このシナリオ ガイドでは、パフォーマンス モニターを使用してデータを収集する方法と、データを使用してコンピューターの速度を低下させるボトルネックを絞り込む方法について説明します。 一般的なアプローチを紹介し、トラブルシューティングの概念を説明しようとします。
パフォーマンス モニターを使用してパフォーマンス データを記録する
Windows のすべてのフル バージョンには、パフォーマンス モニターと呼ばれる受信トレイ ツールが付属しています。 このツールを使用すると、Windows に組み込まれているパフォーマンス カウンターを使用して、Windows システムのさまざまな側面に関するパフォーマンス関連の情報を追跡できます。これにより、中央処理装置 (CPU) の使用量またはメモリ使用量に関する詳細情報が提供されます。
すべてのカウンターは、同じ簡単な方法で構築されます。
[Performance counter object]\<Instance>\<Counter Name>
例えば次が挙げられます。
[Processor Information]\<CPU 0\>\% Processor Time
カウンターによって提供されるパフォーマンス データを格納するには、パフォーマンス モニターで Data コレクター セットを使用できます。 次のスクリーンショットをご覧ください。
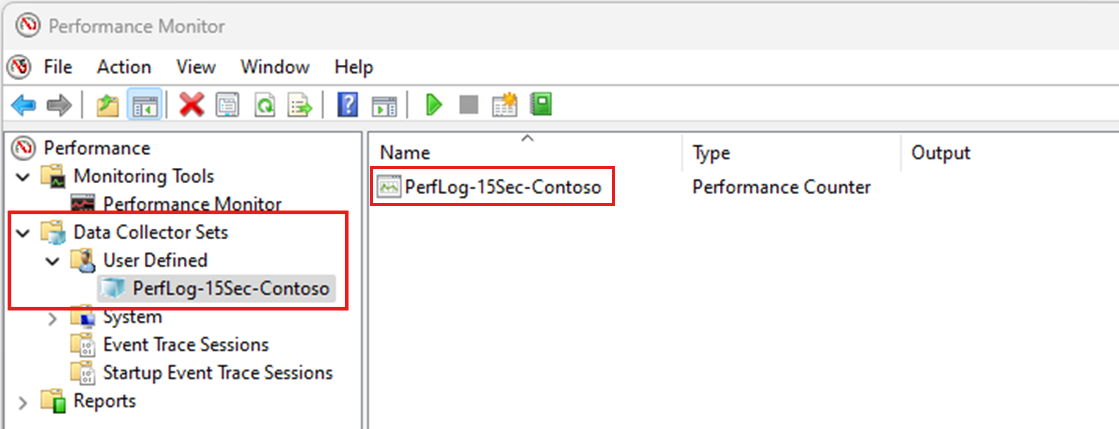
これらの Data コレクター セットを作成するには、グラフィカル ユーザー インターフェイス (GUI) または logman.exe コマンドを使用します。
データ コレクター セットを作成するには、管理者特権のコマンド プロンプト ウィンドウで次のコマンドを実行します。
logman.exe create counter PerfLog-15Sec-Contoso -o "c:\perflogs\Contoso_PerfLog-15sec.blg" -f bincirc -v mmddhhmm -max 800 -c "Hyper-V Dynamic Memory Balancer (*)\*" "Hyper-V Hypervisor Virtual Processor(*)\*" "Hyper-V Hypervisor Logical Processor(*)\*" "\LogicalDisk(*)\*" "\Memory\*" "\Cache\*" "\Network Interface(*)\*" "\Paging File(*)\*" "\PhysicalDisk(*)\*" "\Processor(*)\*" "\Processor Information(*)\*" "\Processor Performance(*)\*" "\Process(*)\*" "\Process V2(*)\*" "\Redirector\*" "\Server\*" "\System\*" "\Server Work Queues(*)\*" "\Terminal Services\*" -si 00:00:15
カウンターを開始するには、管理者特権のコマンド プロンプト ウィンドウで次のコマンドを実行します。
logman.exe start PerfLog-15Sec-Contoso
このコマンドを実行すると、システムに "フライト ボックス レコーダー" のようなモニターが生成されます。 モニターは、パフォーマンス データを 15 秒ごとにログに記録します (間隔については、 -si 00:00:15 を参照してください)。 コレクター セットが起動されるたびに、システムへの影響は 1% 未満である必要があり、ローカル ハード ディスクに 800 MB を超える領域は使用されません。 コンピューターを再起動する場合は、コマンドを実行してモニターを再起動する必要があります。
カウンターを停止するには、管理者特権のコマンド プロンプト ウィンドウで次のコマンドを実行します。
logman.exe stop PerfLog-15Sec-Contoso
データ コレクター セットは、 [Performance counter object]\<Instance>\<Counter Name>の原則にも従います。 このオブジェクトにはインスタンスがないため、カウンター オブジェクトは "Memory" と呼ばれます。 その理由は、Windows には 1 つのメモリがありますが、複数のハード ディスクまたは CPU がある可能性があるためです。
これで、15 秒ごとにデータをログに記録するデータ コレクター セットが作成されました。 データの分析に使用されるツールの制限により、15 秒が選択されます:パフォーマンス モニター。
