クラスターの共有ボリュームの定義
幅広い高可用性シナリオに対応するには、分散アクセス ファイル システムのサポートがクラスタリング テクノロジに含まれている必要があります。 これにより、データの破損を発生させることなく、複数のクラスター ノード間で共有されたストレージに対して効率的で調整されたアクセスが可能になります。 Windows Server では、CSV を使用してこのようなサポートが実装されています。
クラスターの共有ボリュームとは
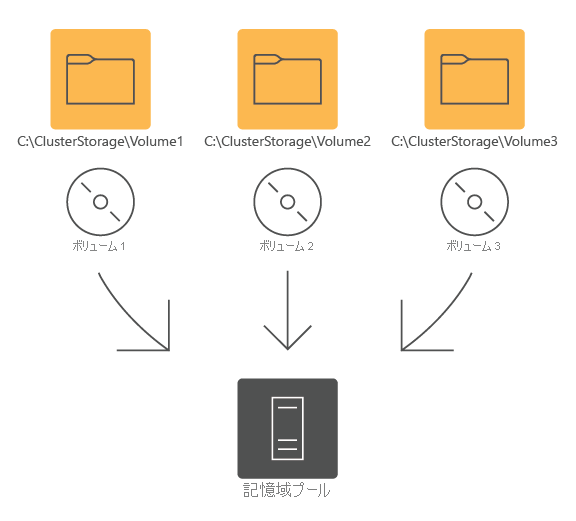
CSV は汎用のクラスター化ファイル システム (CSVFS と呼ばれます) であり、これを使用すると複数のクラスター ノードが同じ NT ファイル システム (NTFS) または Resilient File System (ReFS) ボリュームのセットに対して同時に読み取りと書き込みを行うことができます。 CSV では、クラスター ノードに接続されているディスクでホストされているボリュームが、各クラスター ノードの C:\ClusterStorage\ ディレクトリにマップされます。 この方法では、1 つの名前空間が提供され、クラスター内の任意のノードで同じ名前とパスを使用して CSV のすべてのコンテンツを利用できます。
CSV の機能
同時ボリューム アクセスが可能になることにより、負荷分散がより均等化され、ドライブの所有権の変更やボリュームのマウント解除と再マウントの必要性をなくすことで、フェールオーバーが速くなります。 また、CSV には次の機能が用意されています。
- オンラインでの chkdsk のサポート。 chkdsk 操作はオンラインで実行され、ファイル システムでハンドルが開いているワークロードに影響しません。
- BitLocker ドライブ暗号化のサポート。 BitLocker を使用して、従来のクラスター化されたディスクと CSV ベースのボリュームの両方のボリュームを暗号化できます。
- SMB マルチチャネルおよび SMB ダイレクトとの統合。 これにより、CSV トラフィックがクラスター内の複数のネットワークを経由でき、リモート ダイレクト メモリ アクセス (RDMA) をサポートするネットワーク アダプターを活用することができます。
- 記憶域スペースとの統合。 これにより、汎用的なハードウェアを持つクラスターで仮想化されたストレージを使用できます。
- オンラインでボリュームをスキャンおよび修復する機能。 CSV では、chkdsk、fsutil、
Repair-VolumeWindows PowerShell コマンドレットなどのツールを使用するときに、ダウンタイムなしでボリュームをスキャンして修復できます。 - 拡張された CSV の回復性。 Windows Server では、サーバー サービスの複数のインスタンスが実装されるため、ノード間の SMB トラフィックの回復性とスケーラビリティが向上します。 サーバー サービスの既定のインスタンスでは通常のファイル共有にアクセスする要求を受け入れ、追加のインスタンスではノード間の CSV トラフィックが管理されます。
CSV では、主に次の 2 種類のワークロードがサポートされます。
- クラスター化された Microsoft Hyper-V VM (仮想ハード ディスク (VHD) ファイルを含む)。
- SOFS のクラスター化された役割のアプリケーション データをホストするスケールアウト ファイル共有。
CSV を使用すると、複数の VM のディスク ファイルを 1 つのボリュームに格納し、任意のクラスター ノード上の任意の場所でその VM を実行できます。 さらに、CSV ではライブ マイグレーション機能が高速化され、VM を別のノードに移動するときにディスクの所有権を変更する必要がなくなり、移行プロセスのパフォーマンスと安定性が向上します。
