HDInsight 対話型クエリ
対話型クエリは通常、表形式のデータがあり、SQL 構文を使用してすばやく質問し、対話型応答を取得する必要がある、コールド パス シナリオで実装されます。 次の図では、すべての HDInsight コールド パスおよびホット パス ソリューションのソリューションアーキテクチャを示し、サービス層の Hive LLAP を介して対話型クエリがどのように処理されるかを説明しています。 データは Hive を介して取り込むことができ、対話型クエリは Hive LLAP を介して処理され、出力 put は Power BI などのダウンストリーム アプリケーションに提供できます。
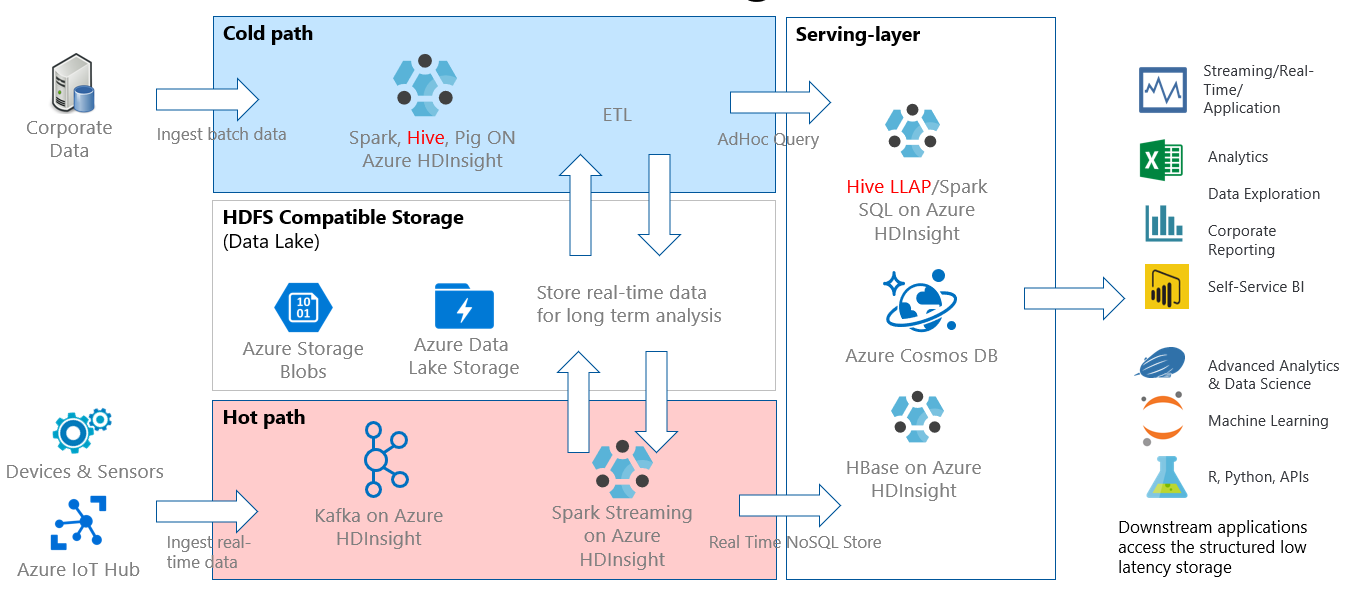
対話型クエリのアーキテクチャ
次は、対話型クエリのアーキテクチャを詳しく見ていきましょう。
対話型クエリ ユーザーは、Data Analytics Studio、Zeppelin Notebook、および Visual Studio Code など、ビジネス データに対してクエリを実行するためのさまざまな ODBC または JDBC クライアントから選択することができます。 クライアントで HiveQL クエリが送信された後、クエリは HiveServer (クエリの計画、最適化、およびセキュリティ トリミングを担当) に到着します。 Hive は、クラスター内の分散ノード全体で分析タスクを分割することによって機能します。 クエリはサブタスクに分割され、各サブタスクを処理するノードに送信されます。これらのサブタスクはさらに分割され、各タスクでは基になるビジネス データ ストレージ層からデータを読み取ります。 起動時間を回避する "常時接続" LLAP デーモンと、ストレージから取得されたデータを格納してすべてのノード間でデータを共有する共有メモリ内キャッシュが使用されるため、アーキテクチャが最適化されます。
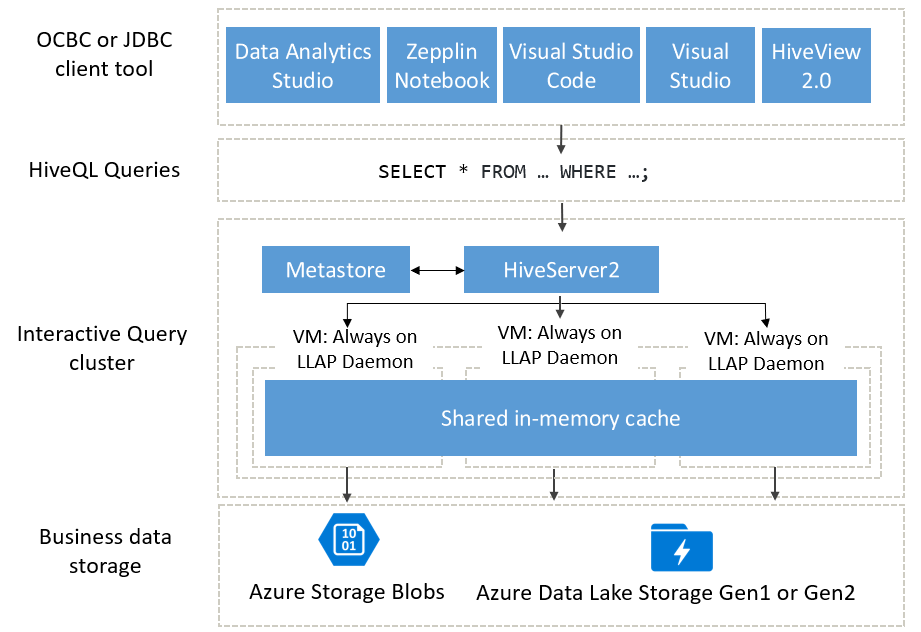
対話型クエリ クラスターで利用されるソリッドステート ドライブ (SSD) では、RAM と SSD の両方を、キャッシュで使用される巨大なメモリプールに結合します。 このリソースの組み合わせにより、標準的なサーバー プロファイルでは、4 倍以上のデータをキャッシュできるため、より大きなデータセットを処理し、より多くのユーザーがサポートされます。 対話型クエリ キャッシュでは、リモート ストア (Azure Storage) の基になるデータの変更を認識します。そのため、基になるデータが変更され、ユーザーがクエリを発行した場合、更新されたデータはメモリに読み込まれ、追加のユーザー手順は必要ありません。