スケーラビリティとは
- 6 分
ビジネスの世界では、成長が有益である可能性があります。 ただし、成長が早すぎて、十分な準備ができていないと、成長によって問題が発生する可能性があります。 これらの問題の 1 つは、トラフィックの大幅な増加に対応するように設計されていないアプリケーションとサービスの信頼性に対する増加の影響です。
顧客とユーザーに対して、停止は停止です。 バグのあるコードが原因でサイトにアクセスできないのか、他の人があまりにも多くの人があなたの完全にコード化されたサイトを同時に使用しようとしているのか、彼らは知らないか気にしません。
スケーラビリティ は、需要の増加やニーズの変化に適応する機能です。 アプリケーションとサービスは、増加に対応するために、より大量のワークロードを処理できる必要があります。 スケーラブルなアプリケーションは、可用性やパフォーマンスに悪影響を及ぼすことなく、時間の経過と同時に要求の数を増やすことができます。
このユニットでは、スケーラビリティと信頼性の関係、スケーラビリティを実現するための容量計画の重要性について説明し、スケーリングに関連するいくつかの基本的な概念と用語を簡単に確認します。
スケーラビリティと信頼性の関係
アプリのスケーラビリティを高め、信頼性を高めることもできます。 たとえば、システムが自動スケーリングした後、1 つの仮想マシンでコンポーネントの障害が発生した場合、自動スケール サービスは、仮想マシン (VM) の最小数の要件を満たすために別のインスタンスをプロビジョニングします。 システムの信頼性が向上します。 別の例では、本質的にスケーラブルな Azure Storage のような高レベルのサービスを使用しています。 ストレージの問題がある場合、サービスは信頼性が高いように構築されているため、データがレプリケートされます。
例を次に示します。車椅子の人を収容するために最初に設計された建物の外でよく見られるアクセシビリティ ランプを考えてみましょう。 彼らはその目的に役立ちます。 しかし、彼らはまた、ベビーカーやキャリッジで赤ちゃんを持つ親、または階段のステップが深すぎるまたは高い小さな子供によっても使用されています。 この使用は 、2 番目の利点です。
信頼性は、多くの場合、スケーラビリティの二次的な利点です。 スケーラブルなシステムを設計する場合は、信頼性も高くなる可能性があります。