グラフ内には最大 1,000 個のデータ ポイントを表示できます。 データ コレクターが 1 秒ごとにデータをログに記録するように構成されている場合、グラフは 16 分 40 秒でしかデータを表示できません。 ログにさらに多くのデータがある場合は、それらのデータ ポイントの "集計と結合" が開始されます。 キャプチャは高密度キャプチャとして呼び出されます。
これにより、グラフに正確な数値が表示されない場合があります。 グラフを見て、それを Minimum または Maximum 値と比較することで見つけることができます。
この例では、カウンター オブジェクト Processor のインスタンス _Totalのカウンター % アイドル時間を確認します。 最小値に基づいて、グラフは青い線 (32%) にヒットする必要がありますが、true ではありません。 数値とグラフが一致しないため、表示される期間内 (22 分 01 秒) 内のサンプルの数を確認する必要があります。 カーソルを合わせると、"フライアウト" は、このデータ ポイントに存在するサンプルの数を示します。 ご覧のように、10 個のサンプルがあるため、ツールは 1 秒間隔のキャプチャであったため、それらを要約して結合する必要があります。

Windows を簡略化する
パフォーマンス カウンター ログが作成されたので、分析に役立つ方法で Windows を簡略化してみましょう。 これを行うには、システムを論理コンポーネント (メモリ、ストレージ、CPU、ネットワーク) に分割します。
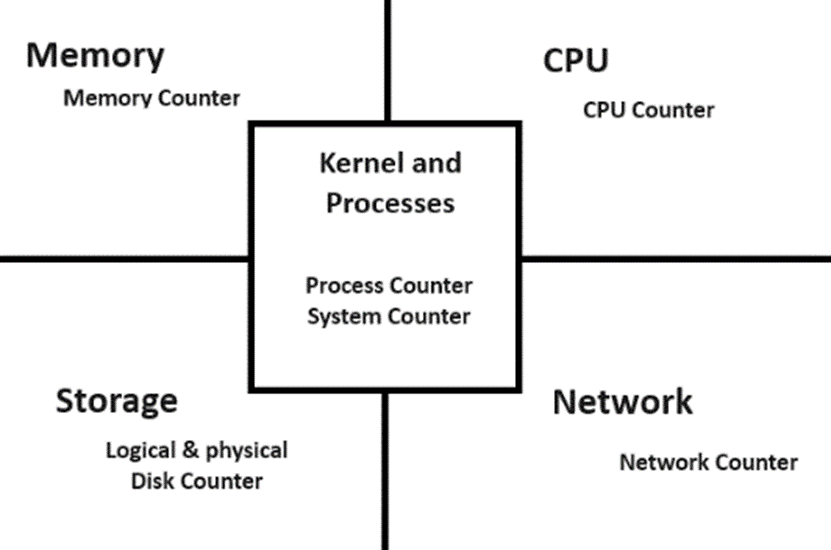
一部のパフォーマンス モニター オブジェクトを物理リソースにマッピングするだけでなく、Windows は Kernel と User モードの 2 つの主要な領域に分かれていることに注意してください。
カーネル はオペレーティング システム (OS) とドライバーを指します (これにはウイルス対策フィルター ドライバーも含まれます)。 カーネルは、 System Process という論理コンストラクトによって Windows で表され、常にプロセス ID 4。 セキュリティ上の理由から、この領域は強力に保護されています。 パフォーマンス モニターなどの受信トレイ ツールを使用しても、そこから取得できる情報はごくわずかです。 たとえば、使用している非ページ プールの量を確認できますが、使用しているユーザーに関する情報はありません。
ユーザー モードでは、すべてのアプリケーション (最新の Appx、サービス、実行可能ファイル) が実行されます。 パフォーマンス モニターを使用すると、各プロセスに関する情報を取得できます。
18 個の最も重要なカウンターを導入する
簡略化するために、次のセクションでは、18 個の最も重要なカウンターとそのしきい値を、関連する物理リソース別に分けて紹介します。
ストレージ
| プライマリ カウンター | Healthy | 警告 | [重大] |
|---|---|---|---|
| \LogicalDisk(*)\Avg. Disk sec/Read | < 15 ミリ秒 | >25 ミリ秒以下 | > 50 ミリ秒未満 |
| \LogicalDisk(*)\Avg. Disk sec/Write | < 15 ミリ秒 | >25 ミリ秒以下 | > 50 ミリ秒未満 |
| \PhysicalDisk(*)\Avg. Disk sec/Read | < 15 ミリ秒 | >25 ミリ秒以下 | > 50 ミリ秒未満 |
| \PhysicalDisk(*)\Avg. Disk sec/Write | < 15 ミリ秒 | >25 ミリ秒以下 | > 50 ミリ秒未満 |
Note
短いスパイクは許容できます。 長い待機時間 (1 分以上) を調査する必要があります。
これらのカウンターは待機時間を表します。 待機時間は、情報の取得に費やす時間によって定義されます。 ディスク パフォーマンスの観点から、セットアップを詳しく見る必要があります。 通常のハード ディスクの場合、ソリッド ステート ハード ドライブ (SSD) ではなく、ディスクの回転数は通常 5,400 回転/分 (RPM) です。 つまり、ディスクは 1 分あたり 5,400 回スピンドル (情報がブロックとして格納される場所) を回します。 ディスクからブロックを読み取るまでにかかる時間を計算できる必要があります。
1 ブロック / (RPM/ 60) = 1 ブロックの待機時間
1 ブロック / 5400 RPM / 60 = 0.011111 秒 = 11 ミリ秒
したがって、理論上、ディスクは 11 ミリ秒以内に任意のブロックを読み取ることができる必要があります。 ~100 msの待機時間がある場合、ディスクはブロックを少なくとも 8 回読み取ることができる必要があるため、遅延が発生するのはなぜですか。 ディスクに負荷がかかっており、その場合、誰がそれを使用していますか?
使用しているユーザーを特定するために、 Process カウンター オブジェクトを確認できるようになりました。
