再帰型ネットワークを使用してテキストを生成する
生成ネットワーク
リカレントニューラルネットワーク(RNN)とそのゲート化されたセルのバリアント(例えば、Long Short-Term Memoryセル(LSTM)やGated Recurrent Units(GRU)など)は、言語モデリングのメカニズムを提供します。 RNN は、単語の順序を学習し、シーケンス内の次の単語の予測を行うことができます。 これにより、通常のテキスト生成、機械翻訳、画像キャプションなどの 生成タスクに RNN を使用できます。
前のユニットで説明した RNN アーキテクチャでは、各 RNN ユニットが出力として次の非表示状態を生成しました。 ただし、各反復ユニットに別の出力を追加することもできます。これにより、元のシーケンスと同じ長さの シーケンス を出力できます。 さらに、各ステップで入力を受け入れない RNN ユニットを使用して、初期状態ベクトルを取得し、一連の出力を生成することもできます。
これにより、次の図に示すように、さまざまなニューラル アーキテクチャが可能になります。
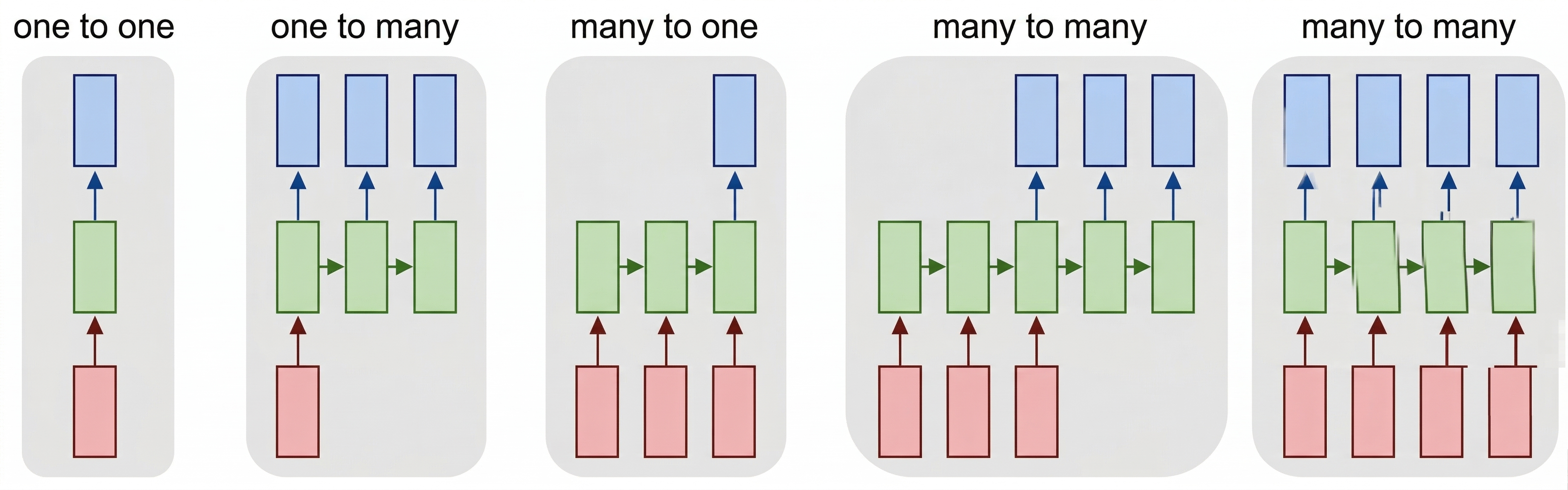 Andrej Karpathy によるリカレント ニューラル ネットワークの不合理な有効性に関するブログ記事の画像
Andrej Karpathy によるリカレント ニューラル ネットワークの不合理な有効性に関するブログ記事の画像
- 一対一 は、1 つの入力と 1 つの出力を持つ従来のニューラル ネットワークです。
- 一対多 は、1 つの入力値を受け取り、出力値のシーケンスを生成する生成アーキテクチャです。 たとえば、画像のテキスト説明を生成する 画像キャプション ネットワークを トレーニングする場合は、画像を入力として使用し、CNN を介して非表示の状態を取得し、繰り返しチェーンでキャプションを単語単位で生成することができます。
- 多対一 は、テキスト分類など、前のユニットで説明した RNN アーキテクチャに対応します。
- 多対多または シーケンス間 は 、機械翻訳などのタスクに対応します。この場合、RNN は最初に入力シーケンスからすべての情報を隠し状態に収集してから、この状態を出力シーケンスに展開します。
このユニットでは、テキストの生成に役立つ単純な生成モデルに焦点を当てます。 わかりやすくするために、 文字レベルのネットワークを構築し、文字でテキスト文字を生成してみましょう。 トレーニング中に、テキスト コーパスを取得し、文字シーケンスに分割する必要があります。
