この記事では、アプリケーション関連の問題のトラブルシューティングに役立つ Azure Monitor Application Insights の機能について説明します。
Note
この記事は、従来のクラウド サービスとクラウド サービスの延長サポートの両方に適用されます。
Cloud Service アプリの Application Insights を構成する
Application Insights でアプリを監視するには、次の手順に従います。
- Visual Studio ソリューション エクスプローラーの Our Cloud Service>Roles で、各ロールのプロパティを開きます。
- Configuration で、 [診断データを Application Insights に送信する] チェック ボックスをオンにし、前に作成した Application Insights インスタンスを選択します。
Web ロールの場合は、このオプションによってパフォーマンスの監視、アラート、診断、使用状況の分析が提供されます。 その他のロールについては、再起動やパフォーマンス カウンターなど、Azure Diagnostics を検索して監視できます。
![[診断データを Application Insights に送信する] チェックボックスを有効にする方法を示すスクリーンショット。](media/troubleshoot-with-app-insights-features-overview/enable-app-insights-for-cloud-services.png)
Application Insights のエラーを診断する
Application Insights には、監視対象のアプリケーションでのエラーの診断に役立つ、キュレーションされた Application Performance Management エクスペリエンスが用意されています。 Azure portal でエラーを表示するには、Application Insights インスタンスに移動し、Investigate の下にある Failures を選択します。
![Application Insights の [エラーの診断] ページを示すスクリーンショット。](media/troubleshoot-with-app-insights-features-overview/failures0719.png)
要求の失敗率の傾向、失敗の数、影響を受けたユーザーの数が表示されます。 失敗した操作テーブル1 には、要求 URL でグループ化された失敗した要求が表示されます。 [全体] ビュー2には、上位 3 つの応答コード、上位 3 つの例外の種類、および失敗した上位 3 つの依存関係の種類が表示されます。
これらの操作のサブセットごとに代表的なサンプルを確認するには、対応するリンクを選択します。 たとえば、例外を診断するには、特定の例外の数を選択します。すると、それが [エンドツーエンド トランザクションの詳細] タブに表示されます。
![[エンドツーエンド トランザクションの詳細] タブを示すスクリーンショット。](media/troubleshoot-with-app-insights-features-overview/end-to-end.png)
エンド ツー エンド トランザクションの詳細の次の情報は、トラブルシューティングに役立ちます。
- 要求のタイムスタンプ
- 応答コード
- 応答時間
- 例外メッセージ
- 例外の種類
- 呼び出し履歴
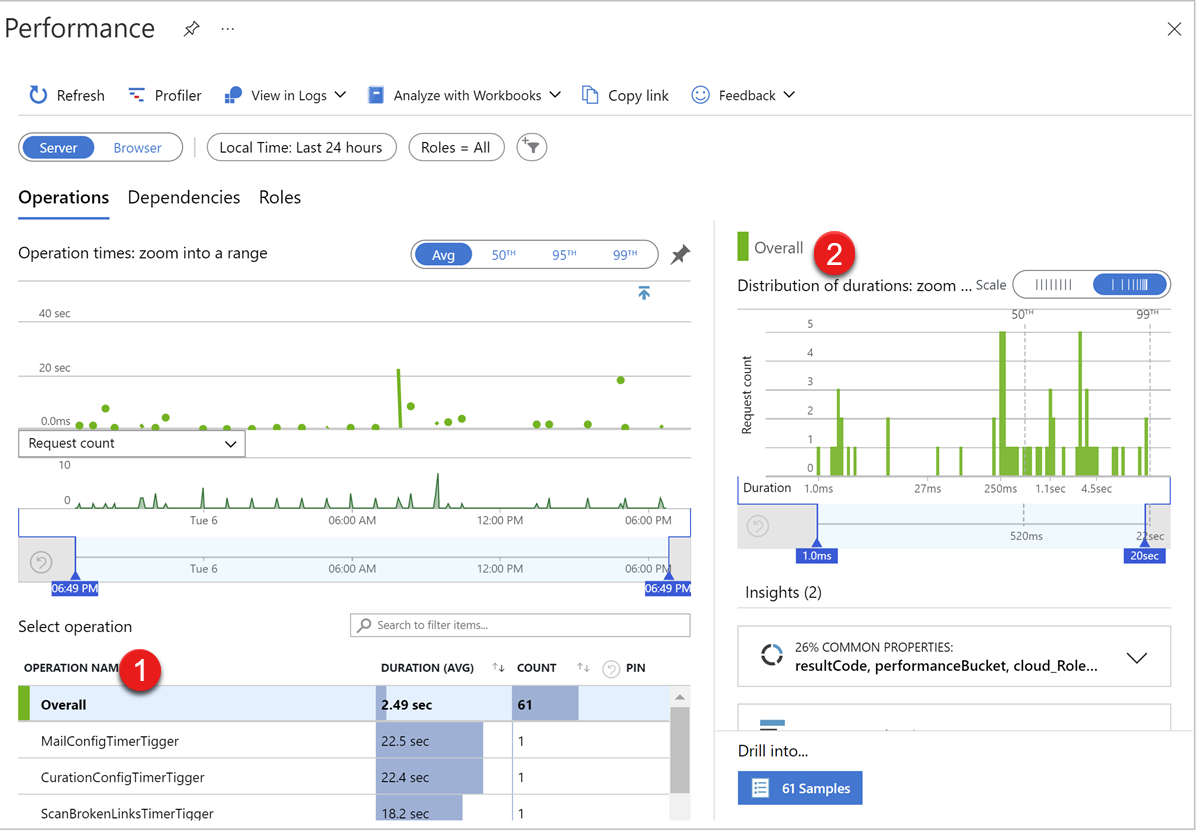
Application Insights のパフォーマンスの問題を診断する
Web ロールのパフォーマンスの問題を診断するには、Application Insights インスタンスの Performance ページで次のデータを確認します。