ディスク操作に関連するプロセス カウンター:
- \Process(*)\IO 読み取り操作/秒 (プロセス固有のディスク読み取り時間)
- \Process(*)\IO 書き込み操作/秒 (プロセス固有のディスク書き込み時間)
これらのカウンターを使用して、待機時間またはディスク使用量をプロセスの使用状況と関連付けることができます。
次の物理コンポーネントに進みましょう。
[メモリ]
| 仮想メモリと物理メモリ カウンター | Healthy | 警告 | [重大] |
|---|---|---|---|
| \Memory\Pool Paged Bytes | Pool Nonpaged Bytes | 0–50% | 60–80% | 80–100% |
| \Memory\Available MBytes | > 10% または少なくとも 4 ギガバイト (GB) 無料 | < 10% | < 1% または 500 MB 未満 |
| \Memory\% Committed Bytes in use | 0–50% | 60–80% | 80–100% |
このセクションでは、次のカウンターについて説明します。
- プール ページ バイト数
- プールの非ページ バイト数
これらのカウンターは、システム全体で共有されるカーネル リソースを表します。 プロセスはページングされたプールと非ページ プールを要求できますが、これは主にドライバーによって行われます。そのため、データはパフォーマンス モニターに対して表示されません。 ページ プールはページ ファイルにページングできますが、非ページ プールではページアウトできません。 これらのカーネル リソースは、システム内のメモリ (ランダム アクセス メモリ (RAM) のサイズに依存します。 非ページ プールの制限は RAM の 75% であり、 Available MBytesに直接影響します。 使用可能な MBytes は、カーネルを含むすべてのプログラムで使用可能な RAM の量です。
プロセスが RAM 使用率に与える影響を理解するには、次のカウンターを使用できます。
| プロセス カウンター | コメント |
|---|---|
| \Process(*)\Working Set | RAM の上位コンシューマーを識別するために、 Available MBytes に関連付けてみてください。 ワーキング セット は、プロセスが任意の時点で使用する RAM (ページ ファイルではない) の量として定義されます。 |
Memory\% Committed Bytes In Use は Windows の仮想メモリを表します。 これは、ページ ファイルと RAM の組み合わせで、Task Manager で表示できますMemory選択した後タブで。

このシステムには 128 GB の RAM と 128 GB のページ ファイルがあるため、 Committed メモリは 256 GB です。 また、ページ プール非ページ プールメモリを確認することもできます。
メモリの問題を調査するときは、両方の領域 (カーネルとユーザー) が実際に ame 物理リソースを共有することに注意してください。 そのため、コンピューターのメモリが不足している場合は、それを使用しているユーザーを確認してみてください。
次の物理リソースに進みましょう。
CPU
CPU パフォーマンスのトラブルシューティングを行うときは、OS を Kernel に分割し、もう一度ユーザー モードする必要があります。 ただし、分割の方が理解しやすくなります。 ユーザー モードは、CPU サイクルを消費し、CPU 以外のハードウェアを含まないユーザー モードで実行されるアプリケーションを含む、任意のアプリケーションまたはサービスによって表されます。 ハードウェアにアクセスする必要がある場合は、ツールが GPU、ストレージ、またはネットワークにアクセスするためにドライバーと通信する必要がある場合にカーネル モードになります。
次に例をいくつか示します。
- 計算を行う SQL Server = ユーザー モード
- SQL Server によるディスクへのログ ファイルの書き込み = カーネル モード
- ネットワーク共有にアクセスするファイル サーバー = カーネル モード
次に、プライマリ カウンターを見てみましょう。
| プライマリ カウンター | Healthy | 警告 | [重大] |
|---|---|---|---|
| \Processor Information(*)\% User Time (ユーザー モード) | 50% より大きい | 50–80% | > 80% |
| \Processor Information(*)\% Privileged Time (カーネル モード) | < 30% | 30–50% | 50% より大きい |
