Delta Lake について理解する
Delta Lake は、Spark ベースのデータ レイク処理にリレーショナル データベースのセマンティクスを追加する、オープンソースのストレージ レイヤーです。 Microsoft Fabric Lakehouses のテーブルは Delta テーブルです。これは、Lakehouse ユーザー インターフェイスのテーブルの三角形のデルタ (Δ) アイコンで表されます。
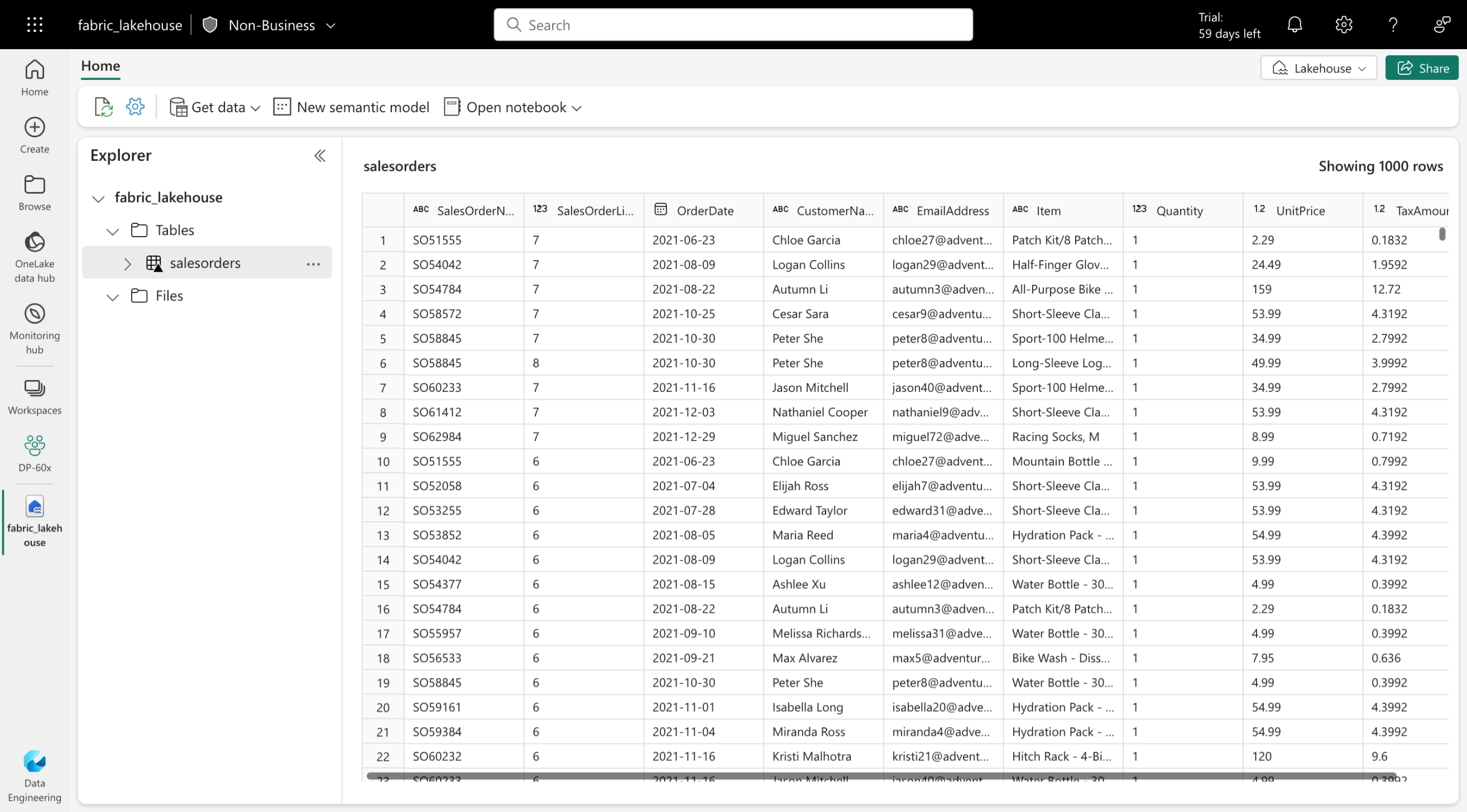
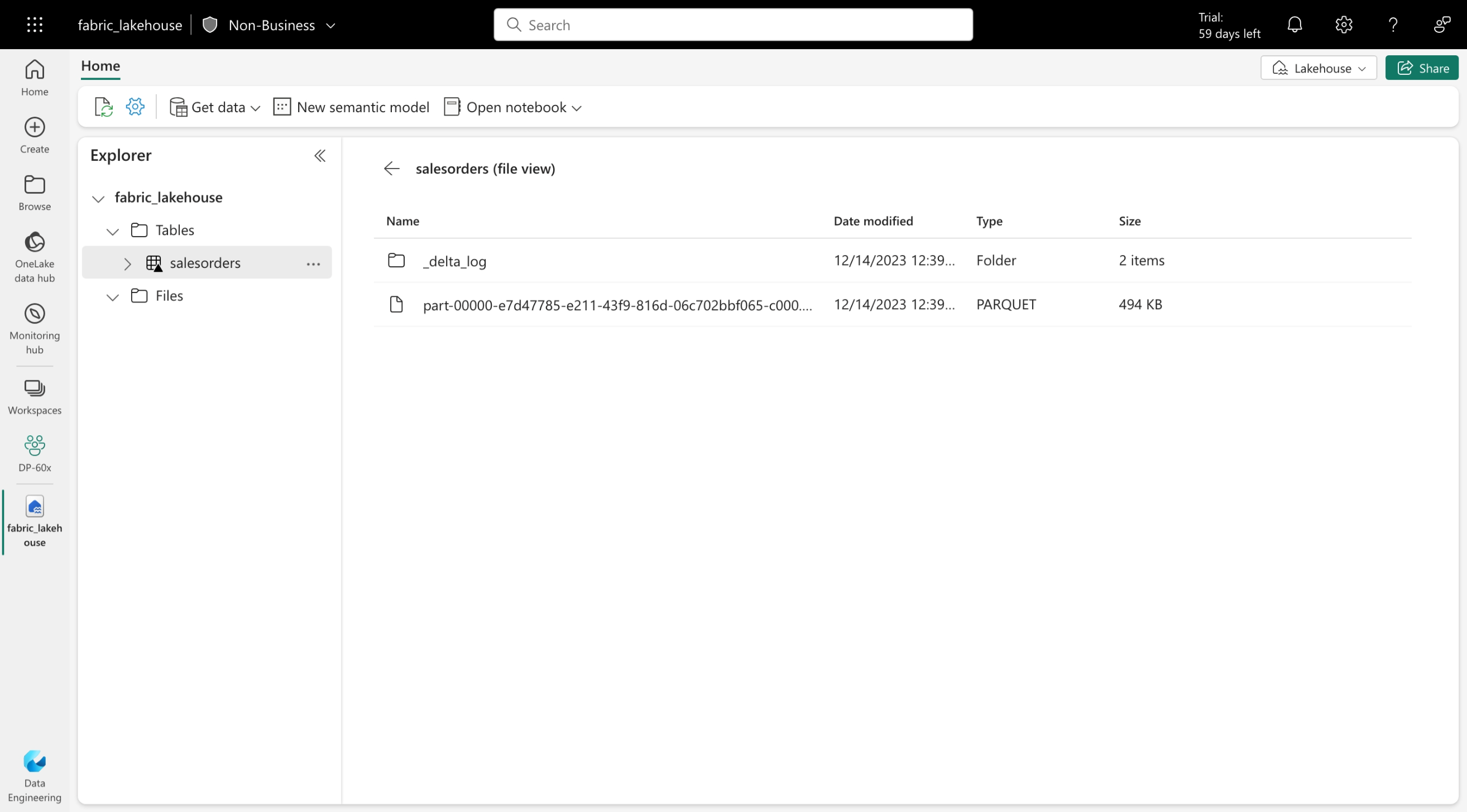
Delta テーブルは、Delta 形式で格納されているデータ ファイルに対するスキーマの抽象化です。 テーブルごとに、Lakehouse には Parquet データ ファイルを含むフォルダーと、トランザクションの詳細 が JSON 形式でログに記録される_delta_Log フォルダーが格納されます。
Delta テーブルを使用する利点は次のとおりです。
- クエリとデータ変更をサポートするリレーショナル テーブル。 Apache Spark を使用すると、 CRUD (作成、読み取り、更新、および削除) 操作をサポートする Delta テーブルにデータを格納できます。 つまり、リレーショナル データベース システムと同じ方法で、データ行の "選択"、"挿入"、"更新"、"削除" を行うことができます。
