演習 - HDInsight でデータをアップロードしてクエリを実行する
ストレージ アカウントと対話型クエリ クラスターをプロビジョニングしたら、次は不動産データをアップロードし、いくつかのクエリを実行します。 アップロードするデータは、ニューヨーク市の不動産データです。 住所、販売価格、平方面積、ジオコーディングされた位置情報など、28,000 を超えるプロパティ レコードが含まれており、マッピングが容易になります。 あなたの不動産投資会社は、この情報を使用して、以前に販売された物件の販売価格に基づいて、市場に出る新しい物件の適切な平方フィート当たりの価格を決定します。
データをアップロードしてクエリを実行するには、Data Analytics Studio を使用します。これは、対話型クエリ クラスターの作成時に使用したスクリプト アクションにインストールされた Web ベースのアプリケーションです。 Data Analytics Studio を使用すると、Azure Storage にデータをアップロードし、設定したデータ型と列名を使用してデータを Hive テーブルに変換し、HiveQL を使用してクラスター上のデータにクエリを実行できます。 Data Analytic Studio に加えて、任意の ODBC/JDBC 準拠ツールを使用して、Spark や Hive Tools for Visual Studio Code などの Hive を使用してデータを操作できます。
次に、Zeppelin Notebook を使用して、データの傾向をすばやく視覚化します。 Zeppelin Notebooks を使用すると、クエリを送信し、さまざまな定義済みのグラフで結果を表示できます。 対話型クエリ クラスターにインストールされている Zeppelin Notebook には、Hive ドライバーを備えた JDBC インタープリターがあります。
不動産データをダウンロードする
- https://github.com/Azure/hdinsight-mslearn/tree/master/Sample%20dataに移動し、データ セットをダウンロードして、propertysales.csv ファイルをコンピューターに保存します。
Data Analytics Studio を使用してデータをアップロードする
- 次の URL を使用して、インターネット ブラウザーで Data Analytics Studio を開き、サーバー名を使用したクラスター名に置き換えます: https:// servername.azurehdinsight.net/das/
ログインするには、 ユーザー名は管理者であり、 パスワードは作成したパスワードです。
エラーが発生した場合は、Azure portal でクラスターの [概要] タブ に移動し、状態が [実行中] に設定され、クラスターの種類として HDI バージョンが 対話型クエリ 3.1 (HDI 4.0) に設定されていることを確認します。
- Data Studio Analytics がインターネット ブラウザーで起動します。
