この記事の情報を使用して、記憶域スペース ダイレクト展開をトラブルシューティングします。
一般に、次の手順から開始します。
- Windows Server カタログを使用して、SSD の製造元とモデルが Windows Server 2016 および Windows Server 2019 の認定を受けていることを確認します。 ドライブが記憶域スペース ダイレクトに対応しているかをベンダーに確認します。
- ストレージに障害のあるドライブがないかを検査します。 ストレージ管理ソフトウェアを使用して、ドライブの状態を確認します。 ドライブに問題がある場合は、ベンダーと一緒に作業してください。
- 必要に応じて、ストレージとドライブのファームウェアを更新します。 すべてのノードに最新 Windows 更新プログラムがインストールされていることを確認します。 Windows Server 2016 の最新の更新プログラムは、Windows 10 および Windows Server 2016 の更新履歴から入手できます。 Windows Server 2019 の最新の更新プログラムを、Windows 10 および Windows Server 2019 の更新履歴から入手します。
- ネットワーク アダプターのドライバーとファームウェアを更新します。
- クラスター検証を実行し、[Storage Space Direct]\(記憶域スペース ダイレクト\) セクションを確認します。 キャッシュに使用するドライブが正しく報告され、エラーがないことを確認します。
それでも問題が解決しない場合は、この記事の特定の問題ごとのトラブルシューティング情報を確認してください。
仮想ディスク リソースが冗長性なしの状態である
記憶域スペース ダイレクト システムのノードが、クラッシュや電源障害により予期せず再起動します。 その後、1 つ以上の仮想ディスクがオンラインにならないことがあり、"冗長情報不足" という記述が表示されます。
| フレンドリーネーム | レジリエンシー設定名 | OperationalStatus | 健康状態 | IsManualアタッチ | サイズ | PSComputerName (英語) |
|---|---|---|---|---|---|---|
| ディスク 4 | ミラー | [OK] | 元気 | 正しい | 10テラバイト | ノード-01.conto... |
| ディスク 3 | ミラー | [OK] | 元気 | 正しい | 10テラバイト | Node-01.contoso です。 |
| ディスク 2 | ミラー | 冗長性なし | 異常 | 正しい | 10テラバイト | Node-01.contoso です。 |
| ディスク1 | ミラー | {冗長性なし、運用中} | 異常 | 正しい | 10テラバイト | Node-01.contoso です。 |
また、仮想ディスクのオンライン化を試みた後、クラスター ログ DiskRecoveryAction に次の情報が記録されます。
[Verbose] 00002904.00001040::YYYY/MM/DD-12:03:44.891 INFO [RES] Physical Disk <DiskName>: OnlineThread: SuGetSpace returned 0.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 WARN [RES] Physical Disk < DiskName>: Underlying virtual disk is in 'no redundancy' state; its volume(s) may fail to mount.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 ERR [RES] Physical Disk <DiskName>: Failing online due to virtual disk in 'no redundancy' state. If you would like to attempt to online the disk anyway, first set this resource's private property 'DiskRecoveryAction' to 1. We will try to bring the disk online for recovery, but even if successful, its volume(s) or CSV may be unavailable.
"冗長性なしの動作状態" は、ディスクに障害が発生した場合や、システムが仮想ディスク上のデータにアクセスできない場合に発生します。 この問題は、ノードのメンテナンス中にノードで再起動が発生した場合に発生する可能性があります。
この問題を解決するには、次の手順に従ってください。
影響を受ける仮想ディスクを CSV から削除します。 これにより、クラスターの使用可能な記憶域グループに格納され、ResourceType が
Physical Diskとして表示されるようになります。Remove-ClusterSharedVolume -Name "CSV Name"使用可能な記憶域グループを所有するノードで、冗長性なしの状態のすべてのディスクで次のコマンドを実行します。 使用可能な記憶域グループがオンになっているノードを特定するには、次のコマンドを実行します。
Get-ClusterGroupディスクの回復アクションを設定し、ディスクを起動します。
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 1 Start-ClusterResource -Name "Physical Disk Resource Name"修復は自動的に開始されます。 修復が完了するまで待ちます。 中断状態に入り、再び開始される可能性があります。 進行状況を監視するには、次に従ってください。
-
Get-StorageJobを実行して修復の状態を監視し、いつ完了するかを確認します。 -
Get-VirtualDiskを実行して、Space が Healthy という HealthStatus を返すことを確認します。
-
修復が完了し、仮想ディスクが正常な状態になったら、仮想ディスクのパラメーターを元に戻します。
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 0DiskRecoveryActionを有効にするには、ディスクをオフラインにしてからオンラインに戻します。Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"影響を受ける仮想ディスクを CSV に追加し直します。
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"