スケーラビリティと容量計画
容量計画 では、現在と将来の両方の需要を満たすために必要なリソースを決定する必要があります。 この計画を行うには、現在のリソース使用量を分析し、将来の成長を予測します。
将来的に容量のニーズを見積もるために、次のような要因を考慮する必要があります。
- 予想されるビジネスの成長
- 定期的な変動 (季節など)
- アプリケーションの制約
- ボトルネックと制限要因の特定
また、ワークロードと環境の変化に応じて、これらの目標を確実に満たすか、それを超える容量管理計画を作成できるように、サービス レベルの目標を設定する必要があります。
容量計画は反復的なプロセスです。 このモジュールでは、アプリケーション コンポーネントのリソース要件をマップする方法について説明します。
概念と用語
このモジュールで見つけた概念と戦略を完全に理解するには、いくつかの基本的な概念とスケーリングに関連する基本的な用語に関する前提条件の知識が必要です。
- スケールアップ: 増加したワークロードを処理するためにコンポーネントを大きくします。 垂直スケーリングとも呼ばれます。
- スケールアウト: 分散アーキテクチャに負荷を分散させるために、コンポーネントまたはリソースを追加します。 たとえば、一連のフロントエンドの背後に複数のバックエンドがある単純なアーキテクチャを使用します。 負荷が増加するにつれて、バックエンド (およびフロントエンド) サーバーを追加して処理します。 水平スケーリングとも呼ばれます。
- 手動スケーリング: リソースの量を増やすには、人間のアクションが必要です。
- 自動スケール: システムは、負荷に基づいてリソースの量を自動的に調整します。 明確にするために、量は増加または減少した負荷に基づいて上下に調整されます。
- DIY スケール: 自動スケールを構成する必要がある場合は、自分でスケーリングします。
- 固有のスケール: スケーラブルに構築され、このスケーリングをバックグラウンドで処理できるように構築されたサービス。ユーザー側に介入する必要はありません。 ユーザーの観点から見ると、手動でプロビジョニングしなくても、より多くのリソースを消費できるため、ほぼ無限にスケーラブルに見えます。