- 左側のメニューの [データベース] をクリックし、緑色の直立した省略記号ボタンをクリックし、[ データベースの作成] をクリックします。
![Data Analytics Studio アプリケーションの [データベースの作成] ボタンのスクリーンショット](../../wwl-mba/perform-zero-etl-analytics-hdinsight-interactive-query/media/5-create-database.png)
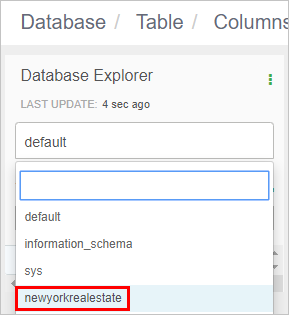
データベースに "newyorkrealestate" という名前を付け、[ 作成] をクリックします。
データベース エクスプローラーで、 データベース名ボックスをクリックし、 newyorkrealestate を選択します。
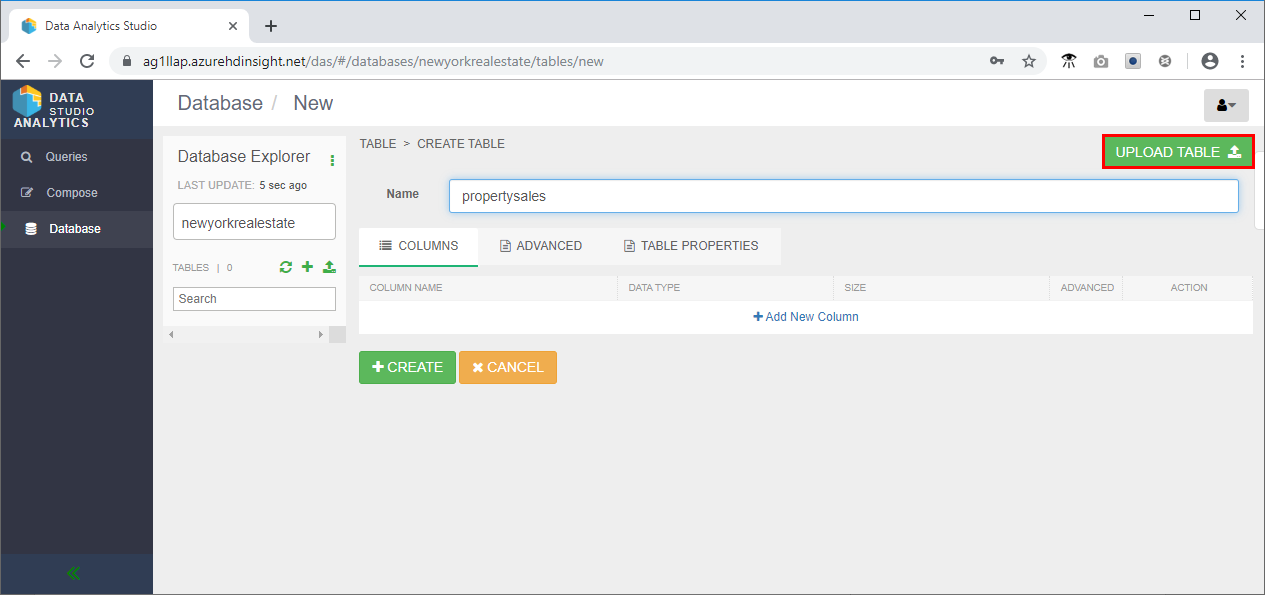
- データベース エクスプローラーで、[ + ] をクリックし、[テーブルの 作成] をクリックします。
- 新しいテーブルに "propertysales" という名前を付け、[ テーブルのアップロード] をクリックします。 テーブル名には小文字と数字のみを含める必要があり、特殊文字は使用しません。
- ページの [ファイル形式の選択] 領域で、次の操作を行います。
- ファイル形式が csv であることを確認する
- 最初の行はヘッダーですか? チェック ボックスをオンにします。