import tensorflow as tf
import keras
import tensorflow_datasets as tfds
import numpy as np
# In this tutorial, we will be training a lot of models. In order to use GPU memory cautiously,
# we will set tensorflow option to grow GPU memory allocation when required.
physical_devices = tf.config.list_physical_devices('GPU')
if len(physical_devices)>0:
tf.config.set_memory_growth(physical_devices[0], True)
dataset = tfds.load('ag_news_subset')
ds_train = dataset['train']
ds_test = dataset['test']
文字ボキャブラリの構築
文字レベルの生成ネットワークを構築するには、テキストを単語ではなく個々の文字に分割する必要があります。 使用している TextVectorization レイヤーは直接行えないので、単純な文字レベルのトークナイザーを手動で構築します。 別の方法については、 この公式の Keras の例 を参照することもできます。
トレーニング タイトルをスキャンして、文字ボキャブラリを作成します。
def extract_text(x):
return x['title']+' '+x['description']
def tupelize(x):
return (extract_text(x),x['label'])
# Build character vocabulary from training titles
chars = set()
for x in ds_train:
chars.update(x['title'].numpy().decode('utf-8'))
# Create character-to-index and index-to-character mappings
# Reserve index 0 for padding
char_to_idx = {ch: i+1 for i, ch in enumerate(sorted(chars))}
idx_to_char = {i: ch for ch, i in char_to_idx.items()}
また、1 つの特殊なトークンを使用して 、シーケンスの終了を示します。これは、 <eos>と呼ばれます。 ボキャブラリに手動で追加してみましょう。
eos_token = len(char_to_idx)+1
char_to_idx['<eos>'] = eos_token
idx_to_char[eos_token] = '<eos>'
vocab_size = eos_token + 1
テキストを数値のシーケンスにエンコードするために、ヘルパー関数を記述できるようになりました。
def texts_to_sequences(texts):
return [[char_to_idx.get(ch, 0) for ch in text] for text in texts]
texts_to_sequences(['Hello, world!'])
