トレーニング可能な分類子を調べる
組織は、コンテンツを保護して適切に処理できるように、コンテンツを分類してラベル付けします。 コンテンツを分類してラベル付けすることは、情報保護の訓練の出発点です。 Microsoft 365 には、コンテンツを分類する 3 つの方法があります。
手動。 手動分類には、人間の判断とアクションが必要です。 ユーザーと管理者は、遭遇したコンテンツをそれらに適用します。 既存のラベルと機密情報の種類を使用することも、カスタムで作成したものを使用することもできます。 その後、コンテンツを保護し、その処分を管理できます。
自動パターン マッチング。 この分類メカニズムのカテゴリには、次によるコンテンツの検索が含まれます。
- キーワードまたはメタデータ値 (キーワード クエリ言語)。
- 社会保障番号、クレジット カード番号、銀行口座番号など、以前に特定された機密情報のパターンを使用します。
- テンプレート上のバリエーションであるアイテムを認識します (このトレーニングの後の単元で取り上げるドキュメントのフィンガープリント)。
- 正確な文字列の存在を使用します (完全なデータ一致)。
トレーニング可能な分類子。 Microsoft 365 トレーニング可能な分類子は、組織がさまざまな種類のコンテンツを認識するために "トレーニング" できるツールです。 Microsoft 365 には、定義済みの分類子の広範なリストが含まれています。 組織は、独自のカスタム分類子を作成することもできます。 分類子をトレーニングするには、それらが調べるサンプルを与えます。 分類子をトレーニングすると、組織はそれを使って、Office 秘密度ラベル、通信コンプライアンス ポリシー、および保持ラベル ポリシーの適用項目を識別できます。
この単元では、トレーニング可能な分類子の使用法を調べます。
トレーニング可能な分類子
Microsoft Purview でトレーニング可能な分類子の使用を開始するには、まずスキャン プロセスを開始します。 このプロセスは、会社のデータを分析し、分類子のトレーニングにシステムが使用できるパターンを識別します。 システムがデータをスキャンすると、共通のテーマとパターンが識別されます。 その後、システムはこの情報を使用して、トレーニング可能な分類子のルールを作成できます。 このプロセスは、トレーニング可能な分類子が正確で、データの識別と分類に効果的であることを保証するのに役立ちます。 スキャン プロセスが完了したら、識別されたパターンとルールを使用してトレーニング可能な分類子をトレーニングできます。 分類子のトレーニングが完了したら、それを新しいデータに適用して自動的に分類できます。
警告
スキャンが完了するまでに 7 日から 14 日かかる場合があります。 スキャン プロセスを実行して組織のカスタム トレーニング分類子を作成したくない場合は、Microsoft Purview の組み込み分類子を使用できます。
Microsoft Purview コンプライアンス ポータルの [Training classifiers] (分類子のトレーニング) ページに初めてアクセスすると、次のスクリーンショットが表示されます。
![Microsoft Purview コンプライアンス ポータルの [training classifiers] (分類子のトレーニング) ページに初めてアクセスするときに表示されるダイアログ ボックスのスクリーンショット。](../../wwl/implement-data-classification-sensitive-information/media/trainable-classifiers-start-window-c6fd14df-60a000d0.png)
カスタム トレーニング可能な分類子を作成するには、まず、手動で選択し、カテゴリに肯定的に一致するサンプルを提供する必要があります。 次に、トレーニング可能な分類子ツールがそれらのサンプルを処理した後、正と負のサンプルを組み合わせて与えることによって、分類子の予測能力をテストします。 この単元では、カスタム分類子を作成してトレーニングする方法について説明します。 また、再トレーニングを通じて、カスタム トレーニング可能な分類子と事前トレーニング済み分類子のパフォーマンスを全存続期間にわたって向上させる方法についても説明します。
分類方法は、自動または手動のパターン マッチング方法では簡単に識別できないコンテンツに対して適切に機能します。 この分類方法は、アイテムに含まれる要素 (パターン マッチング) ではなく、アイテムが何であるかに基づいてアイテムを識別するように分類子を使用することです。 分類子は、そのコンテンツ タイプの数百の例を見て、コンテンツのタイプを識別する方法を学びます。
注:
コンテンツ エクスプローラー ツールでトレーニング可能な分類子を表示するには、フィルター パネルで [トレーニング可能な分類子] を展開します。 トレーニング可能な分類子は、ラベル付けを必要とせずに、SharePoint、Teams、OneDrive で見つかったインシデントの数を自動的に表示します。 この機能を使用しない場合は、既成の分類を無効にするために、Microsoft サポートで要求を提出する必要があります。 これにより、ラベル付けポリシーを作成する前に、機密性の高いラベル付けされたコンテンツのスキャンが無効になります。
分類子は、次の条件として使用できます。
- 秘密度ラベル付きの Office の自動ラベル付け
- 条件に基づくアイテム保持ラベル ポリシーの自動的な適用
- コミュニケーション コンプライアンス
注:
分類子は、暗号化されていないアイテムでのみ機能します。
トレーニング可能な分類子には、次の 2 種類があります。
- 事前トレーニングされた分類子。 Microsoft では、トレーニングなしで使用を開始できる複数の分類子を作成し、事前トレーニングしました。 これらの分類子は、[使用準備完了] の状態で表示されます。
- カスタム トレーニング可能な分類子。 事前トレーニングされた分類子がカバーする範囲を超える分類のニーズが組織にある場合、独自の分類子を作成してトレーニングできます。
以降のセクションでは、これらの分類子の種類について説明します。
事前トレーニングされた分類子
Microsoft 365 には、複数の事前トレーニングされた分類子が付属しています:
成人向け、きわどい、残酷。 これらの種類の画像を検出します。 イメージのサイズは、50 KB から 4 MB の範囲である必要があります。 また、高さ x 幅の寸法が 50 x 50 ピクセルを超える必要があります。 システムは、Exchange Online メール メッセージと、Microsoft Teams のチャネルおよびチャットのスキャンと検出をサポートします。
契約。 この分類子は、法的契約に関連するコンテンツを検出します。 たとえば、作業明細書、ローン契約とリース契約、雇用および競業避止契約などです。
顧客の苦情。 顧客の苦情分類子は、組織の製品またはサービスに関するフィードバックと苦情を検出します。 この分類子は、消費者金融保護局や食品医薬品局の要件など、苦情の検出とトリアージに関する規制要件を満たすのに役立ちます。
差別。 この分類子は、明らかに差別的な言葉を検出し、他のコミュニティと比較してアフリカ系アメリカ人や黒人コミュニティを差別する言葉に敏感です。
財務。 この分類子は、企業財務、会計、経済、銀行、投資カテゴリのコンテンツを検出します。
嫌がらせ。 この分類子は、攻撃的な言語テキスト アイテムの特定のカテゴリを検出します。 これらのアイテムは、人種、民族、宗教、国籍、性別、性的指向、年齢、障碍などの特性に基づいて、1 人または複数の個人を対象とした攻撃的な行為に関連する必要があります。
医療。 この分類子は、医療および健康管理の側面のコンテンツを検出します。 たとえば、医療サービス、診断、治療、クレームなどです。
人事 (HR)。 この分類子は、人事関連カテゴリのコンテンツを検出します。 たとえば、採用、面接、採用、トレーニング、評価、警告、解雇などです。
知的財産 (IP)。 この分類子は、企業秘密や同様の機密情報など、知的財産関連カテゴリのコンテンツを検出します。
情報技術 (IT)。 この分類子は、情報技術カテゴリとサイバーセキュリティ カテゴリのコンテンツを検出します。 たとえば、ネットワーク設定、情報セキュリティ、ハードウェア、ソフトウェアなどです。
法務。 この分類子は、法務関連カテゴリのコンテンツを検出します。 たとえば、訴訟、法的手続き、法的義務、法律用語、法律、立法などです。
調達。 この分類子は、商品やサービスの供給に対する入札、見積もり、購入、支払いのカテゴリのコンテンツを検出します。
冒涜的表現。 この分類子は、ほとんどの人を困惑させる表現を含む不快な言葉のテキスト アイテムの特定のカテゴリを検出します。
履歴書。 この分類子は、申請者の個人的、教育的、専門的資格、実務経験、その他の個人を特定する情報のテキスト アカウントである docx、.pdf、.rtf、および .txt アイテムを検出します。
ソース コード。 この分類子は、GitHub で使用されている上位 25 のコンピューター プログラミング言語 (ActionScript、C、C#、C++、Clojure、CoffeeScript、Go、Haskell、Java、JavaScript、Lua、MATLAB、Objective-C、Perl、PHP、Python、R、Ruby、Scala、Shell、Swift、TeX、Vim スクリプト) で記述された命令とステートメントのセットを含むアイテムを検出します。
注:
ソース コード分類子は、テキストの大部分がソース コードである場合に検出します。 プレーン テキストが散在するソース コード テキストは検出されません。
税。 この分類子は、税計画、税フォーム、税務書類、税規制などの税関係のコンテンツを検出します。
脅威。 この分類子は、暴力を振るったり、人や物に物理的な被害を与えたりする脅威に関連する攻撃的な言葉のテキスト アイテムの特定のカテゴリを検出します。