- ページの [ファイル ソースの選択] 領域で、次の操作を行います。
- [ ローカルからアップロード] を選択します。
- [ファイルをドラッグしてアップロード] をクリックするか、[参照] をクリックして、propertysales.csv ファイルに移動します。
- [列] セクションで、緯度と経度のデータ型を 文字列に、販売日を日付に変更 します。
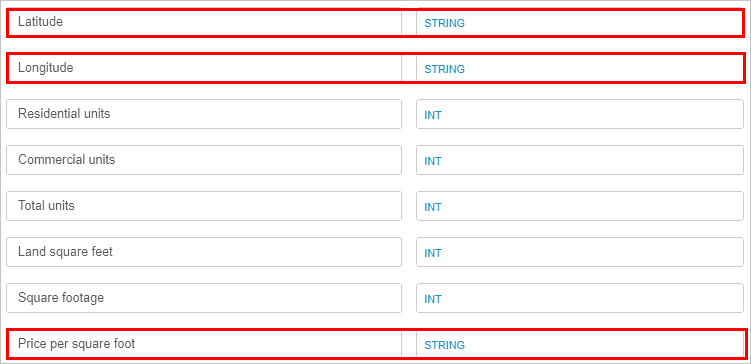
- 上にスクロールし、[ テーブル プレビュー ] セクションを確認して、列見出しが正しく表示されていることを確認します。
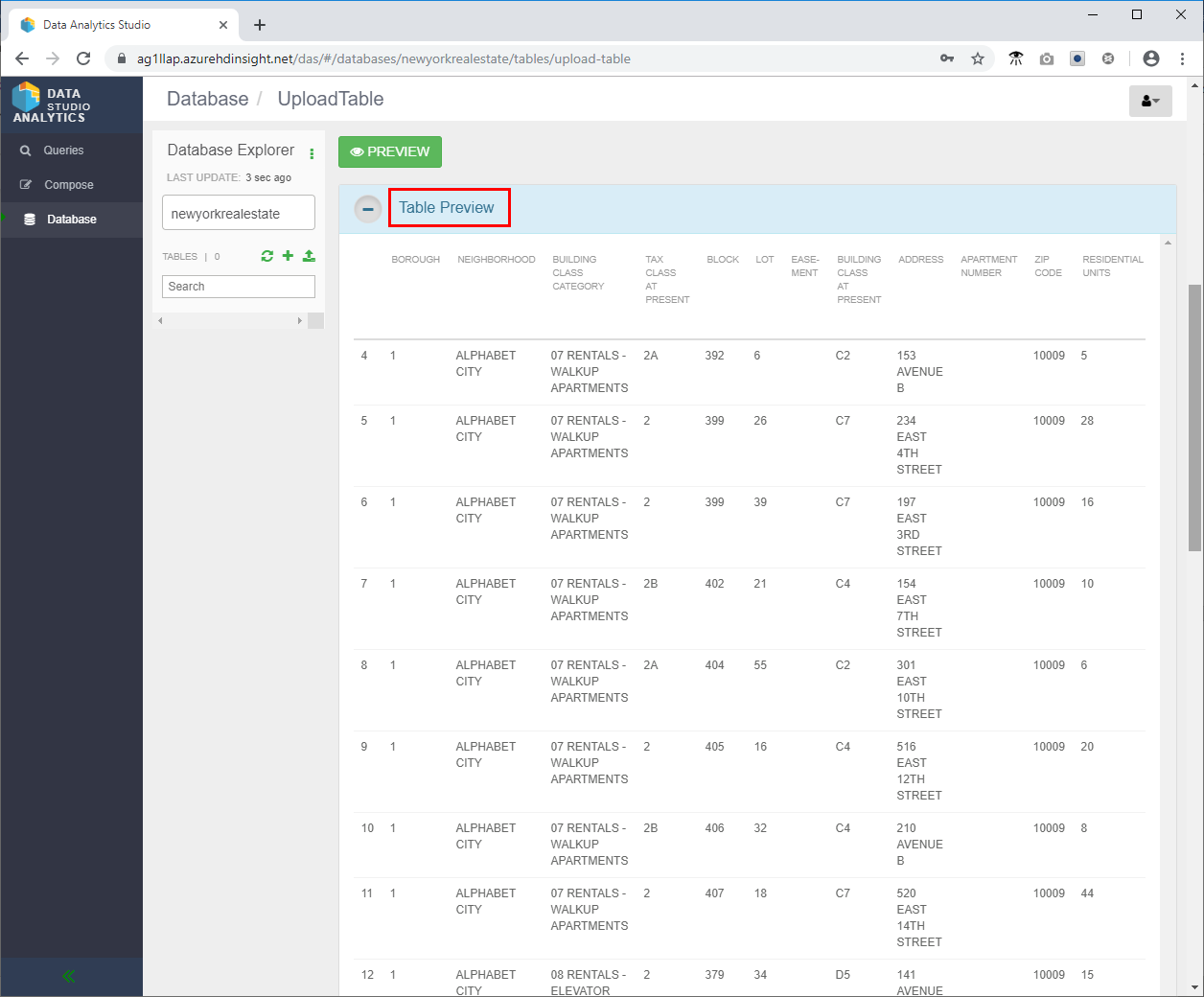
- 下にスクロールし、[ 作成 ] をクリックして newyorkrealestate データベースに Hive テーブルを作成します。
![Data Analytics Studio アプリケーションの [Hive テーブルの作成] ボタン](../../wwl-mba/perform-zero-etl-analytics-hdinsight-interactive-query/media/5-database-analytics-studio-create-button.png)
- 左側のメニューで、[ 作成] をクリックします。
![Data Analytics Studio アプリケーションの [作成] ボタン](../../wwl-mba/perform-zero-etl-analytics-hdinsight-interactive-query/media/5-database-analytics-studio-compose-button.png)