DiskRecoveryAction は、チェックを行わずに読み取り/書き込みモードで Space ボリュームをアタッチできるオーバーライド スイッチです。 このプロパティを使用すると、ボリュームがオンラインにならない理由を診断できます。 メンテナンス モードと似ていますが、障害状態のリソース上で呼び出すことができます。 また、データにアクセスして、コピーすることもできます。 このアクセスは、冗長性のない状況で役立ちます。
DiskRecoveryAction プロパティは、2018 年 2 月 22 日の更新プログラム KB 4077525 で追加されました。
クラスターでの Detached 状態
Get-VirtualDisk コマンドレットを実行すると、1 つ以上の記憶域スペース ダイレクト仮想ディスクの OperationalStatus が Detached になります。 しかし、Get-PhysicalDisk コマンドレットによって報告された HealthStatus は、すべての物理ディスクが Healthy 状態であることを示します。
この例では、Get-VirtualDisk コマンドレットからの出力を示します。
| フレンドリーネーム | レジリエンシー設定名 | OperationalStatus | 健康状態 | IsManualアタッチ | サイズ | PSComputerName (英語) |
|---|---|---|---|---|---|---|
| ディスク 4 | ミラー | [OK] | 元気 | 正しい | 10テラバイト | Node-01.contoso です。 |
| ディスク 3 | ミラー | [OK] | 元気 | 正しい | 10テラバイト | Node-01.contoso です。 |
| ディスク 2 | ミラー | デタッチ | 未知 | 正しい | 10テラバイト | Node-01.contoso です。 |
| ディスク1 | ミラー | デタッチ | 未知 | 正しい | 10テラバイト | Node-01.contoso です。 |
また、次のイベントがノードのログに記録される場合があります。
Log Name: Microsoft-Windows-StorageSpaces-Driver/Operational
Source: Microsoft-Windows-StorageSpaces-Driver
Event ID: 311
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: Virtual disk {GUID} requires a data integrity scan.
Data on the disk is out-of-sync and a data integrity scan is required.
To start the scan, run this command:
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask
Once you have resolved that condition, you can online the disk by using these commands in PowerShell:
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsReadOnly $false
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsOffline $false
------------------------------------------------------------
Log Name: System
Source: Microsoft-Windows-ReFS
Event ID: 134
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: The file system was unable to write metadata to the media backing volume <VolumeId>. A write failed with status "A device which does not exist was specified." ReFS will take the volume offline. It might be mounted again automatically.
------------------------------------------------------------
Log Name: Microsoft-Windows-ReFS/Operational
Source: Microsoft-Windows-ReFS
Event ID: 5
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: ReFS failed to mount the volume.
Context: 0xffffbb89f53f4180
Error: A device which does not exist was specified.
Volume GUID:{00000000-0000-0000-0000-000000000000}
DeviceName:
Volume Name:
Detached Operational Status は、ダーティ リージョン追跡 (DRT) ログがいっぱいの場合に発生します。 記憶域スペースでは、ミラー化されたスペースにダーティ リージョン追跡 (DRT) を使用して、電源障害が発生した場合に、メタデータに対して実行中の更新がログに記録されるようにします。 ログに記録された更新により、記憶域スペースが操作をやり直したり元に戻したりできるようになります。 電源が復旧して、システムが復帰した後、記憶域スペースは柔軟で一貫性のある状態に戻ります。 DRT ログがいっぱいになった場合、DRT メタデータが同期されてフラッシュされるまで、仮想ディスクをオンラインにすることはできません。 このプロセスではフルスキャンを実行する必要がありますが、完了するまでに数時間かかることがあります。
この問題を解決するには、次の手順に従ってください。
影響を受ける仮想ディスクを CSV から削除します。
Remove-ClusterSharedVolume -Name "CSV Name"オンラインにならないすべてのディスクに対して、以下のコマンドを実行します。
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 7 Start-ClusterResource -Name "Physical Disk Resource Name"デタッチされたボリュームがオンラインになっているすべてのノードで、次のコマンドを実行します。
