この記事は、パフォーマンス モニターの使用に関する問題のトラブルシューティングに役立ちます。
パフォーマンス モニター (パーフモン) とは
Windows の初期からさまざまなイテレーションで使用できるようになった パフォーマンス モニター は、システムの使用状況とさまざまなパフォーマンス メトリックの監視に役立つ Windows の MMC スナップインです。 開くときの既定のビューには、次のようないくつかの異なる領域とリアルタイム メトリックが表示されます。
- パフォーマンス モニター: メトリックのリアルタイム表示
- データ コレクター セット: 指定された時間間隔内に定義されたデータ収集
- レポート: Data コレクター セットで収集されたデータ
データ収集前の質問
問題が発生したら、トラブルシューティングとデータ収集の前に何が起こったかについての詳細情報を確認してください。
- どのような問題がありますか?
- この問題は再現できますか?
- 問題は散発的に発生しますか? その場合、ユーザーはどのようなアクションを実行しましたか?
- パターンは見られますか? その場合、どのようなパターンですか?
- それは一度だけ起こり、再び起こらないのですか?
たとえば、CPU 使用率の高い問題が散発的に発生します。 この問題は、システムの起動から 5 分後、2 時間後に発生することがあります。 パターンは観察されません。 タスク マネージャーやその他の監視ツールを調べるときは、監視ツールの出力に何が発生しているかを確認できません。
このような場合は、システム リソースの概要が必要です。 これは、実行時間の長いパフォーマンス モニターで実現できます。
Note
パフォーマンス モニターはカーネルにアクセスできないため、そのような情報はログに記録されません。 また、パフォーマンス モニターは、CPU 使用率の高い問題に関する他のログ ツールと比較して軽量であり、組み込みのツールです。 パフォーマンス モニターは、ローカルまたはリモートで実行できます。
ローカルでパフォーマンス モニターを実行する
必要に応じてカウンターを追加できます。 管理者特権のコマンド プロンプトを開き、次のコマンドを実行します。
データ コレクター セットを作成します。
Logman.exe create counter CORE_%computername% -f bin -v mmddhhmm -max 2048 -c "\Memory\*" "\Cache\*" "\Objects\*" "\Network Interface(*)\*" "\Paging File(*)\*" "\PhysicalDisk(*)\*" "\LogicalDisk(*)\*" "\Processor(*)\*" "\Processor Information(*)\*" "\Process(*)\*" "\Server\*" "\System\*" "\Server Work Queues(*)\*" "\Terminal Services\*" "\Terminal Services Session(*)\*" -si 00:00:01Note
-max 2048は、ログ ファイルの最大サイズが 2 GB であることを意味します。-si 00:00:01は、間隔が 1 秒1であることを意味します。 この設定は、ニーズに応じて変更できます。データ コレクター セットを開始します。
logman start CORE_%computername%c:\perflogs\Admin に格納されるトレースを停止します。
logman stop CORE_%computername%
リモートでパフォーマンス モニターを実行する
リモート システムを監視するようにパフォーマンス モニターを設定するには、管理者特権のコマンド プロンプトを開き、次のコマンドを実行します。
データ コレクター セットを作成します。
Logman create counter <LOGNAME> -u <DOMAIN\USERNAME> * -f bincirc -v mmddhhmm -max 500 -c "\\<SERVERNAME>\LogicalDisk(*)\*" "\\<SERVERNAME>\Memory\*" "\\<SERVERNAME>\Network Interface(*)\*" "\\<SERVERNAME>\Paging File(*)\*" "\\<SERVERNAME>\PhysicalDisk(*)\*" "\\<SERVERNAME>\Process(*)\*" "\\<SERVERNAME>\Redirector\*" "\\<SERVERNAME>\Server\*" "\\<SERVERNAME>\System\*" "\\<SERVERNAME>\Terminal Services\*" "\\<SERVERNAME>\Processor(*)\*" "\\<SERVERNAME>\Cache\*" -si 00:00:02Note
<DOMAIN\USERNAME>をそれぞれのユーザー資格情報に置き換え、<SERVERNAME>問題のあるサーバーの名前に置き換えます。
次のコマンドを実行して、データ コレクターを起動します。
logman start <LOGNAME>サーバーが応答を停止したら、次のコマンドを実行してデータ コレクターを停止します。
logman stop <LOGNAME>
パフォーマンス モニター ログは、C:\PERFLOGS フォルダーにあります。 次に、 .blg ファイルを zip 圧縮し、問題が発生した後、ワークスペースにアップロードします。
パフォーマンス モニターを 1 日または 2 営業日実行した後、ログを分析して、パターンが存在するかどうかを確認できます。 どのプロセスが CPU をスパイクしますか? また、プロセスは毎日または 1 時間ごとに同じか異なりますか?