- ACID トランザクションのサポート。 リレーショナル データベースは、 アトミック性 (トランザクションが 1 つの作業単位として完了)、 一貫性 (トランザクションがデータベースを一貫した状態に保つ)、 分離 (インプロセス トランザクションが相互に干渉できない)、 持続性 (トランザクションが完了すると変更が保持される) を提供するトランザクション データの変更をサポートするように設計されています。 Delta Lake は、トランザクション ログを実装し、同時実行操作にシリアル化可能な分離を適用することで、この同じトランザクション サポートを Spark にもたらします。
- データのバージョン管理と 移動時間。 すべてのトランザクションがトランザクション ログに記録されるため、各テーブル行の複数のバージョンを追跡することができ、"タイム トラベル" 機能を使ってクエリ内の行の以前のバージョンを取得することもできます。
- バッチ データとストリーミング データのサポート。 ほとんどのリレーショナル データベースには静的データを格納するテーブルが含まれていますが、Spark には Spark Structured Streaming API を使用したストリーミング データのネイティブ サポートが含まれています。 Delta Lake テーブルは、ストリーミング データの "シンク" (宛先) と "ソース" の両方として使用できます。
- 標準形式と相互運用性。 Delta テーブルの基になるデータは Parquet 形式で格納されます。これは、データ レイク インジェスト パイプラインでよく使用されます。 さらに、Microsoft Fabric レイクハウスの SQL 分析エンドポイントを使用して、SQL 内の Delta テーブルのクエリを実行することもできます。