タイトルを生成するためのジェネレーティブ RNN のトレーニング
RNN をトレーニングしてタイトルを生成する方法を次に示します。各手順では、1 つのタイトルを入力として受け取り、そのタイトルの入力文字ごとに、次の文字を出力として生成するようにネットワークをトレーニングします。
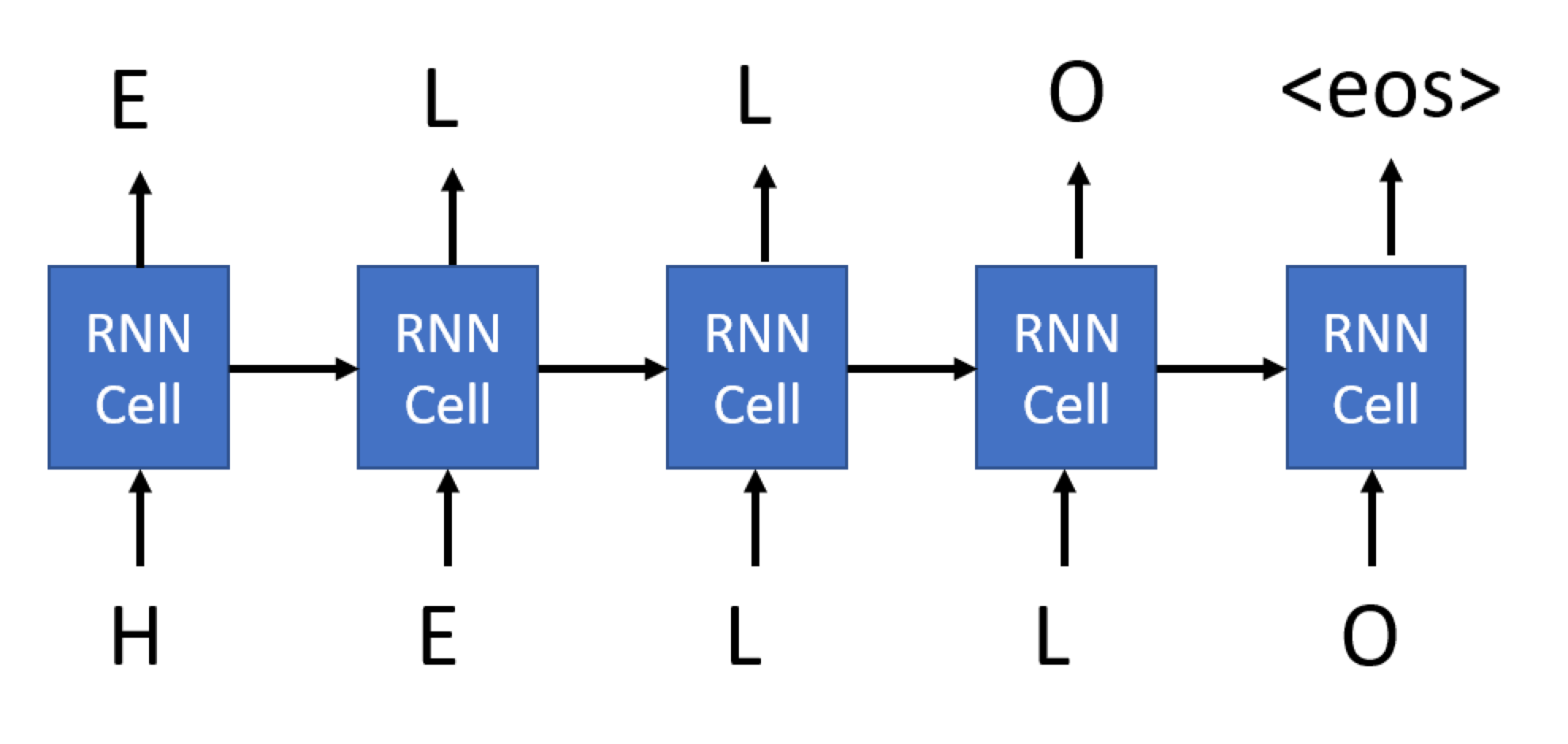
シーケンスの最後の文字については、 <eos> トークンを生成するようにネットワークに依頼します。
ここで使用している生成 RNN と前に見た RNN の主な違いは、生成 RNN の各セルが最終的なセルだけでなく出力を生成するということです。 これは、RNN セルの return_sequences パラメーターを指定することで実現できます。
したがって、トレーニング中、ネットワークへの入力は、ある程度の長さのエンコードされた文字のシーケンスになり、対応する出力は同じ長さのシーケンスになりますが、1 つの要素によってシフトされ、 <eos>によって終了されます。 ミニバッチはこのようなシーケンスで構成され、 パディング を使用してすべてのシーケンスを整列する必要があります。
データセットを変換する関数を作成しましょう。 ミニバッチ レベルでシーケンスを埋め込むため、まず .batch()を呼び出してミニバッチを作成し、次に map を使用して変換を行います。 変換を行う関数のコードを次に示します。これは、ミニバッチ全体をパラメーターとして受け取ります。
def title_batch(x):
x = [t.numpy().decode('utf-8') for t in x]
z = texts_to_sequences(x)
z = keras.utils.pad_sequences(z)
return tf.one_hot(z,vocab_size), tf.one_hot(tf.concat([z[:,1:],tf.constant(eos_token,shape=(len(z),1))],axis=1),vocab_size)
ここでは、いくつかの重要な操作を行います。
- 最初に、文字列テンソルから実際のテキストを抽出します。
-
texts_to_sequencesは、文字列のリストを整数テンソルのリストに変換します。 -
pad_sequencesは、これらのテンソルを最大の長さにパディングします。 - 最後に、すべての文字を One-Hot エンコーディングし、切り替えと
<eos>の追加も行います。 One-Hot エンコーディング文字が必要な理由はすぐにわかります。
ただし、この関数は Python です。 この関数を TensorFlow 計算グラフに自動的に変換することはできません。
Dataset.map関数に直接渡そうとすると、この関数を使用する方法でエラーが発生します。 この問題を回避するには、 py_function ラッパーを使用して、この Python 呼び出しを囲む必要があります。
def title_batch_fn(x):
x = x['title']
a,b = tf.py_function(title_batch,inp=[x],Tout=(tf.float32,tf.float32))
a.set_shape([None, None, vocab_size])
b.set_shape([None, None, vocab_size])
return a,b
注
Keras 3 では、 tf.py_function の出力には既定で不明な図形があり、入力テンソルのランクを知る必要がある Masking や LSTM などのレイヤーでエラーが発生します。
set_shapeを使用して、TensorFlow に予想されるテンソルディメンションを伝えます。
注