結果に基づいて、次の手順に進み、CPU のスパイクの原因の詳細を確認します。 プロセス、スレッド、モジュール、および関数のシーケンスをトレースして、根本原因を特定します。
トラブルシューティングの例
次の例では、TroubleShootingScript (TSS) を使用してデータを収集し、CpuStres を使用して CPU アクティビティをシミュレートします。
TSS の使用
CPU が特定のしきい値に達すると、TSS は CPU 使用率の高いトレースを取得できます。
TSSをダウンロードし、影響を受けるコンピューターの C:\tss フォルダーに展開します。
管理者特権の PowerShell コマンド プロンプトから、 C:\tss フォルダーから次のコマンドレットを実行します。
.\TSS.ps1 -perfmon general -WaitEvent HighCPU:90 -StopWaitTimeInSec 100Note
CPU 使用率の高い問題が発生するまで待ちます。 CPU 使用率が <CpuThreshold>% を超えたら、
StopWaitTimeInSecsettconds (既定値は 60) の間、データを収集し続けます。以下、他にもいくつかの例を紹介します。
-
.\TSS.ps1 -PerfMon General -PerfIntervalSec 5 -WaitEvent HighCPU:90PerfMonは短い間隔でパフォーマンス モニターを表します。 -
.\TSS.ps1 -PerfMonLong SMB -PerfLongIntervalMin 11 -WaitEvent HighCPU:90PerfMonLongは、長い間隔でパフォーマンス モニターを表します。
-
新しい管理者特権の PowerShell コマンド プロンプトから、 C:\tss フォルダーから次のコマンドレットを実行します。
.\TSS.ps1 -StopNote
トレースが 5 分後に停止しない場合は、停止します。
TSS では、パフォーマンス モニターがサポートされます。 .\TSS.ps1 -ListSupportedPerfCounter コマンドレットを実行すると、パフォーマンス カウンターの詳細な名前を確認できます。
コマンドレットを実行して、 General カウンターが設定されたパフォーマンス カウンターのキャプチャを開始します。
.\TSS.ps1 -PerfMon General
パフォーマンス ログの間隔を変更する場合は、 -PerfIntervalSec (単位は秒) または -PerfIntervalMin (単位は分) を使用します。 たとえば、 .\TSS.ps1 -PerfMon General -PerfIntervalSec 1 は 1 秒の間隔を指定します。
.\TSS.ps1 -PerfMon <CounterSetName> コマンドレットのその他の例を次に示します。
一般的なカウンター (CPU、メモリ、ディスクなど) と 5 秒間隔でパフォーマンス モニターを開始します。
.\TSS.ps1 -PerfMon General -PerfIntervalSec 5SMB カウンター (SMB カウンターと一般カウンター) と 11 分間隔でパフォーマンス モニター (