Tailwind Traders のアーキテクチャ
このモジュールでは、Tailwind Traders という架空のハードウェア会社のアーキテクチャ例を使用します。 eコマース プラットフォームは次のようになります。
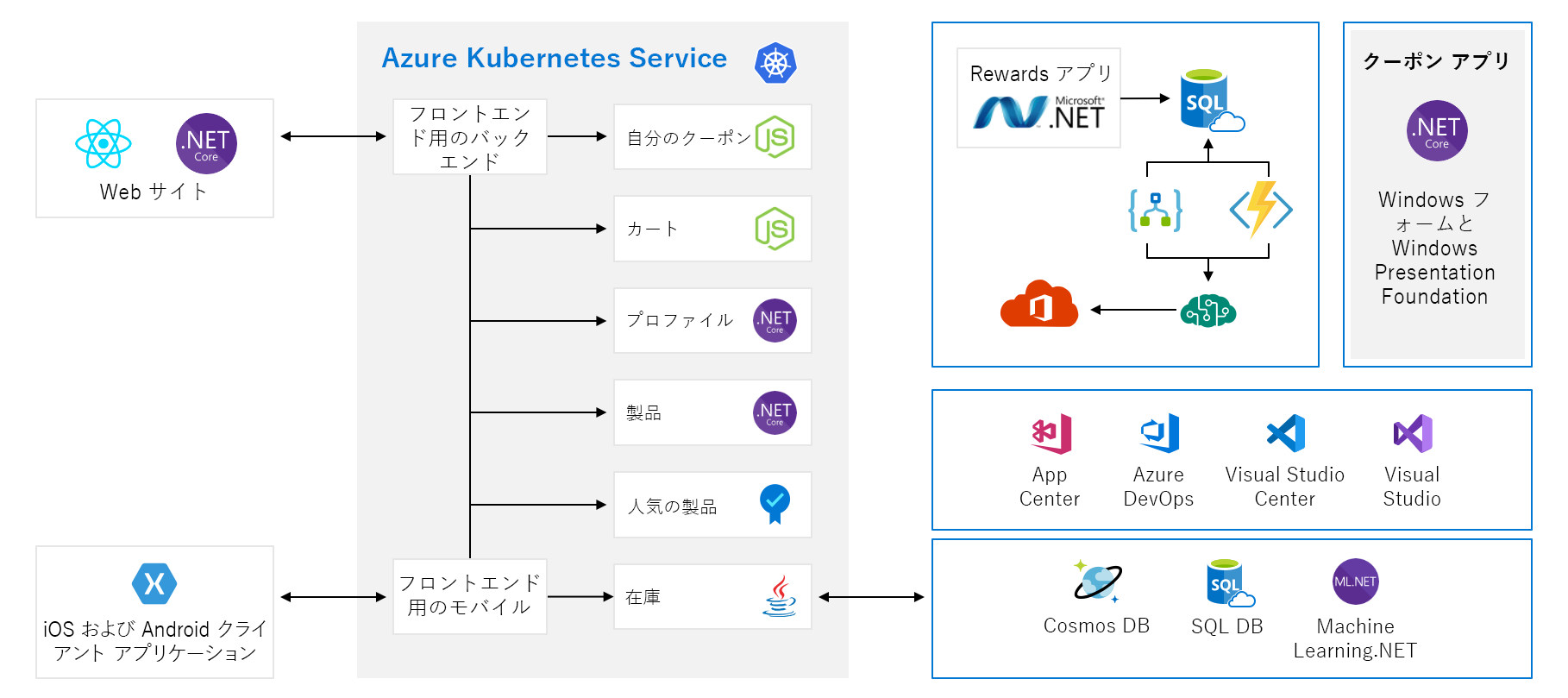
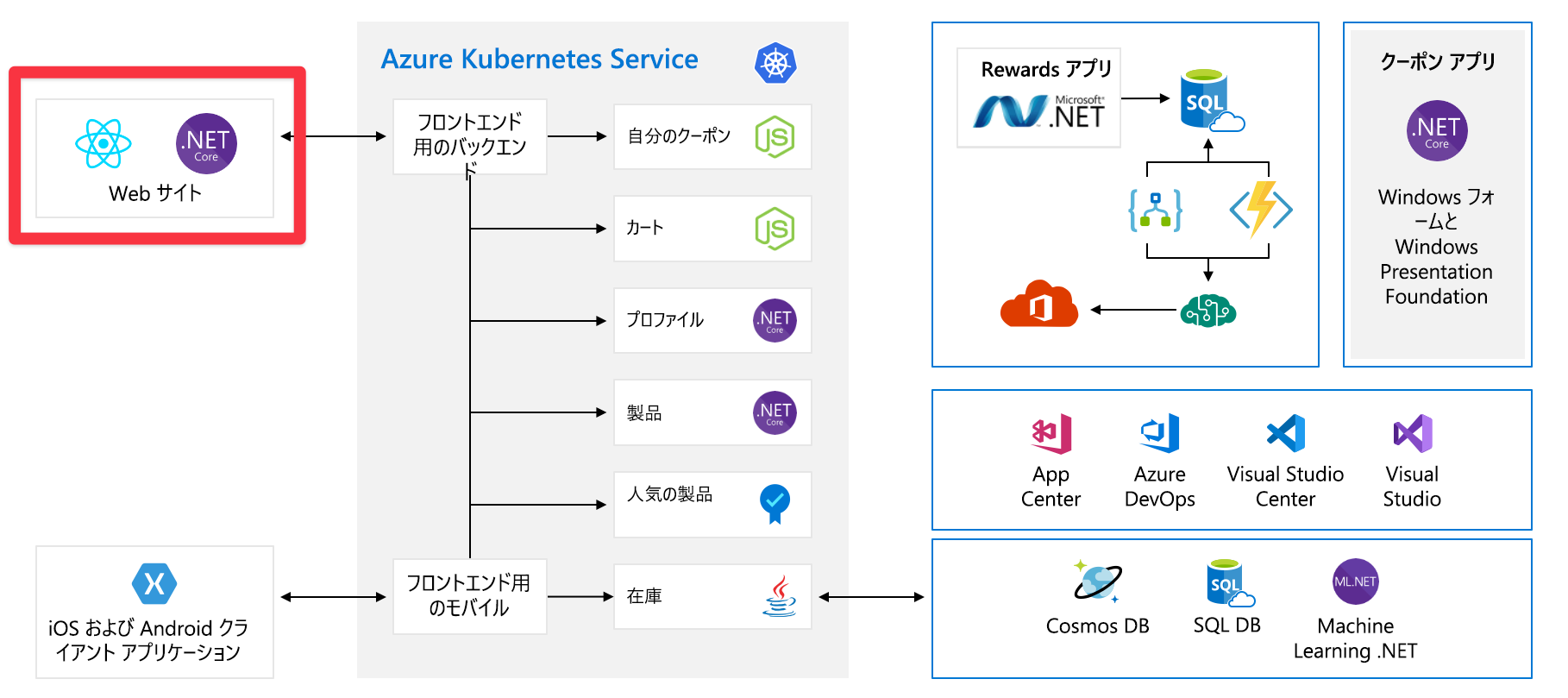
この図は、一見すると非常に複雑であるため、その手順を見てみましょう。 Web サイトにはフロントエンドがあります。 あなたが tailwindtraders.com に行くなら、それはあなたが話すものです。
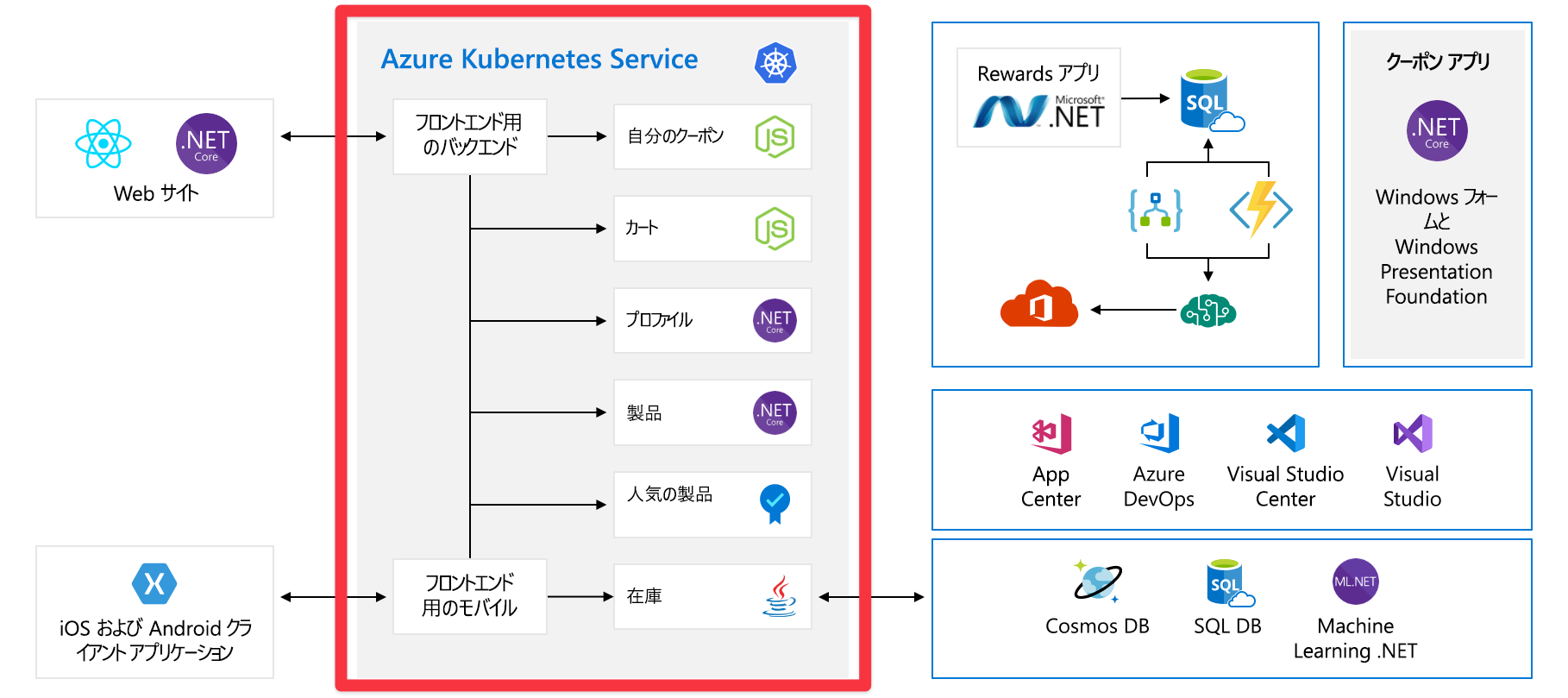
フロントエンドは、一連のバックエンド サービスと通信します。 これらのバックエンド サービスには、クーポン サービス、ショッピング カート サービス、在庫サービスなどの一般的な項目が含まれます。 これらはすべて Azure Kubernetes Service で実行されています。 このアプリケーションには、他の部分やテクノロジがあります。 注目する必要があるのは、Kubernetes で実行されているフロントエンド サービスとバックエンド サービスです。