py_function ラッパーを呼び出す代わりに、標準の Python 関数を使用してデータセットを変換してから、fitに渡すことができるかどうか疑問に思うかもしれません。 これは間違いなく可能ですが、 Dataset.map 使用する場合、データ変換パイプラインは、GPU 計算を利用し、CPU/GPU 間でデータを渡す必要性を最小限に抑える TensorFlow の計算グラフを使用して実行されます。
ジェネレーター ネットワークを構築し、トレーニングを開始できるようになりました。 このネットワークは、前のユニットで説明した任意のリカレント セル (単純、LSTM、または GRU) に基づくことができます。 この例では、LSTM を使用します。
ネットワークは文字を入力として受け取るため、ボキャブラリのサイズは小さくなります。 そのため、埋め込みレイヤーは必要ありません。 1 つのホット エンコードされた入力を LSTM セルに直接フィードできます。 出力レイヤーは、LSTM 出力を 1 つのホット エンコードされたトークン番号に変換する Dense 分類子です。
さらに、可変長シーケンスを扱っているので、 Masking レイヤーを使用して、文字列の埋め込まれた部分を無視するマスクを作成できます。 これは厳密には必要ありません。これは、 <eos> トークンを超えるすべてのものには関心がないためです。ただし、このレイヤーの種類のエクスペリエンスを得るために使用します。 入力図形は (None, vocab_size) で、 None は可変長のシーケンスを示し、出力図形も (None, vocab_size) です。これに関しては、summary の印刷結果から確認できます。
model = keras.Sequential([
keras.Input(shape=(None,vocab_size)),
keras.layers.Masking(),
keras.layers.LSTM(128,return_sequences=True),
keras.layers.Dense(vocab_size,activation='softmax')
])
model.summary()
model.compile(loss='categorical_crossentropy')
model.fit(ds_train.batch(8).map(title_batch_fn))
このコードを実行すると、次の出力が生成されます。
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ masking (Masking) │ (None, None, 84) │ 0 │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ lstm (LSTM) │ (None, None, 128) │ 109,056 │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ dense (Dense) │ (None, None, 84) │ 10,836 │
└──────────────────────────────┴───────────────────────────┴───────────────┘
Total params: 119,892 (468.33 KB)
Trainable params: 119,892 (468.33 KB)
Non-trainable params: 0 (0.00 B)
15000/15000 ━━━━━━━━━━━━━━━━━━━━ 273s 18ms/step - loss: 1.5460
出力の生成
モデルをトレーニングしたので、それを使用して出力を生成します。 まず第一に、トークン番号のシーケンスで表されるテキストをデコードする方法が必要です。 前に作成した idx_to_char マッピングを使用します。
def decode(x):
return ''.join([idx_to_char.get(t,'') for t in x])