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTaskデタッチされたボリュームがオンラインになっているすべてのノードで、このタスクを開始します。 修復は自動的に開始されます。 修復が完了するまで待ちます。 中断状態に入り、再び開始される可能性があります。 進行状況を監視するには、次に従ってください。
-
Get-StorageJobを実行して修復の状態を監視し、いつ完了するかを確認します。 -
Get-VirtualDiskを実行して、Space が Healthy という HealthStatus を返すことを確認します。クラッシュ回復機能用のデータ整合性スキャンは、記憶域ジョブとして表示されないタスクであり、進行状況インジケーターはありません。 タスクが実行中であると表示されている場合は、実行されています。 完了すると、完了と表示されます。
また、次のコマンドレットを使用すると、実行中のスケジュール タスクの状態を表示できます。
Get-ScheduledTask | ? State -eq running
-
クラッシュ回復機能用のデータ整合性スキャンが完了すると、修復が完了し、仮想ディスクが正常な状態になります。 仮想ディスクのパラメーターを元に戻します。
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 0DiskRecoveryActionを有効にするには、ディスクをオフラインにしてからオンラインに戻します。Stop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"影響を受ける仮想ディスクを CSV に追加し直します。
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"DiskRunChkdsk value 7を使用して Space ボリュームをアタッチし、パーティションを読み取り専用モードに設定します。 このアクションを実行すると、修復をトリガーすることによって、Space を自己検出し、自己回復することができます。 修復は、マウントされると自動的に実行されます。 また、データにアクセスして、コピーすることもできます。 完全な DRT ログなどの一部のエラー状態では、クラッシュ回復機能用のデータ整合性スキャン スケジュール タスクを実行する必要があります。
クラッシュ回復機能用のデータ整合性スキャンを使用して、完全なダーティ領域追跡 (DRT) ログを同期およびクリアします。 このタスクの完了には数時間かかることがあります。 クラッシュ回復機能用のデータ整合性スキャンは、記憶域ジョブとして表示されないタスクであり、進行状況インジケーターはありません。 タスクが実行中であると表示されている場合は、実行されています。 完了すると、完了と表示されます。 このタスクの実行中にタスクをキャンセルするか、ノードを再起動した場合、タスクは最初からやり直す必要があります。
詳細については、記憶域スペース ダイレクトの正常性と動作状態のトラブルシューティングに関する記事を参照してください。
STATUS_IO_TIMEOUT c00000b5 のイベント 5120
重要
Windows Server 2016 用: 修正を含む更新プログラムを適用するときにこれらの現象が発生する可能性を低減するには、現在、ノードに 2018 年 5 月 8 日から 2018 年 10 月 9 日までにリリースされた Windows Server 2016 の累積更新プログラムがインストールされている場合、以下の記憶域メンテナンス モード手順を使用して、2018 年 10 月 18 日の Windows Server 2016 の累積更新プログラムまたはそれ以降のバージョンをインストールすることをお勧めします。
2018 年 5 月 8 日 (KB 4103723) から 2018 年 10 月 9 日 (KB 4462917) までにリリースされた累積更新プログラムがインストールされた Windows Server 2016 でノードを再起動すると、STATUS_IO_TIMEOUT c00000b5 のイベント 5120 が発生する可能性があります。
ノードを再起動すると、イベント 5120 がシステム イベント ログに記録され、以下のいずれかのエラー コードが表示されます。
Event Source: Microsoft-Windows-FailoverClustering
Event ID: 5120
Description: Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_IO_TIMEOUT(c00000b5)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_CONNECTION_DISCONNECTED(c000020c)'. All I/O will temporarily be queued until a path to the volume is reestablished.
イベント 5120 がログに記録されると、デバッグ情報を収集するためにライブ ダンプが生成されます。これにより、ほかの現象が発生したり、パフォーマンスに影響を及ぼしたりする可能性があります。 ライブ ダンプが生成されると、短時間の一時停止が発生します。 この一時停止により、メモリのスナップショットがダンプ ファイルに書き込まれます。 大量のメモリを搭載し、負荷がかかっているシステムでは、ノードがクラスター メンバーシップから削除され、次のイベント 1135 がログに記録される可能性があります。
Event source: Microsoft-Windows-FailoverClustering
Event ID: 1135
Description: Cluster node 'NODENAME'was removed from the active failover cluster membership. The Cluster service on this node might have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
2018 年 5 月 8 日に Windows Server 2016 に導入された変更は、記憶域スペース ダイレクトのクラスター内 SMB ネットワーク セッションに SMB Resilient Handles を追加する累積更新プログラムでした。 この更新は、一時的なネットワーク障害に対する回復性を向上させ、RoCE がネットワークの輻輳を処理する方法を改善するために行われました。 また、これらの改善により、SMB 接続の再接続時のタイムアウトや、ノード再起動時のタイムアウト待ちが不用意に増加しました。 これらの問題は、負荷がかかっているシステムに影響を及ぼす可能性があります。 計画外のダウンタイムが発生すると、接続がタイムアウトするのを待つ間、最大 60 秒の IO 一時停止も確認されています。この問題を解決するには、2018 年 10 月 18 日の Windows Server 2016 の累積更新プログラム、またはそれ以降のバージョンをインストールしてください。
