキーマに一致する構造化された JSON 結果を受け取る
Foundry ポータルでの Azure Content Understanding の使用
注
Foundry ポータルには、 クラシック ユーザー インターフェイス (UI) と 新しい ユーザー インターフェイスがあります。
Microsoft Foundry リソースを作成したら、従来の Foundry ポータル インターフェイスを使用して Azure Content Understanding をテストできます。 Foundry ポータルには、コンテンツの例が用意されており、分析用に独自の資料をアップロードできます。
ビジュアル インターフェイスを使用して、ソース ドキュメントを選択し、既定の情報フィールドを抽出できます。 たとえば、ドキュメントの画像で Azure Content Understanding を試してみると、サービスはドキュメントテキストとテキストレイアウト情報を返します。

Azure Content Understanding のアナライザーは、ドキュメント内のテキスト値を識別し、それらを特定のフィールドにマップします。 たとえば、請求書を指定すると、サービスはフィールド (仕入先住所など) とフィールドのデータ (123 456th Street など) を返します。

Foundry ポータルでは、処理の JSON 結果を表示することもできます。

Azure Content Understanding を使用したクライアント アプリケーションの構築
Content Understanding API を使用して、プログラムによってデータを抽出する軽量クライアント アプリケーションを構築できます。
注
クライアント アプリケーションは、ユーザーのデバイス上で実行され、ネットワーク経由で別のシステム (通常はサーバー) からサービスまたはデータを要求するソフトウェア プログラムです。 クライアントは、ユーザーが操作するアプリケーションの一部ですが、サーバーはバックグラウンドで大量の作業を行います。 アプリケーションは、サービスからデータまたはアクションを要求し、API を使用して構造化された応答を受け取ることができます。
Content Understanding API を使用する場合は、事前構築済みのアナライザーを選択するか、カスタム アナライザーを作成できます。 事前構築済みのアナライザーには、 prebuilt-invoice、 prebuilt-imageSearch、 prebuilt-audioSearch、および prebuilt-videoSearchが含まれます。 分析用のコンテンツをアナライザーに送信すると、分析は 非同期になります。つまり、準備ができたら後で結果を取得します。 解析は非同期で行われるため、ジョブが成功するまで Operation-Location URL または をanalyzerResultsする必要があります。
Azure Content Understanding Python SDK の使用
Python SDK を使用して URL から請求書を分析するプロセスを見てみましょう。
- Azure Content Understanding Python SDK をインストールします。
python -m pip install azure-ai-contentunderstanding
Foundry リソース エンドポイントと API キーまたは Microsoft Entra ID を識別します。 通常、エンドポイントは次のようになります。
https://<your-resource-name>.services.ai.azure.com/クライアント アプリケーション コードを作成して実行します。
analzyer_idは、事前構築済みのアナライザーの ID です。 事前構築済みのアナライザー ID 値の一覧 については、こちらをご覧ください。
import os
from azure.ai.contentunderstanding import ContentUnderstandingClient
from azure.core.credentials import AzureKeyCredential
endpoint = os.environ["FOUNDRY_ENDPOINT"]
key = os.environ["FOUNDRY_KEY"]
client = ContentUnderstandingClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 1) start analysis with analyzer id + inputs
analyzer_id = "prebuilt-invoice"
inputs = [
{"url": "https://github.com/Azure-Samples/azure-ai-content-understanding-python/raw/refs/heads/main/data/invoice.pdf"}
]
# 2) wait for the Long Running Operation (LRO) to complete
poller = client.begin_analyze(analyzer_id=analyzer_id, inputs=inputs) # starts LRO
result = poller.result() # waits for completion (polling handled by SDK)
# 3) read structured fields + markdown
# The result typically includes extracted "fields" and "markdown" per input content item.
for content in result.contents:
print(content.markdown)
print(content.fields)
結果の出力は、抽出されたマークダウン、フィールド、フィールド内のデータ、信頼度スコアを示す JSON です。 例えば次が挙げられます。
{
"status": "Succeeded",
"result": {
"analyzerId": "prebuilt-invoice",
"apiVersion": "2025-05-01-preview",
"contents": [
{
"markdown": "# INVOICE\n\nCONTOSO LTD.\n\nContoso Headquarters\n123 456th St\nNew York, NY, 10001\n\nINVOICE: INV-100\n\nINVOICE DATE: 11/15/2019\n\nDUE DATE: 12/15/2019\n\nCUSTOMER NAME: MICROSOFT CORPORATION\n",
"fields": {
"CustomerName": {
"type": "string",
"valueString": "MICROSOFT CORPORATION",
"confidence": 0.95,
},
"InvoiceDate": {
"type": "date",
"valueDate": "2019-11-15",
"confidence": 0.994,
}
}
}
]
}
}
次に、Azure Content Understanding アナライザーを使用して、オーディオとビデオから構造化データを抽出する方法について説明します。