Hyperscale の機能を確認する
Azure SQL Database の Hyperscale サービス レベルは、ビジネス ワークロードに最適な仮想コアベースの購入モデルにおけるサービス レベルです。 これは、拡張性の高いストレージおよびコンピューティング パフォーマンス レベルであり、Azure を利用して、General Purpose および Business Critical サービス レベルの制限を大きく超えて、Azure SQL Database 用のストレージおよびコンピューティング リソースをスケールアウトします。 クエリ処理エンジンが長期的なストレージ コンポーネントから切り離されるため、コンピューティング リソースとストレージ リソースのシームレスなスケーリングが可能になります。
Hyperscale を使用すると、インフラストラクチャとアプリケーションの設計が簡素化され、開発者はデータベース リソースの管理ではなく、ビジネス ニーズに集中できるようになります。
Azure SQL Database には、データベースあたりのストレージが 4 TB という制限がありましたが、 Hyperscale サービス レベルでは、データベースは 100 TB を超えることができます。 Hyperscale では、水平スケーリングを使用して、データの増加に応じてコンピューティング ノードを追加します。 コストは通常の Azure SQL Database に似ていますが、テラバイト単位の追加のストレージ コストがあります。
利点を把握する
Hyperscale サービス レベルを使用すると、クラウド データベースにおいて従来見られた実際の制限の多くが取り除かれます。 1 つのノードのリソースによって制約されている他のほとんどのデータベースとは異なり、Hyperscale データベースにはそのような制限はありません。 柔軟なストレージ アーキテクチャにより、ストレージは必要に応じて拡張され、定義済みの最大サイズがなくなります。 使用した容量の分だけ料金で済みます。 読み取り集中型ワークロードでは、追加のレプリカをプロビジョニングして読み取り操作をオフロードすることで、Hyperscaleは迅速にスケールアウトします。
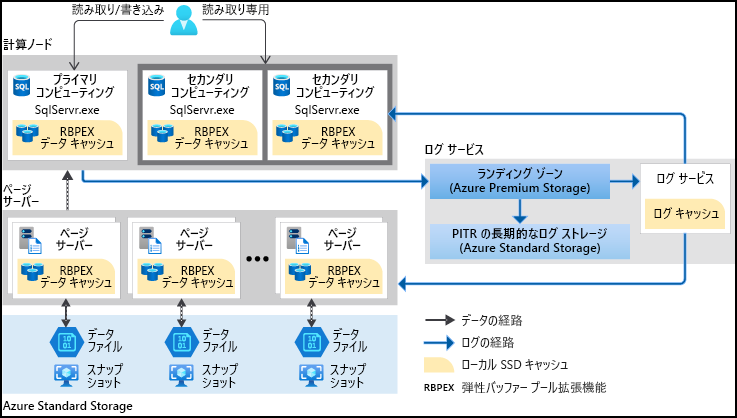
さらに、データベース バックアップの作成に必要な時間や、スケールアップまたはスケールダウンに必要な時間は、データベース内のデータの量に依存しなくなっています。 Hyperscale データベースは瞬時にバックアップできます。 また、数十テラバイトのデータベースを、数分でスケールアップまたはスケールダウンできます。 この機能により、初期構成の選択によって縛り付けられることを心配する必要はなくなります。 Hyperscale では、数時間または数日もかからず、数分で完了する高速なデータベース復元も提供されます。
ハイパースケールでは、ワークロードの需要に基づいて迅速なスケーラビリティを提供します。
| 機能 | 説明 | ベネフィット | 使用事例 |
|---|---|---|---|
| スケールアップ/スケールダウン | CPU やメモリなどのリソースの観点で主要なコンピューティング サイズをスケールアップしてから、一定時間でスケールダウンできます。 ストレージは共有されるため、スケールアップとスケールダウンはデータベース内のデータ量にリンクされません。 | リソース管理における柔軟性と効率性を保証します。 | さまざまなレベルのコンピューティング能力を必要とするさまざまなワークロードを処理するアプリケーションに最適です。 |
| スケールイン/スケールアウト | 読み取り要求を処理するために、1 つ以上のコンピューティング レプリカをプロビジョニングすることもできます。 これらの追加のコンピューティング レプリカは読み取り専用レプリカとして機能するため、プライマリ コンピューティングから読み取りワークロードをオフロードできます。 さらに、これらのレプリカはホット スタンバイとして機能し、プライマリ コンピューティング エラーが発生した場合に引き継ぐ準備ができています。 | 読み取りワークロードをオフロードし、フェールオーバー機能を提供することで、パフォーマンスと信頼性が向上します。 | 高可用性と迅速なフェールオーバーを必要とする読み取り集中型アプリケーションに適しています。 |
パフォーマンス最大化
