不足データを処理する
欠損データとは、データセット内の特定の変数の値が欠落していることを指します。
欠損データの処理は、機械学習プロジェクトの前処理フェーズの重要な側面であり、それらの処理方法がモデルのパフォーマンスに大きな影響を与える可能性があります。
不足している値がないか確認する
前のユニットの住宅価格のシナリオに戻って、注意が必要な df データフレームで欠損値が発生したとします。
Data Wrangler で欠損データを確認するには、まず Microsoft Fabric ノートブックから Data Wrangler を起動する必要があります。 その後、いくつかのオプションがあります。
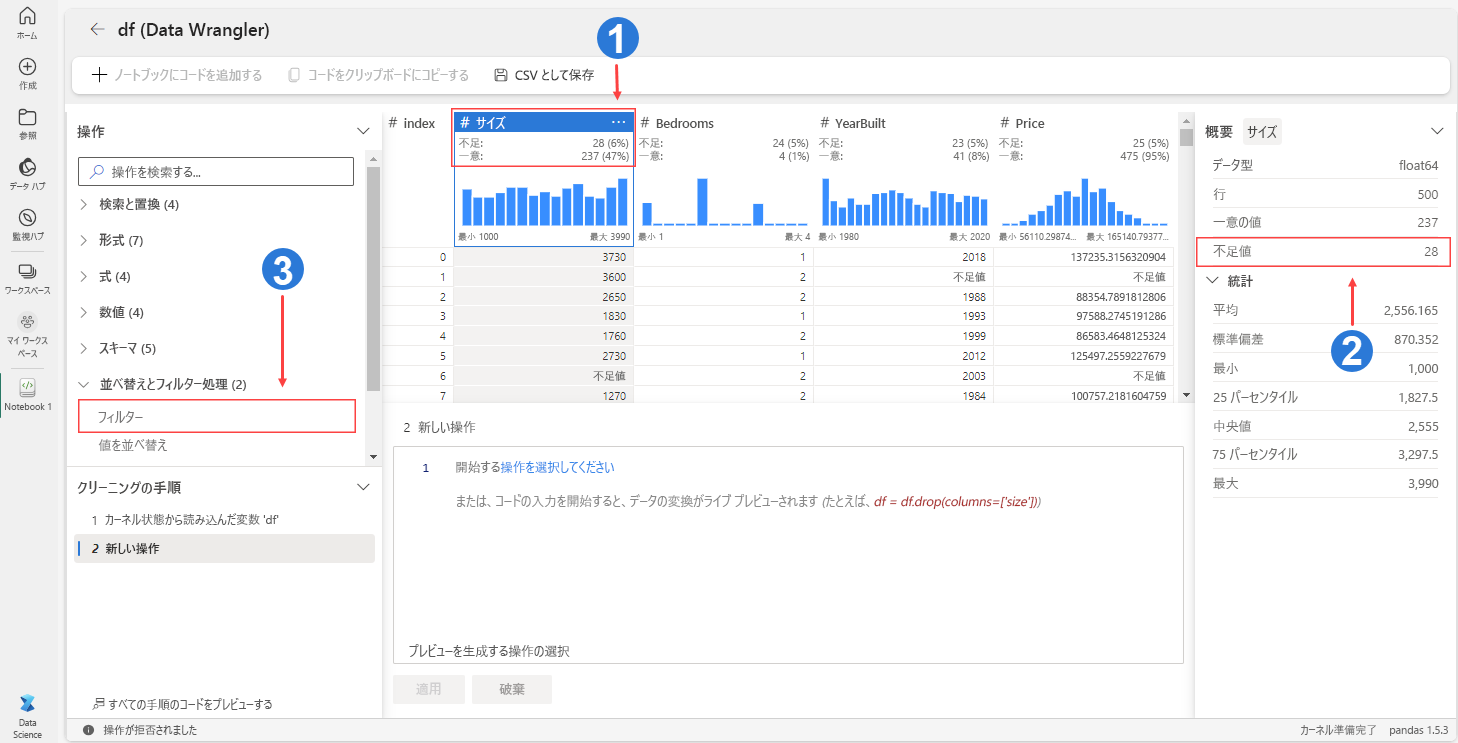
- 列ヘッダー:グリッドの上部に各変数の欠損値の数と割合が表示されます。
- 概要パネル:欠損値を含む、選択した列またはデータフレームの概要の統計情報を強調表示します。
- フィルター演算子:1 つ以上の条件に基づいて行をフィルター処理します。 このオプションは、列の [その他のオプション] を選択した場合にも列ヘッダーで使用できます。
欠損データの処理
欠損データを処理する方法には、いくつかのオプションがあります。
無視:最小限の欠落データは、モデルに大きな影響を与えない可能性があります。
削除:欠損値が多い行または列は、削除した方が良い場合があります。
補完:欠損値を、指定された値または推定値 (平均値、中央値、モードなど)、または K ニアレスト ネイバー (KNN) などの機械学習アルゴリズムを使用して入力します。