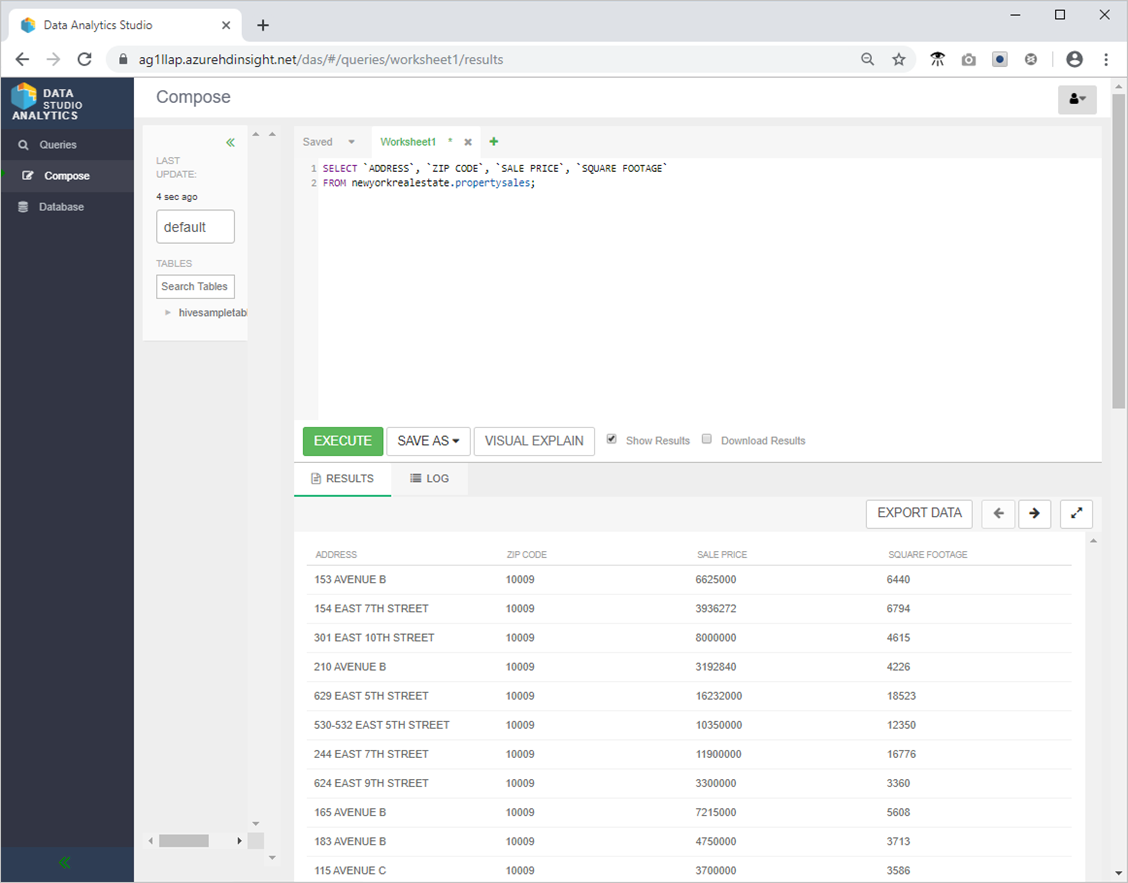
- 次の Hive クエリを試して、すべてが期待どおりに動作していることを確認します。
SELECT `ADDRESS`, `ZIP CODE`, `SALE PRICE`, `SQUARE FOOTAGE`
FROM newyorkrealestate.propertysales;
- 出力は次のようになるはずです。
- 左側のメニューの [クエリ] をクリックし、実行した SELECT
ADDRESS、ZIP CODE、SALE PRICE、SQUARE FOOTAGEFROM newyorkrealestate.propertysales クエリを選択して、クエリのパフォーマンスを確認します。
使用可能なパフォーマンスに関する推奨事項がある場合は、ツールにこれらの推奨事項が表示されます。 このページには、実行された実際の SQL クエリも表示され、クエリの視覚的な説明が提供され、クエリの実行時に Hive によって推論される構成の詳細が表示されます。また、クエリの各部分の実行に費やされた時間を示すタイムラインも表示されます。
Zeppelin ノートブックを使用して Hive テーブルを探索する
- Azure portal の [概要] ページの [クラスター] ダッシュボード ボックスで、[ Zeppelin Notebook] をクリックします。