Hyperscale サービス レベルは、クラウドに移行してアプリケーションを最新化する大規模なオンプレミスの SQL Server データベースをお持ちのお客様向けに設計されています。 また、データベースの潜在的な大幅な拡張に対応したい Azure SQL Database を既に使用しているお客様にも最適です。 さらに、Hyperscale は、高パフォーマンスと高いスケーラビリティの両方を求めるユーザーに最適です。
高速なスケーリング機能に加え、Hyperscale には、次のパフォーマンス機能が用意されています。
- データベース バックアップは、サイズに関係なくほぼ瞬時に実行されます。コンピューティング リソースには影響しません。
- データベースの復元は数時間や数日ではなく、数分で完了します。
- データ ボリュームに関係なく、トランザクション ログ スループットの向上やトランザクション コミット時間の短縮により、全体的なパフォーマンスが拡張されています。
注
Azure SQL Database に Hyperscale データベースをデプロイするには:
Azure SQL Database Hyperscale のデプロイ
Hyperscale サービス レベルで Azure SQL Database をデプロイするには、以下の手順を実行します。
Azure portal にサインインします。
[Azure SQL] ページに移動し、[+ 作成] を選択します。
[SQL Database]、[単一データベース]、[作成] ボタンの順に選択します。
[SQL Database の作成] ページの [基本] タブで、目的のサブスクリプション、リソース グループ、およびデータベース名を選択します。
サーバーの [新規作成] リンクを選択し、サーバー名、サーバー管理者のログインとパスワード、場所などの新しいサーバーに関する情報を入力します。
[コンピューティングとストレージ] で、[データベースの構成] リンクを選択します。
[サービス レベル] に [Hyperscale] を、[コンピューティング レベル] に [プロビジョニング済み] を選択します。
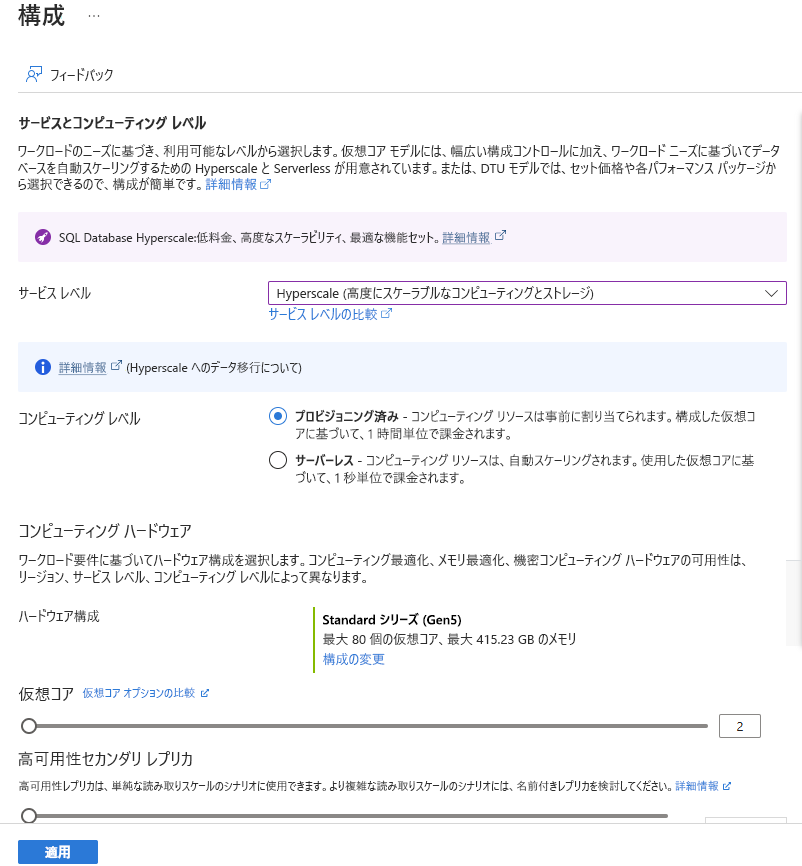
[ハードウェア構成] で、[構成の変更] リンクを選択します。 使用可能なハードウェア構成を確認し、お使いのデータベースに最適な構成を選択します。 この例では、既定のオプション [スタンダード シリーズ (Gen5)] のままにします。
必要に応じて、データベースの仮想コアの数を増加する場合は、[仮想コア] のスライダーを調整します。
[高可用性セカンダリ レプリカ] スライダーを調整して、1 つのレプリカを作成します。 適用を選択します。
ページの下部にある [Next: Networking](次へ: ネットワーク) を選択します。
[ネットワーク] タブで、[現在のクライアント IP アドレスを追加する] を [はい] に設定します。
[確認と作成] ボタンを選択し、[作成] を選択します。
![Azure SQL Database Hyperscale をプロビジョニング時の [確認と作成] ページのスクリーンショット。](../../wwl-data-ai/get-started-sql-database-application-development/media/3-create-button.png)
注
データベースを Hyperscale に変換した後、それを通常の Azure SQL Database に戻すことはできません。 Hyperscale の制限の詳細については、Hyperscale サービス レベルの既知の制限に関する記事を参照してください。
読み取り専用レプリカに接続する
読み取り専用レプリカに接続するには、接続文字列の ApplicationIntent 引数を ReadOnly に設定します。 ReadOnly のアプリケーションの目的を持つ接続はすべて、読み取り専用コンピューティング レプリカのいずれかに自動的にルーティングされます。
Server=tcp:<your_server_name>.database.windows.net,1433;Database=<your_database_name>;User ID=<your_username>@<your_server_name>;Password=<your_password>;Encrypt=true;Connection Timeout=30;ApplicationIntent=ReadOnly;