新しい特徴として使用する:場合によっては、値が欠測しているという事実自体が情報として使用されることがあります。 たとえば、製品アンケートで、製品の推奨に関する質問に回答しないということは、顧客の不満を示している可能性があります。 この場合、応答なしは、顧客が不満を持つ可能性を示す新しい特徴である可能性があります。
欠損値を削除する
次の手順では、Data Wrangler のターゲット列で欠損値のある行を削除する方法を示します。
[操作] パネルで、[検索と置換] を選択し、[欠損値をドロップする] を選択します。
[価格] 列を選択します。
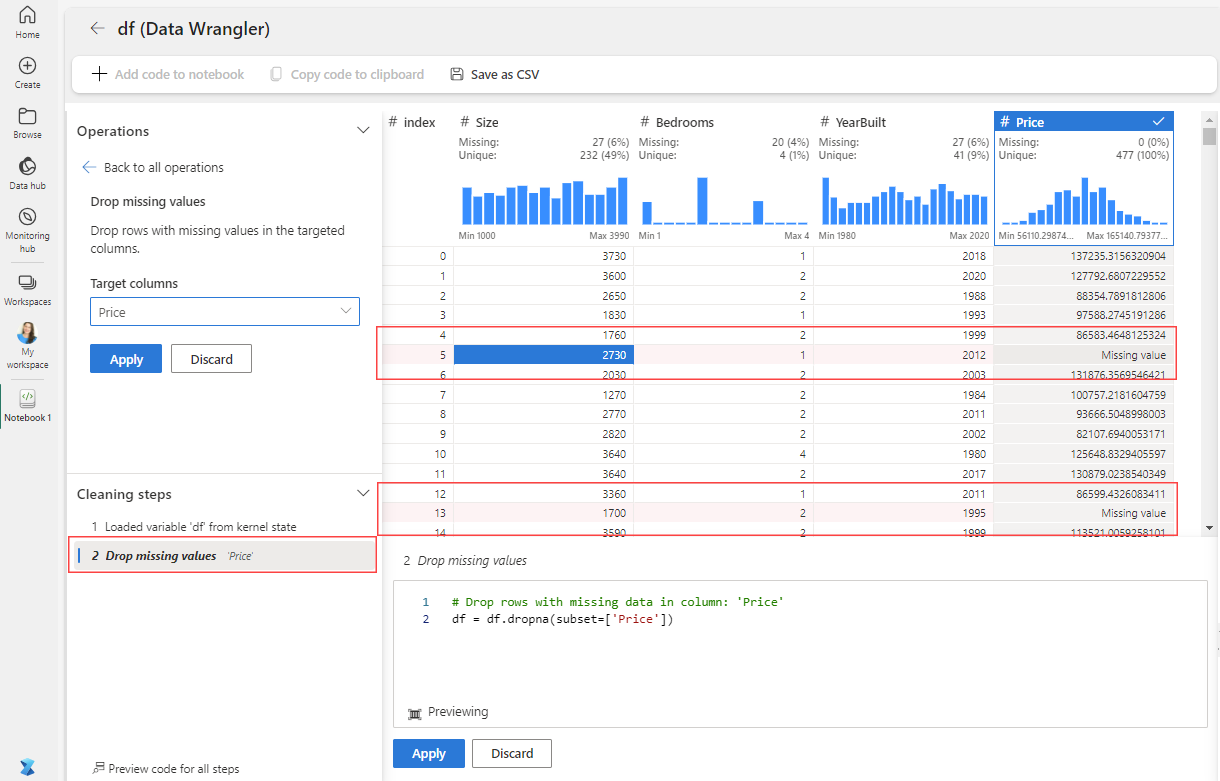
削除対象としてマークされた行は、グリッド内で赤で強調表示され、[クリーニング ステップ] パネルに追加されます。 この視覚的な合図により、機敏性が向上するだけでなく、必要に応じて調整が可能になります。
[適用] を選択します。 変更が有効になり、グリッドによってステップが適用されます。
欠損値の補完
データセットに欠損データがある場合は、いくつかの補完方法を使用してそれらのギャップを埋めることができます。 各方法には独自の利点があり、異なる種類のデータや状況に適しています。
これらの方法を理解すると、特定の状況で欠損データを処理するための最も適切な戦略を選択するのに役立ちます。
| メソッド | 説明 |
|---|---|
| Mean (平均値) | 欠損値をその変数の平均値に置き換える。 外れ値のない連続データに適しています。 |
| 中央値 | 欠損値をその変数の中央値に置き換える。 平均値よりも外れ値に対する堅牢性が高くなります。 |