- Web ロール要求の応答時間
- CPU、メモリ、ディスク IO、Web ロール インスタンスのネットワーク IO
Operations タブの失敗した操作テーブル1には、要求操作の名前、期間、要求数の概要が表示されます。 操作を選択すると、メトリック グラフ2 が更新され、要求の量と期間のメトリック グラフが表示されます。
Roles タブには、CPU、使用可能なメモリ、各インスタンスによって処理される要求など、クラウド サービス サーバーに関連するメトリック データが表示されます。
Application Insights でのアラート
アラートを使用すると、ユーザーはクラウド サービス ロール インスタンスの状態を監視するカスタム ルールを設定できます。 監視対象のイベントが発生すると、ユーザーは電子メール通知を受け取ることができます。
ルールには主に、条件とアクションという 2 つの重要な部分が含まれています。 アラートを作成するには、次の手順に従います。
Azure portal で Application Insights インスタンスに移動し、Monitoring セクションで Alert を選択します。 このページでは、トリガーされたすべてのアラートを確認できます。 + 作成を展開し、 Alert rule を選択します。
条件を設定する。 条件は、シグナル、ディメンション、アラート ロジックの 3 つのポイントで構成されます。 詳細については、「 Azure Monitor アラートの種類」を参照してください。
- シグナルは、アラート ルールが監視するメトリック データの種類です。 CPU、使用可能なメモリ、失敗した要求、例外、応答時間などの一般的なメトリック データを使用できます。
- ディメンションは、このアラート ルールを適用するスコープまたはフィルターを指定します。 クラウド サービス メトリック データに基づくアラート ルールの場合、通常、クラウド ロール インスタンスとクラウド ロール名という 2 つのディメンションの選択肢が含まれます。 これら2つの次元に加えて、信号に応じて他の選択肢もあります。
- アラート ロジックでは、アラート ルールの条件のロジックを設定する必要があります。 いくつかの重要な概念があります。
- しきい値は、評価結果が動的か静的かを意味します。 静的な場合、評価されたメトリック データ (この例では失敗した要求数) は、5 や 10 などの静的な値と比較されます。 動的な場合、評価されたデータは過去 5 分間など、過去短い期間の同じデータと比較されます。
- 演算子、集計の種類、しきい値、および単位は簡単に理解できます。これらはロジックの本体を表します。
- 集計の粒度 ("期間" とも呼ばれます) は、履歴のメトリック データが評価される期間です。 5 分の場合は、過去 5 分間のメトリック データが評価されることを意味します。 評価の頻度は、評価がトリガーされる頻度を意味します。
アラート ルールがトリガーされたときにアクションを設定します。 新しいアクション グループを作成してこのアラート ルールに追加するか、既存のアクション グループを使用できます。
新しいアクション グループを作成するには、次の手順に従います。
- アクション グループ リソースが作成されるサブスクリプションとリソース グループを選択し、名前と表示名を指定します。
- 省略可能) 特定のメール アドレスにメールを送信するなど、アラート ルールがトリガーされたときにユーザーに通知する方法を選択します。
- (省略可能)実行するアクションを選択します。 このオプションでは、Automation Runbook、Azure 関数、およびその他の 5 種類のサービスをトリガーできます。
アクション グループが作成されると、アラート ルールにも追加されます。
Details ページで、アラート ルールを保存するサブスクリプションとリソース グループを選択し、その名前と重大度レベルを設定します。