Long) を開始します。.\TSS.ps1 PerfMonLong SMB -PerfLongIntervalMin 11
また、パフォーマンス モニターを使用して、CPU 使用率が一定の量に達したときにトレースを開始することもできますが、複雑で時間がかかります。
CpuStres の使用
CpuStres を使用して、複数のスレッドを実行して CPU 使用率の高いアクティビティをシミュレートできます。 CPU 使用率の高い問題を 6 分間トレースした後、パフォーマンス モニターは次のグラフにギャップを示します。これは問題です。
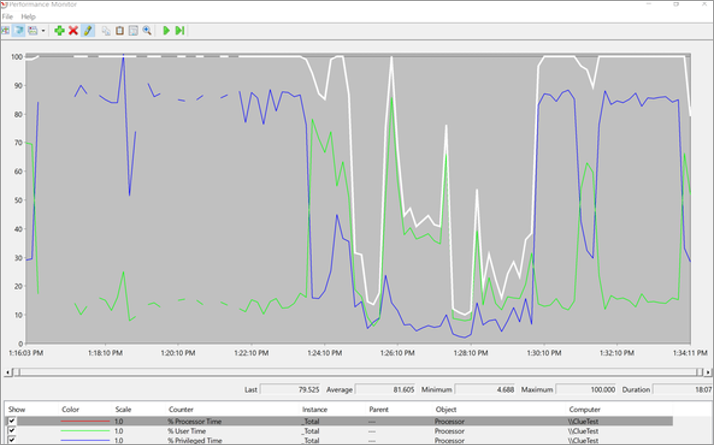
| プロセッサ | 最小 | 最大 | Average |
|---|---|---|---|
| % プロセッサ時間 | 4.688% | 100% | 81.605% |
Processor: %ProcessorTime のカウンターを追加してインスタンスを確認すると、CPUStres64.exeの消費量が最も多いことがわかります。 %Processor Time が 100% を超え、データの約 180% に達し、大幅なスパイクを示す場合があります。
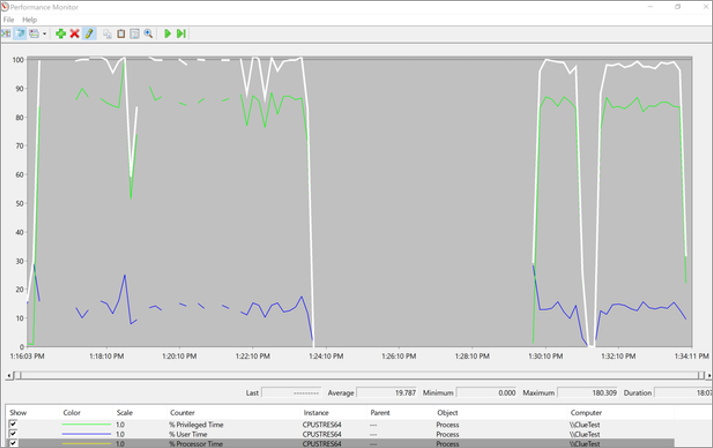
| % プロセッサ時間 | 最小 | 最大 | Average |
|---|---|---|---|
| CPUSTRES64 | 0% | 180.309% | 19.787% |
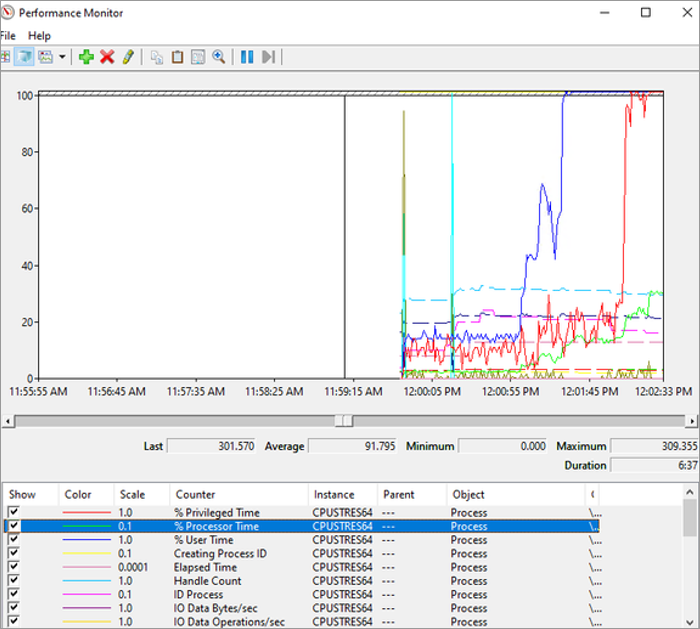
Processor キューの長さを確認します。その平均は 10 >。 これは問題です。 %Processor Time を使用しているユーザーをドリルダウンします。
これは、パフォーマンス モニターの制限事項です。 表示できるデータは非常に多いだけです。
CPU 使用率のパフォーマンス カウンター
CPU 使用率の問題が高い場合は、まずタスク マネージャーで CPU 使用率を確認します。 CPU 使用率が継続的に 85% を超える場合は、システムが CPU ボトルネックに直面していることが示されます。 チェックする必要があるカウンターの一覧を次に示します。
- プロセッサ: % プロセッサ時間
- プロセッサ: ユーザー時間 %
- プロセッサ: % 特権時間
- プロセッサ: 割り込み時間 %
- System: Processor Queue Length
- System: Calls/sec
- System: Context Switches/sec
- Process: Thread Count
- Process: Handle Count
さまざまなパフォーマンスの側面を監視する次のカウンターを確認します。
| コンポーネント | 監視対象のパフォーマンスの側面 | 監視対象カウンター |
|---|---|---|
| プロセッサ | 使用方法 | プロセッサ: % プロセッサ時間 (すべてのインスタンス) プロセッサ: DPC 時間 % プロセッサ: 割り込み時間 % プロセッサ: % 特権時間 プロセッサ: ユーザー時間 % |