これらのトレーニング可能な分類子は、Microsoft Purview コンプライアンス ポータルに表示されます。 ナビゲーション ウィンドウで、[データ分類] を選択します。 [データ分類] ページで、[トレーニング可能な分類子] タブを選択します。[使用準備完了] の状態の分類子が表示されます。
カスタム分類子
一部の組織では、事前トレーニングされた分類子ではデータ分類のニーズを満たしていません。 このような状況では、組織は独自の分類子を作成してトレーニングできます。 カスタム分類子の作成にはさらに多くの作業が伴いますが、組織はニーズに合わせてカスタマイズできます。 カスタム分類子の作成に関連する大まかな手順は次のとおりです。
- カスタム トレーニング可能な分類子の作成は、間違いなくそのカテゴリに含まれる例をそれに与えることから始めます。
- 分類子がそれらの例を処理したら、一致する例と一致しない例の両方を組み合わせて与えてテストします。
- 次に、分類子は、特定のアイテムが作成中のカテゴリに該当するかどうかを予測します。
- その後、その結果を確認し、真の陽性、真の陰性、偽陽性、偽陰性に仕分けし、その予測の正確性を高めます。
- テスト結果に満足したら、分類子を発行してデプロイします。
分類子を公開すると、SharePoint Online、Exchange、OneDrive などの場所にあるアイテムが並べ替えられ、コンテンツが分類されます。 分類子を発行した後も、最初のトレーニング プロセスと同様のフィードバック プロセスを使用してトレーニングを続けることができます。
たとえば、次のトレーニング可能な分類子を作成できます。
- 法的文書。 たとえば、弁護士クライアント特権、決算セット、作業明細書などです。
- 戦略的ビジネス文書。 たとえば、プレス リリース、合併と買収、取引、ビジネスまたはマーケティング計画、知的財産、特許、設計ドキュメントなどです。
- 価格情報。 たとえば、請求書、価格見積もり、作業指示書、入札書類などです。
- 財務情報。 たとえば、組織の投資、四半期または年次の結果などです。
カスタム トレーニング可能な分類子の準備
開始する前に、カスタム トレーニング可能な分類子の作成に関連するコンポーネントを理解しておくと役立ちます。 以降のセクションでは、これらの各コンポーネントについて説明します。
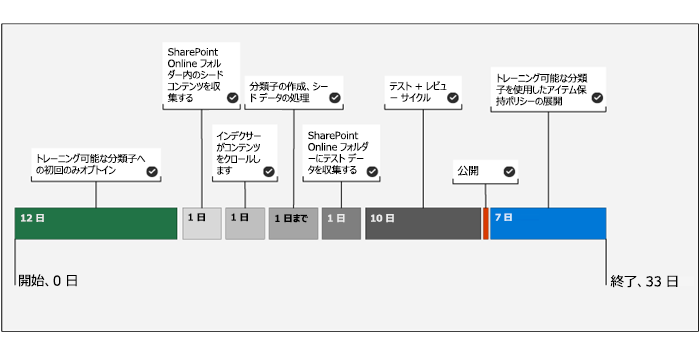
タイムライン
次の図は、トレーニング可能な分類子のサンプル デプロイを反映したタイムラインを示しています。
ヒント
システムでは、トレーニング可能な分類子の初回オプトインのみが必要です。 Microsoft 365 が組織のコンテンツのベースライン評価を完了するまでに 12 日かかります。 Microsoft 365 グローバル管理者がオプトイン プロセスを開始する必要があります。
全体的なワークフロー
カスタム トレーニング可能な分類子を作成するワークフロー全体の詳細については、「カスタム トレーニング可能な分類子を作成するためのプロセス フロー」を参照してください。
シード コンテンツ
Microsoft Purview では、トレーニング可能な分類子を使用して、アイテムを特定のカテゴリのコンテンツとして個別かつ正確に識別します。 トレーニング可能な分類子を作成するには、組織はまず、カテゴリに含まれるコンテンツの種類の多くのサンプルを提示する必要があります。 シード処理は、トレーニング可能な分類子にサンプルを供給するプロセスです。 組織は、コンテンツのカテゴリを表すために使用するシード コンテンツを選択する必要があります。
ヒント
正のサンプルが少なくとも 50 個、最大で 500 個必要です。 サンプル。 トレーニング可能な分類子は、最新の 500 個のサンプル (ファイル作成日時スタンプによる) まで処理します。 提供するサンプルが多いほど、分類子が行う予測の精度が高くなります。
コンテンツのテスト
トレーニング可能な分類子が予測モデルを構築するのに十分な正のサンプルを処理したら、組織は分類子が行う予測をテストする必要があります。 最初に指定した初期シード データとは異なるデータでテストする必要があります。 テストでは、分類子がカテゴリに一致するアイテムと一致しないアイテムを正しく区別できるかどうかを確認する必要があります。 テストは、テスト サンプルと呼ばれる、手動で選択したコンテンツの別の (できれば大きい) セットを選択することから始める必要があります。 そのカテゴリに分類されるサンプルと、分類されないサンプルで構成する必要があります。
分類子がこのテスト サンプルを処理したら、結果を手動で確認する必要があります。 その際に、各予測が正しいか正しくないか、わからないかを確認する必要があります。 トレーニング可能な分類子は、このフィードバックを使用して予測モデルを改善します。
ヒント
最適な結果を得るには、テスト サンプルに少なくとも 200 個のアイテムを含めます。 正の一致と負の一致の均等な分布を含める必要があります。