生成を行うには、最初にパラメーターとして渡された文字列をシーケンスにエンコードし、各ステップでネットワークを呼び出して次の文字を推論します。
ネットワークの出力は、各トークンの確率を表す vocab_size 要素のベクトルであり、 argmaxを使用して最も可能性の高いトークン番号を見つけることができます。 次に、生成されたトークンの一覧にこの文字を追加し、生成を続行します。 1 文字を生成するこのプロセスは、必要な文字数を生成するために size 回繰り返され、 eos_token が発生した場合は早期に終了します。
def generate(model,size=100,start='Today '):
chars = texts_to_sequences([start])[0]
for i in range(size):
out = model(tf.expand_dims(tf.one_hot(chars,vocab_size),0))[0][-1]
nc = tf.argmax(out)
if nc==eos_token:
break
chars.append(nc.numpy())
return decode(chars)
generate(model)
トレーニング中のサンプリング出力
精度などの有用なメトリックがないため、モデルが向上していることを確認できる唯一の方法は、トレーニング中に生成された文字列をサンプリングすることです。 そのために コールバックを 使用します。これは、 fit 関数に渡すことができる関数であり、トレーニング中に定期的に呼び出されます。 これを行うには、次のコードを使用します。
sampling_callback = keras.callbacks.LambdaCallback(
on_epoch_end = lambda batch, logs: print(generate(model))
)
model.fit(ds_train.batch(8).map(title_batch_fn),callbacks=[sampling_callback],epochs=3)
この例は、いくつかの方法で改善できます。
-
その他のテキスト。 タスクにはタイトルのみを使用しましたが、フルテキストを試すことができます。 RNN は長いシーケンスを処理するのにそれほど適していないことに注意してください。そのため、短い文に分割するか、固定長
num_charsのシーケンス (たとえば 256) でトレーニングするのが理にかなっています。 公式の Keras チュートリアル をインスピレーションとして使用して、上記の例をこのアーキテクチャに変更してみてください。 - 多層 LSTM。 LSTM細胞の2層または3層を試してみるのは理にかなっています。 前のユニットで説明したように、LSTM の各レイヤーはテキストから特定のパターンを抽出します。文字レベルジェネレーターの場合、音節を抽出する役割を担う LSTM レベルが低く、単語と単語の組み合わせを抽出するレベルが高いことを期待できます。 これは、レイヤーをモデルに順番に追加することによって実装できます。
- また、GRU ユニットを試して、パフォーマンスが向上しているのと、非表示レイヤーのサイズが異なるかどうかを確認することもできます。 非表示レイヤーが大きすぎると、オーバーフィットが発生する可能性があり (ネットワークが正確なテキストを学習するため)、非表示レイヤーが小さすぎると、適切な結果が得られない可能性があります。
柔軟なテキスト生成と温度制御
generate関数のコードでは、生成されたテキストの次の文字として最も高い確率の文字を取りました。 その結果、次の例のように、同じ文字シーケンスを繰り返し繰り返すテキストが生成されました。
today of the second the company and a second the company ...