単一障害点
アーキテクチャ全体を見たので、少し時間を取って、単一障害点と、スケーリングについて考えるときに注意を払う可能性がある場所を調べてみましょう。
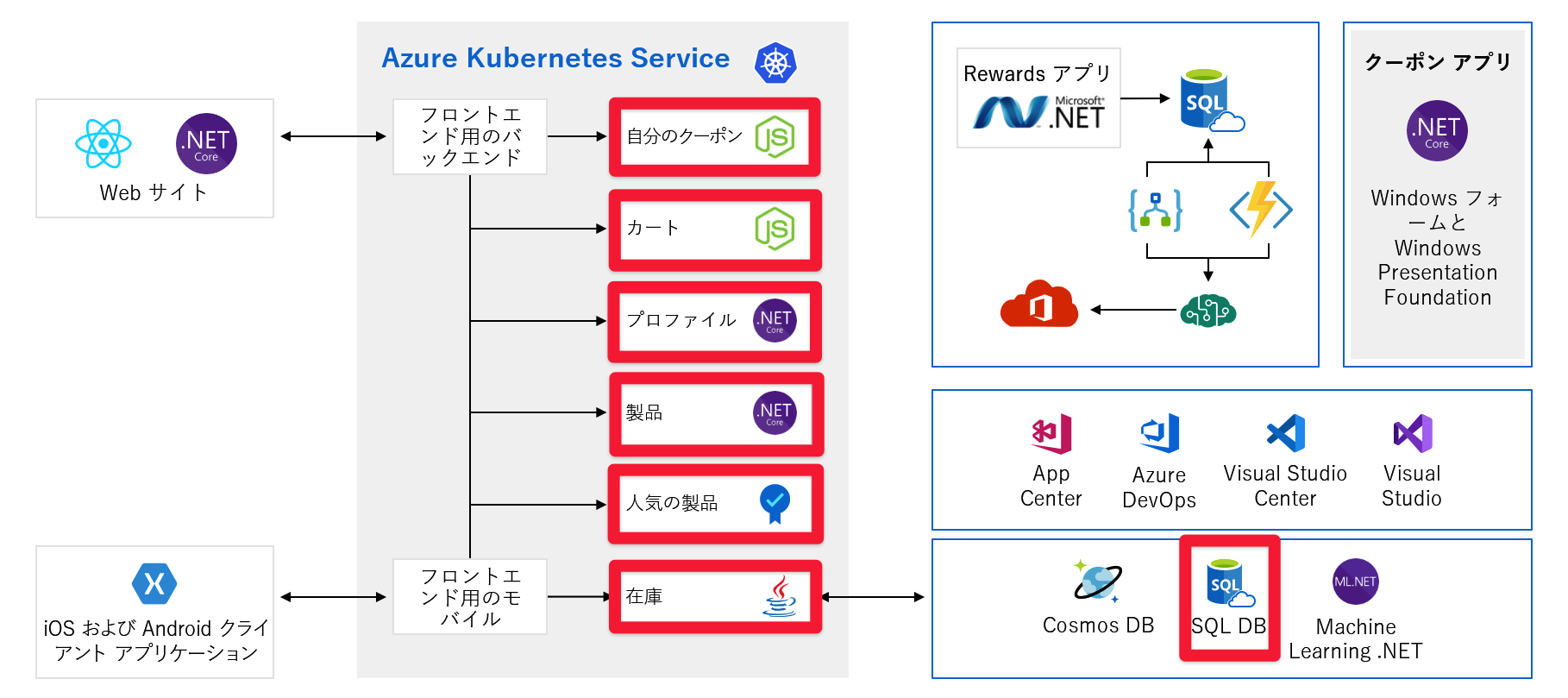
これらのサービスはすべて単一障害点であり、回復性やスケールのために構築されていません。 そのうちの 1 つが過負荷になった場合、クラッシュする可能性があり、現時点でそれを解決する簡単な方法はありません。
このモジュールの後半では、よりスケーラブルで信頼性の高いこれらのサービスを設計する他の方法について説明します。
事前プロビジョニングされた容量
面倒な問題が発生する可能性がある別の問題を見てみましょう。 容量を事前にプロビジョニングする必要があるサービス/コンポーネントを次に示します。
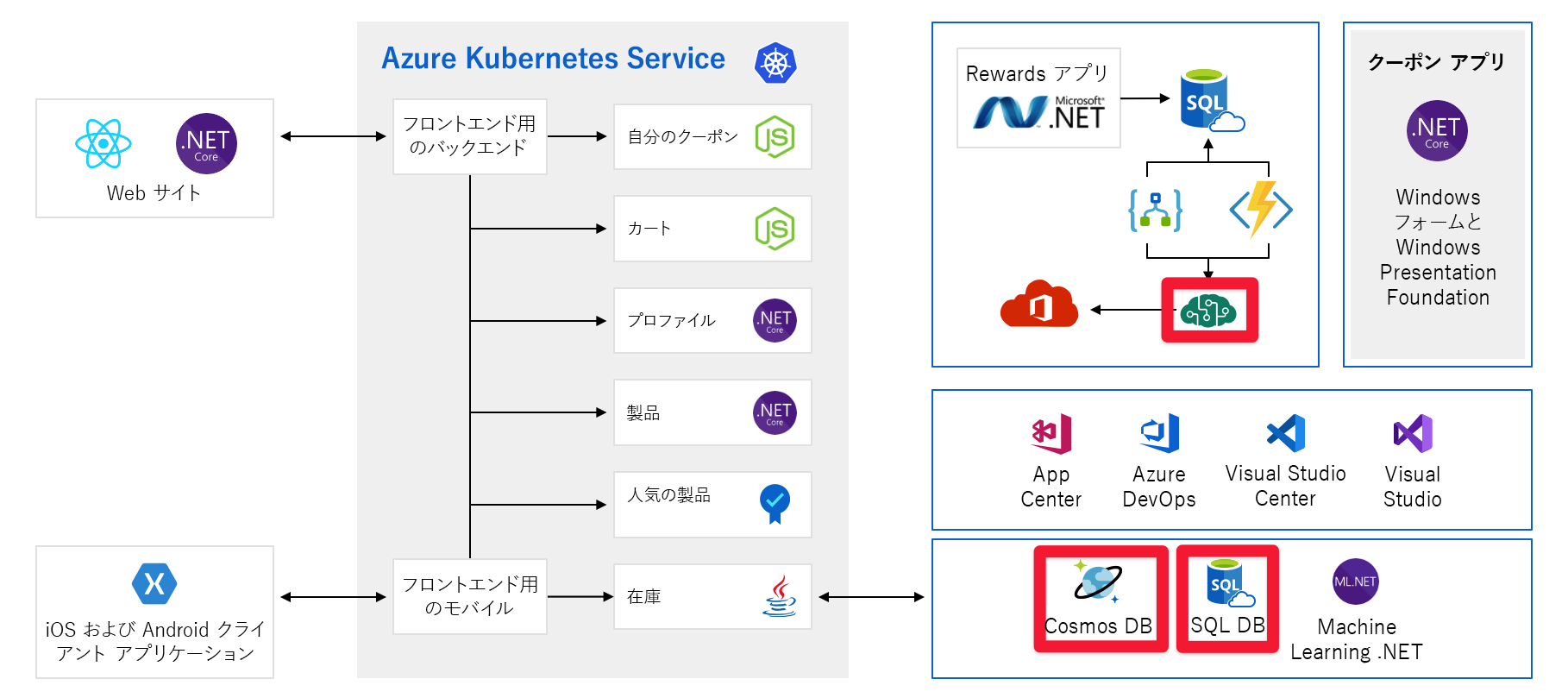