- [ 新しいメモ] をクリックし、メモに「不動産データ」という名前を付けて、[ 作成] をクリックします。
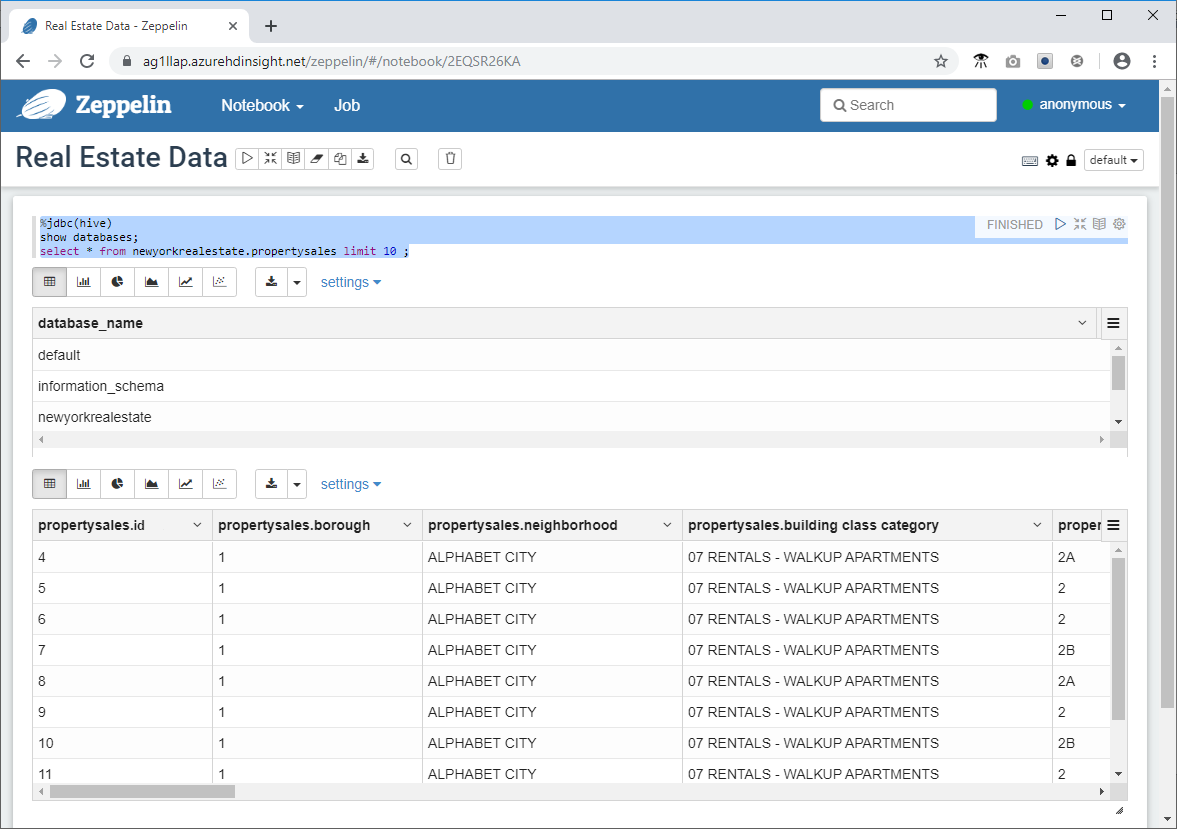
- 次のコード スニペットを Zeppelin ウィンドウのコマンド プロンプトに貼り付け、再生アイコンをクリックします。
%jdbc(hive)
show databases;
select * from newyorkrealestate.propertysales limit 10 ;
クエリ出力がウィンドウに表示されます。 最初の 10 件の結果が返されることがわかります。
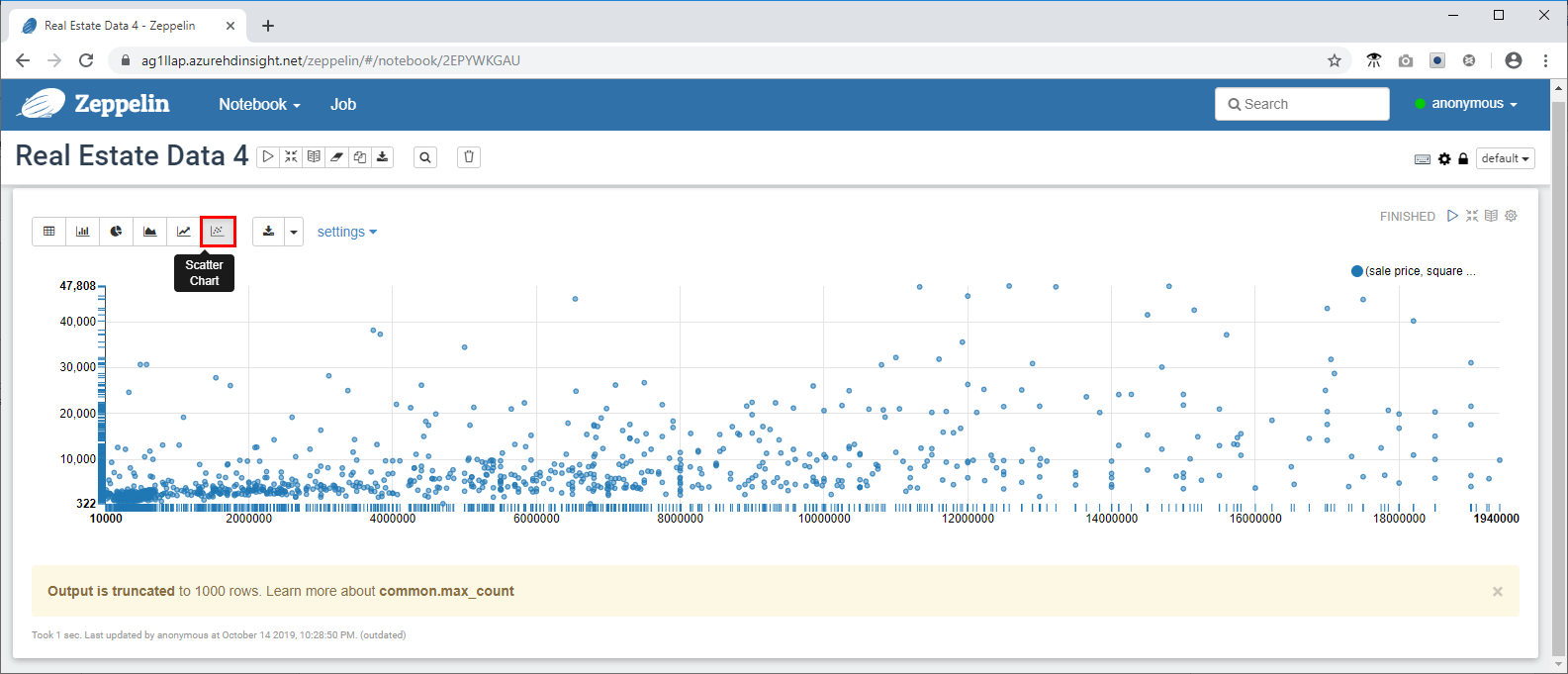
- Zeppelin で使用できる視覚化とグラフ機能の一部を使用するために、より複雑なクエリを実行します。 コマンド プロンプトに次のクエリをコピーし、 をクリックします。
%jdbc(hive)
select `sale price`, `square footage` from newyorkrealestate.propertysales
where `sale price` < 20000000 AND `square footage` < 50000;
既定では、クエリ出力はテーブル形式で表示されます。 代わりに、[散布図] を選択して、Zeppelin Notebook で提供されるビジュアルの 1 つを表示します。