ただし、次の文字の確率分布を見ると、似た確率が高い確率がいくつか存在する可能性があります。 たとえば、シーケンス 'play' で次の文字を探すときは、同様にスペースまたは e ( プレイヤーという単語のように) である可能性が高くなります。
したがって、絶対確率が最も高い文字を選択することが常に最善の選択であるとは限りません。 2 番目または 3 番目に高い文字を選択しても、意味のあるテキストが得られ、文字シーケンスの循環が回避される可能性があります。 したがって、ネットワーク出力によって与えられる確率分布から文字を サンプリング することをお勧めします。
このサンプリングは、np.multinomialを実装する関数を使用して実行できます。
注
この実装では、logits (softmax の前) ではなく、出力確率 (softmax の後) に温度を適用します。 これは数学的には、各確率を $1/\text{temperature}$ 乗してから再正規化することと同値です。 文献の標準的な規則は、極端な温度値に対してより数値的に安定することができるソフトマックスの前にロジットに温度を適用します。 どちらの方法でも、中程度の温度値に対して同等の結果が得られます。
def generate_soft(model,size=100,start='Today ',temperature=1.0):
chars = texts_to_sequences([start])[0]
for i in range(size):
out = model(tf.expand_dims(tf.one_hot(chars,vocab_size),0))[0][-1]
probs = tf.exp(tf.math.log(out)/temperature).numpy().astype(np.float64)
probs = probs/np.sum(probs)
nc = np.argmax(np.random.multinomial(1,probs,1))
if nc==eos_token:
break
chars.append(nc)
return decode(chars)
words = ['Today ','On Sunday ','Moscow, ','President ','Little red riding hood ']
for i in [0.3,0.8,1.0,1.3,1.8]:
print(f"\n--- Temperature = {i}")
for j in range(5):
print(generate_soft(model,size=300,start=words[j],temperature=i))
このコードを実行すると、次の出力が生成されます。
--- Temperature = 0.3
Today #39;s strong to be in Iraq line at US first profit
On Sunday DS #39; Market Shot to Expect (AP)
Moscow, SP completes street to share maker straight talks
President Sutel to Return in The Takeover Three Street (AP)
Little red riding hood for talks to hit on to start in Iraq
--- Temperature = 0.8
Today olies safel fate withdraws to leave #39;Profit #39; smathe off the meet
On Sunday BC - Miscripys Southern dead in Iraq
Moscow, SP to up air burine with Mart oppositive, MySWilliers price stand
President Israli Wasted Predemation Retailers for Mondain Convent
Little red riding hood field skyallingnaul by buys
--- Temperature = 1.0
Today casop Symantec family start worries With Montreal evi
On Sunday DA in Loest Piofut For Afghan Minister (AP)
Moscow, S TSVRCIA Forting Have Black Chapfers #39; In Ractor
President iveshight arophis, remain from collemen shipal back (AFP)
Little red riding hood gin calp sold, not to target
--- Temperature = 1.3
Today S economy Jobs Giving 0 6 Wein trager
On Sunday cold Must 3T0-core U.S. stand of puperahinmer;'
Moscow, WA way to hope Mitran's fidsnen-from strike bad
President C., Gazu Sched and Supilicibant-High Inote Found, to View: Terrent <b>...</b>
Little red riding hood freals lower; #39;Vioxhercen, a batte title fors 3
--- Temperature = 1.8
Today meris Blaars 35 butifyra, MusaurakifuIs Hubids
On Sunday M?
Moscow, Is Wircosts-yniuvs' ahaf bivck', F.Hffile
President Wrlfestlps Ado, 'W. Tough Wins USUsi AK Deby, \$6 - MogsuBNARTVISGAK, Passu: (Reuters)
Little red riding hood 3 U.L1jn doem'sb-love usquatefwh rave miss outmufl
温度パラメーターを使用すると、低い確率文字よりも高い確率文字を選択する必要がある強さを示すことができます。 温度が 0 に近い場合は、最も高い確率文字を選択し、温度が無限大に近づくと、すべての確率が等しくなり、次の文字をランダムに選択します。 上記の例では、温度を上げすぎると出力が無意味になり、0 に近いほど循環が開始されることを確認できます。