たとえば、Cosmos DB では、スループットを事前にプロビジョニングします。 これらの制限を超えた場合は、エラー メッセージをお客様に返し始めます。 Azure AI サービスでは、層を選択し、その層には 1 秒あたりの要求の最大数があります。 いずれかの制限に達すると、クライアントは調整されます。
新製品の発売など、トラフィックが大幅に急増すると、これらの制限に達しますか? 現時点では、わかりません。 この問題は、このモジュールの後半で確認するもう 1 つの問題です。
コスト
正しいことを行う場合でも、成長を計画する必要があります。 従量課金制サービスを次に示します。
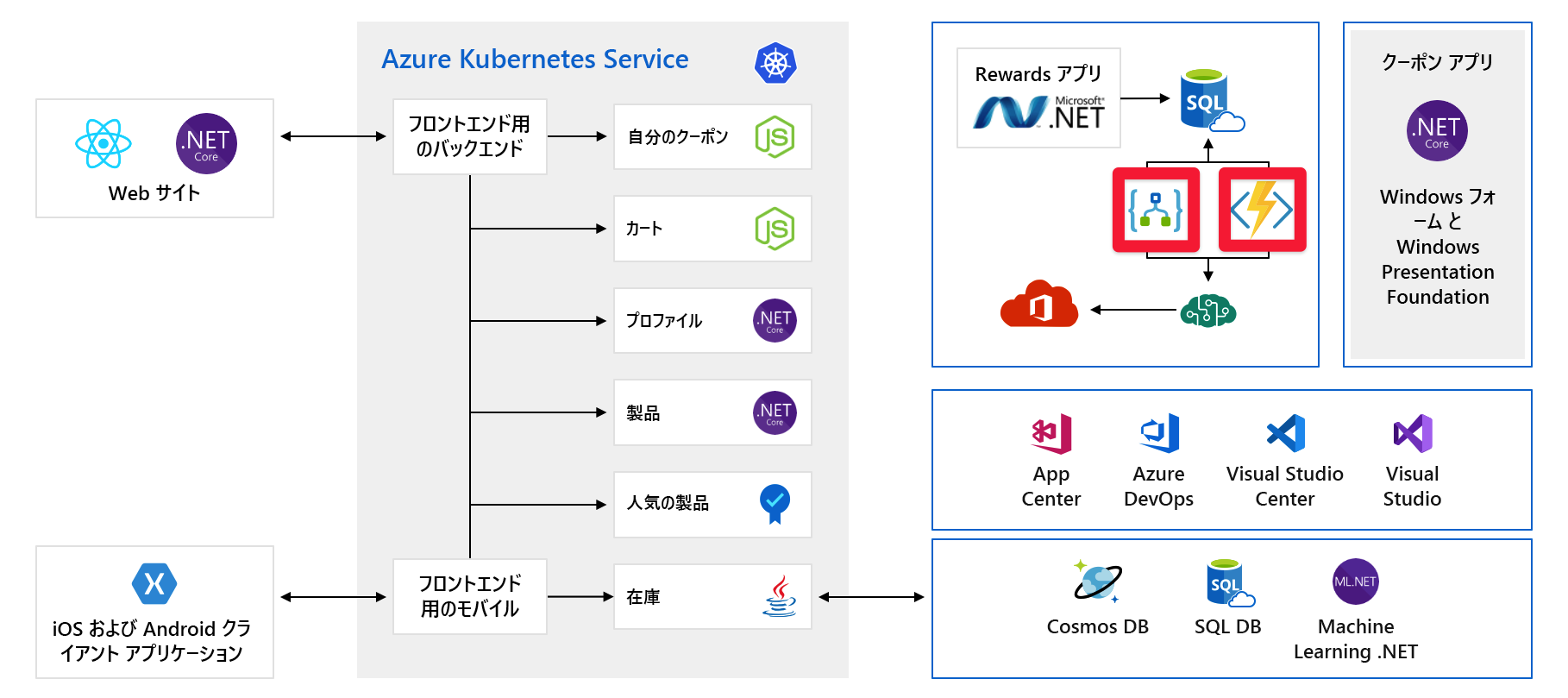
ここでは、サーバーレス テクノロジの例である Azure Logic Apps と Azure Functions を使用しています。 これらのサービスは自動的にスケーリングされ、要求ごとに支払われます。 請求書は、顧客ベースと同じように増加します。 少なくとも、製品の発売などの今後のイベントがクラウド支出に与える影響に注意する必要があります。 このモジュールの後半では、クラウド支出の理解と予測にも取り組みます。