| \Processor Information(*)\% Idle Time | >20% | >10% | <10% |
繰り返しますが、短いスパイクでもかまいませんが、1 分以上表示される場合は、調査を開始してください。
CPU が使用されるたびに、CPU は % ユーザー時間 (ユーザー モード) または % 特権時間 (カーネル モード) を消費します。 CPU の使用率が高い状況 (= 低 % アイドル時間) が発生した場合は、次のセカンダリ カウンターを参照して、それを使用しているユーザーを確認する必要があります。
| セカンダリ カウンター | コメント |
|---|---|
| \Process(*)\% ユーザー時間 | アクティブなプロセスが複数ある可能性があることに注意してください。 |
| *\Process()\% Privileged Time** | システム プロセスに関する情報は限られているだけであることに注意してください。 システム プロセスは通常、 % 特権時間の最上位ドライバーです プロセス ホストはこの論理コンストラクト内でドライブします。 ただし、これに限定されるわけではありません。 |
100% Process\% ユーザー時間 = 1 CPU。 16 個の CPU がある場合、プロセスが到達できる最大使用量は 1600 % です。 次のスクリーンショットをご覧ください。

この例では、ツールを使用して CPU 使用率 (% ユーザー時間) をシミュレートしました。 ツールを 4 つの CPU (CPU 12、13、14、15) でのみ実行するように制限しました。 4 つのスレッドがアクティブになると、アプリケーション自体 (CPU ストレス) が 400% に達している間に、すべての CPU が 100% に達する方法が明らかになります。 この例では、CPU ストレスの CPU 使用率と、アプリケーションが制限されている CPU の CPU 負荷の関係を示します。 この種の関係を確立することは、基になるプロセスを完全に理解するのに役立ちます。
これにより、最後の物理オブジェクトが表示されます。
ネットワーク
パフォーマンス モニターはローカル ツールであるため、基本的な情報はネットワークからのみ取得できます。 ただし、次のカウンターは引き続き役立ちます。
| プライマリ カウンター | Healthy | 警告 | [重大] |
|---|---|---|---|
| \Network Interface(*)\Bytes Total/sec | 50% より大きい | 50–80% | > 80% |
| \Network Interface(*)\Bytes Sent/sec | * | * | * |
| \Network Interface(*)\Bytes Received/sec | * | * | * |
Note
星の記号 (*)でマークされたセルの詳細: \Network Interface(*)\Bytes Sent/sec および \Network Interface(*)\Bytes Received/sec のワークロードは、サーバーの役割によって異なります。 たとえば、1 秒あたりに送信されるバイト数は、通常、ストリーミング サーバーで 1 秒あたりに受信したバイト数よりも大きくなります。 これに対し、1 秒あたりに受信したバイト数は、通常、バックアップを実行している Backup-Server で 1 秒あたりに送信されたバイト数よりも大きくなります。
値はネットワーク カードの速度に関連しており、計算を行う必要があります。 その場合は、ネットワーク速度がビット単位で測定され、8 ビット = 1 バイトであることを覚えておいてください。 そのため、1 GB のネットワーク カードがある場合、スループットは 125 MB/秒に達する可能性があります。
Bytes Total/sec カウンターはネットワーク カードの全体的な使用率を理解するのに役立ちますが、他の 2 つのカウンターは、より多くのデータを受信または送信しているかどうかを把握するのに役立ちます。 この情報がある場合は、予想される動作と比較できます。 ネットワークを調査する場合は、ネットワークの動作を完全に理解するために、 both 側からのエンド ツー エンドトレースが必要であるため、別のツールセットが必要です。
まとめ
このシナリオ ガイドは、Windows システムの内訳と物理コンポーネントで終了します。 物理コンポーネントのボトルネックに直面した場合、システムに問題があります。 また、アプリケーションにも影響があります。
このシナリオ ガイドが、パフォーマンス モニターの基本的な理解と、フライト レコーダーなどの "ブラック ボックス" キャプチャ用にシステムを準備する方法を理解するのに役立つことを願っています。 データの分析についてさらにサポートが必要な場合は、サポート チケットを開いてお気軽にお問い合わせください。