各ノードはボリューム上の個々のファイルから個別に読み取ったり書き込んだりできますが、1 つのノードがボリュームの CSV 所有者 (または コーディネーター) として機能します。 そのノードによって、ボリュームのマウントがホストされます。 個々のボリュームを特定の所有者に割り当てるオプションがありますが、フェールオーバー クラスターではクラスター ノード間で CSV の所有権が自動的に分散されます。 この分散メカニズムでは、各ノードで所有される CSV の数が考慮されます。 クラスター サービスでは、ノードの追加、削除、再起動などの変更の後に、所有権が再調整されます。
ある CSV ボリュームでファイル システムのメタデータの変更が行われた場合、その変更を実装して、オーケストレーションを管理し、そのボリュームにアクセスするすべてのクラスター ノードでそれらを同期する責務は所有者にあります。 このような変更には、ボリューム上に存在する VM ディスク ファイルの開始、作成、移行、削除などがあります。 メタデータの更新では、所有者以外のクラスター ノードから、ボリュームをホストしている共有ストレージへの直接通信は行われません。
対照的に、CSV ボリュームで開かれているファイルへの標準の書き込み操作と読み取り操作は、メタデータに影響しません。 実質的には、基になる記憶域に直接接続できる各クラスター ノードは、そのボリュームの CSV 所有者に依存することなく、個別にそれらを実行できます。 メタデータの更新とは異なり、このような操作によって、ほとんどのストレージ アクティビティが構成されています。
また、所有者ノードを使用すると、特定のノードがストレージと直接通信できなくなるストレージ接続障害やストレージ操作の悪影響を最小限に抑えることができます。 このようなイベントが発生した場合、基になるストレージと通信する必要があるノードによって、クラスター ネットワークを介して、対応するボリュームの所有者ノードにディスク I/O がリダイレクトされます。 現在のコーディネーター ノードでストレージ接続障害が発生した場合は、クラスターによってコーディネーターの役割が新しいノードに自動的に割り当てられている間、すべてのディスク入出力操作が一時的にキューに入れられます。
CSV の計画
CSV を使用するには、ストレージとディスクで次の要件が満たされている必要があります。
- ファイル システム形式とディスク構成。 CSV ボリュームのディスクまたは記憶域スペースは、NTFS または ReFS 形式のベーシック ディスクを使用するものであることが必要です。 記憶域スペースを使用する場合は、単純な領域、ミラー領域、またはパリティ領域を構成できます。
- 物理ディスクのクラスター リソース。 CSV ボリュームは、物理ディスクのリソースの種類に依存します。 物理ディスクのリソースの種類を作成するには、クラスター記憶域にディスクまたは記憶域スペースを追加する必要があります。
計画に関するその他の考慮事項は次のとおりです。
- 論理ユニット番号 (LUN) とボリュームの数とサイズ。 ガイダンスについては、ストレージのベンダーに問い合わせてください。
- VM の数とサイズ (VM をデプロイする場合)。 ボリュームあたりの VM の数に制限はありませんが、最適な数を決定する際には、集約された I/O 要件を考慮する必要があります。
- クラスター ネットワーク。 クラスター ネットワークでは、I/O リダイレクト中にコーディネーター ノードへのネットワーク トラフィックが増加する可能性に対応できる必要があります。
CSV を実装する
フェールオーバー クラスターでは、CSV 機能は既定で有効にされています。 ディスクを CSV に追加するには、まず、クラスターの使用可能記憶域グループにディスクを含める必要があります。 CSV にストレージを追加する前に、対応するディスクがクラスターで共有ストレージとして使用できる必要があります。 フェールオーバー クラスターを作成する場合は、既存のすべての共有ディスクがクラスターに自動的に追加されます。 その時点で、CSV にそれらを追加できます。 後で共有ストレージにディスクをさらに追加する場合は、まずクラスターにストレージを追加してから、そのストレージを CSV に追加する必要があります。 これらのタスクはすべて、フェールオーバー クラスター マネージャーまたは Windows PowerShell コマンドレットを使用して実行できます。