| プロセッサ | ボトルネック | プロセッサ: % プロセッサ時間 (すべてのインスタンス) プロセッサ: DPC 時間 % プロセッサ: 割り込み時間 % プロセッサ: % 特権時間 プロセッサ: ユーザー時間 % Processor: Interrupts/sec プロセッサ: DPCs Queued/sec System: Context switches/sec System: System Calls/sec System: Processor Queue Length (すべてのインスタンス) |
| カウンター名 | メトリック |
|---|---|
| プロセッサ キューの長さ (PQL) | プロセッサごとに 2 つ以上のインスタンスがあり、CPU 使用率が高い場合は、CPU 使用率が高いプロセスを確認します。 また、 Context スイッチ、 % DPC 時間、割り込み時間の % を確認。 |
| % プロセッサ時間 | 0 から 50%: 正常です。 50 から 80%: モニター/警告モニター。 80 から 100%: クリティカル。 システムの動作が遅くなる可能性があります。 |
| % DPC 時間 | % Processor Time> 85% と % DPC Time> 15%: これらのレベルを常に上回っているかどうかを調べます。 短いスパイクでも問題ありません。 たとえば、100% % プロセッサ時間 50% % DPC 時間を超える 1 つのプロセッサでのみ。 |
| % 割り込み時間 | CPU 割り込み時間が長い: 割り込み時間が 30% を超えています。 プロセッサの % 割り込み時間が長い は、ハードウェアまたはドライバーの問題を示している可能性があります。 非常に高い CPU 割り込み時間: 50% を超える割り込み時間。 プロセッサの非常に高い % 割り込み時間 は、ハードウェアまたはドライバーの問題を示している可能性があります。 |
関連情報
サード パーティの情報とソリューションの免責事項
このドキュメントの情報と解決策は、公開日時点でのこれらの問題に関する Microsoft Corporation の現在のビューを表しています。 このソリューションは、Microsoft またはサード パーティのプロバイダーから入手できます。 Microsoft では、この記事で説明する可能性のあるサード パーティのプロバイダーまたはサード パーティのソリューションを特に推奨していません。 また、この記事では説明していない他のサードパーティプロバイダーやサードパーティのソリューションもあります。 Microsoft は変化する市場の状況に対応する必要があるため、この情報は Microsoft によるコミットメントであると解釈しないでください。 Microsoft は、Microsoft または前述のサード パーティ プロバイダーによって提示された情報またはソリューションの正確性を保証または保証することはできません。
Microsoft は、明示的、黙示的、または法的に関係なく、一切の保証を行わず、すべての表明、保証、条件を除外します。 これらの条件には、サービス、ソリューション、製品、またはその他の素材または情報に関する、タイトルの表明、保証、または条件、非侵害、満足できる条件、商品性、および特定の目的への適合性が含まれますが、これらに限定されません。 いかなる場合も、Microsoft は、この記事で言及されているサードパーティソリューションについて責任を負いません。