Application Insights のメトリック グラフ
Application Insights のメトリック グラフを使用して、データ変更を視覚化できます。 これは、数日または数週間などの時間範囲でサービスの状態を監視するのに非常に便利です。
監視対象のデータは、次の点で構成できます。
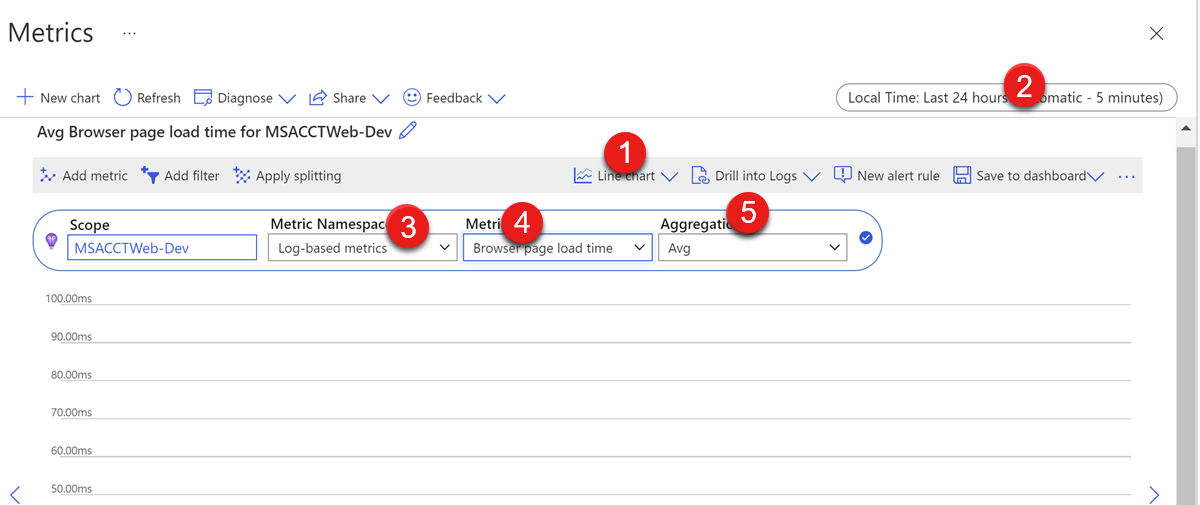
- グラフの種類 - 表示するグラフの種類。 折れ線グラフ、面グラフ、横棒グラフ、散布図、およびグリッドを選択できます。
- 時間範囲 - グラフを生成するメトリック データの時間範囲 (現地時刻と UTC の違いに注意してください)。
- メトリック名前空間 - 使用可能なメトリック データのグループ。 通常は、ログ ベースと Application Insights の標準メトリックのどちらかを選択するだけで済みます。 CPU、メモリ、要求、例外など、すべてのデータが既定で収集されます。 w3wp プロセスのプロセッサ時間 (クラウド サービスの診断設定で構成可能) など、カスタマイズされた設定によって収集されるより具体的なデータは、ログ ベースのメトリックに含まれます。
- メトリック - グラフを生成するデータ。
- 集計 - 複数のメトリック値から計算される統計の種類。 詳細については、このドキュメントを参照してください。 既定値のままにすることを強くお勧めします。 このメトリック データ型の収集方法と、すべての集計の種類の違いを理解している場合にのみ変更する必要があります。
ヒント
場合によっては、グラフに点線が表示されることがあります。 これは、その期間中のデータが十分に正確ではないか、収集されていないことを意味します。 その理由は、その期間中のデータが続行されていないことです。 メトリック データが 2 分ごとに収集され、グラフ内の 2 つのポイント間の時間差が 1 分の場合、データはグラフを生成するのに十分な精度が得られないため、点線になるとします。
Application Insights で収集されたログ
上記の Application Insights のほぼすべての機能は、ログとして収集されたデータに基づいています。 また、ユーザーがこれらのログを直接確認して、ページに表示されないより詳細な情報を取得することもできます。
ログを表示するには、Monitoring セクションで Logs を選択します。
[ログ] ページで、Kusto 照会言語 (KQL) を使用して、収集されたログのクエリまたはフィルター処理を行い、必要な情報を取得する必要があります。
注意が必要な点は 2 つだけです。時間範囲とクエリ。
上部の時間範囲は、確認するログの時間範囲を設定できます。 現地時刻と UTC の違いに注意してください。
クエリは、最初の行のテーブル名と、結果をフィルター処理するために使用する条件の 2 つの部分で構築されます。
一般的に使用されるテーブルを次に示します。
| Application insights インスタンスのテーブル | 説明 |
|---|---|
| requests | クラウド サービスに送信され、記録された要求 |
| exceptions | 未処理の例外と記録された処理済み例外 |
| パフォーマンス カウンター | パフォーマンス データ |
次の表のデータは、カスタム診断設定によって収集されます。
| Application insights インスタンスのテーブル | 診断設定の名前 |
|---|---|
| traces | アプリケーション ログ |
| traces | ETW ログ |
| traces | インフラストラクチャ ログ |
| traces/custom イベント | Windows イベント ログ |
| カスタム メトリック | パフォーマンス カウンター |