| モード | 欠損値をその変数のモード (最も頻度の高い) 値に置き換える。 カテゴリ データに適しています。 |
| 前方に伝達 | 欠損値をデータセット内の前の有効な値で埋めます。 前方フィルとも呼ばれます。 |
| 後方に伝達 | 欠損値をデータセット内の次の有効な値で埋めます。 後方フィルとも呼ばれます。 |
| カスタム値 | 欠損値をユーザー定義の定数値に置き換えます。 これは、データのコンテキストで意味のある任意の値を指定できます。 |
以降の手順では、たとえば中央値を使用して、対象となる列の欠損値を入力または補完する方法を示します。
[操作] パネルで、[検索と置換] を選択し、[欠落値を入力する] を選択します。
[YearBuilt] 列を選択し、[中央値] の塗りつぶし方法を選択します。
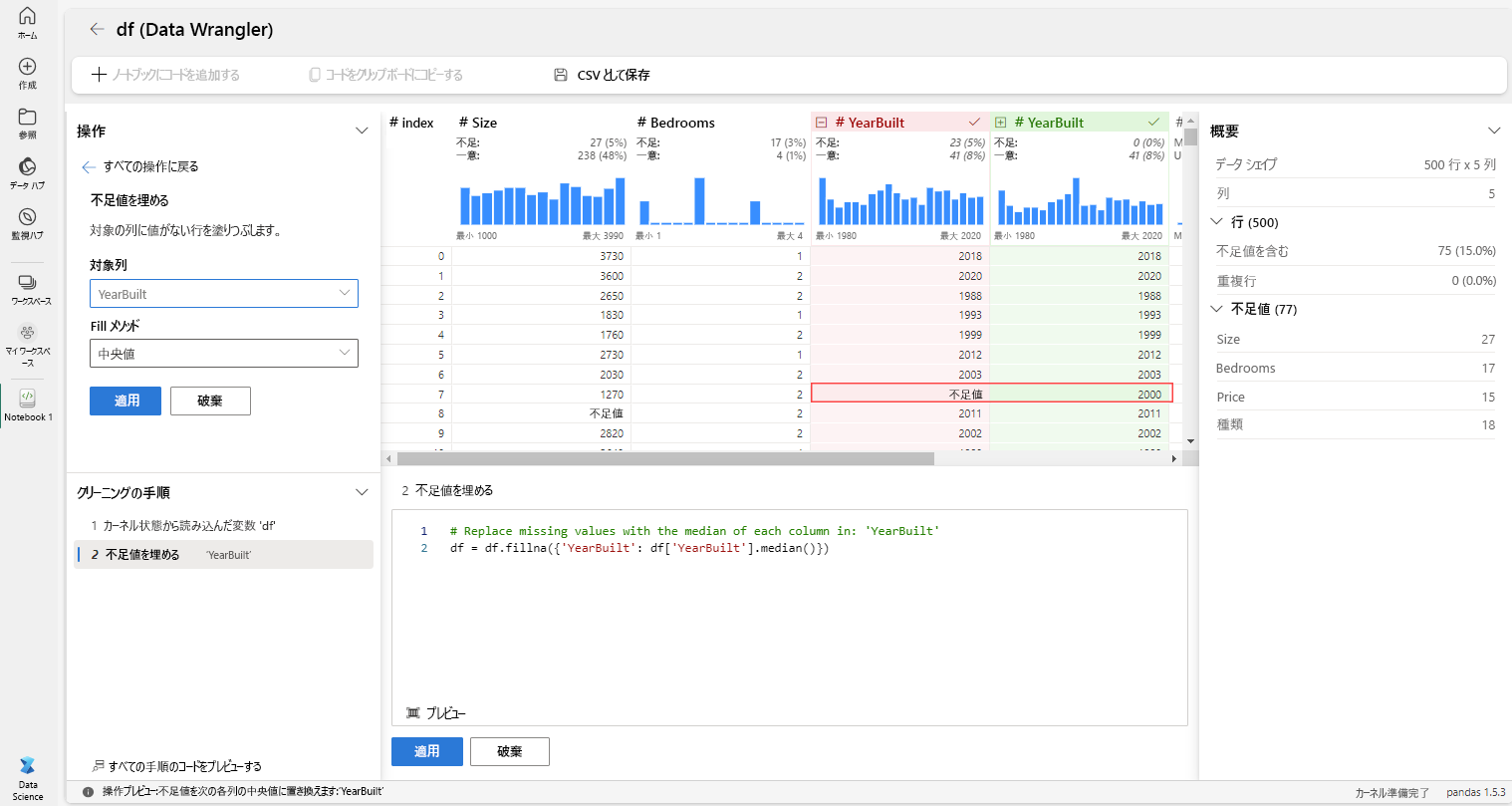
補完対象としてマークされた行は、グリッド内で赤で強調表示され、[クリーニング ステップ] パネルに追加されます。 この視覚的な合図により、必要に応じてリアルタイムの変更が容易になります。
[適用] を選択します。
変更はすぐに Data Wrangler の表示グリッドに表示され、操作がデータセットに与える影響をリアルタイムで確認できます。
または、カスタム操作演算子を使用して、独自の補完コードを作成することもできます。
欠損データの詳細については、「Microsoft Fabric のノートブックを使用してデータ サイエンスのためにデータを探索する」を参照してください。