注意
この更新プログラムは、この問題を解決するために、CSV のタイムアウトを SMB 接続のタイム アウトに合わせて調整します。 「回避策」セクションで説明したライブ ダンプ生成を無効にする変更は実装されません。
シャットダウン プロセス フロー
Get-VirtualDisk コマンドレットを実行し、HealthStatus の値が Healthy であることを確認します。
次のコマンドレットを実行して、ノードをドレインします。
Suspend-ClusterNode -Drain次のコマンドレットを実行して、そのノードのディスクを記憶域メンテナンス モードにします。
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Enable-StorageMaintenanceModeGet-PhysicalDiskコマンドレットを実行し、OperationalStatus値がIn Maintenanceモードであることを確認します。Restart-Computerコマンドレットを実行してノードを再起動します。ノードが再起動したら、次のコマンドレットを実行して、そのノードのディスクで記憶域メンテナンス モードを解除します。
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Disable-StorageMaintenanceMode次のコマンドレットを実行して、ノードを再開します。
Resume-ClusterNode次のコマンドレットを実行して、再同期ジョブの状態を確認します。
Get-StorageJob
ライブ ダンプの無効化
大量のメモリを搭載し、負荷がかかっているシステムでライブ ダンプ生成の影響を軽減するために、ライブ ダンプ生成を無効にできます。 次の 3 つのオプションがあります。
注意
この手順を実行すると、この問題の調査に必要な Microsoft サポート診断情報が収集されなくなる可能性があります。 サポート エージェントが、特定のトラブルシューティング シナリオに基づいて、ライブ ダンプ生成を再度有効にするように要求することがあります。
すべてのライブ ダンプを無効にする
ライブ ダンプ システム全体を含め、すべてのダンプを完全に無効にするには、次の手順を実行します。 このシナリオでは、次の手順を使用します。
- 次のレジストリキーを作成します: HKLM\System\CurrentControlSet\Control\CrashControl\ForceDumpsDisabled
- 新しい ForceDumpsDisabled キーの下に、"GuardedHost" として REG_DWORD プロパティを作成し、その値を 0x10000000 に設定します。
- 各クラスター ノードに新しいレジストリ キーを適用します。
注意
レジストリの変更を有効にするには、コンピューターを再起動する必要があります。
このレジストリ キーが設定されると、ライブ ダンプの作成は失敗し、STATUS_NOT_SUPPORTED エラーが生成されます。
1 つのライブ ダンプのみを許可する
既定では、Windows エラー報告は、レポートの種類ごとに 7 日につき 1 つのライブ ダンプのみ、コンピューターあたりのライブ ダンプは 5 日につき 1 つのみを許可します。 次のレジストリ キーを設定することで、コンピューター上で永久に 1 つの LiveDump しか許可しないように変更することができます。
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v SystemThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v ComponentThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
注意
変更を有効にするには、コンピューターを再起動する必要があります。
クラスター生成を無効にする
ライブ ダンプのクラスター生成を無効にするには (イベント 5120 がログに記録されたときなど)、次のコマンドレットを実行します。
(Get-Cluster).DumpPolicy = ((Get-Cluster).DumpPolicy -Band 0xFFFFFFFFFFFFFFFE)
このコマンドレットは、コンピューターを再起動しなくても、すべてのクラスター ノードに直ちに影響します。
IO パフォーマンスの低下
IO パフォーマンスの低下が見られる場合は、記憶域スペース ダイレクト構成でキャッシュが有効になっているかを確認します。
確認には次の 2 つの方法があります。
クラスター ログを使用します。 任意のテキスト エディターでクラスター ログを開き、"[=== SBL Disks ===]" を検索します。 ログが生成されたノード上のディスクの一覧が表示されます。
キャッシュ対応ディスクの例: ここでは、状態が
CacheDiskStateInitializedAndBoundであり、GUID が示されることがわかります。[=== SBL Disks ===] {26e2e40f-a243-1196-49e3-8522f987df76},3,false,true,1,48,{1ff348f1-d10d-7a1a-d781-4734f4440481},CacheDiskStateInitializedAndBound,1,8087,54,false,false,HGST,HUH721010AL4200,7PG3N2ER,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],キャッシュ非対応: ここでは、GUID が示されておらず、状態が
CacheDiskStateNonHybridであることがわかります。[=== SBL Disks ===] {426f7f04-e975-fc9d-28fd-72a32f811b7d},12,false,true,1,24,{00000000-0000-0000-0000-000000000000},CacheDiskStateNonHybrid,0,0,0,false,false,HGST,HUH721010AL4200,7PGXXG6C,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],キャッシュ非対応: すべてのディスクが同じ種類である場合、既定でケースは有効になっていません。 ここでは、GUID が示されておらず、状態が
CacheDiskStateIneligibleDataPartitionであることがわかります。{d543f90c-798b-d2fe-7f0a-cb226c77eeed},10,false,false,1,20,{00000000-0000-0000-0000-000000000000},CacheDiskStateIneligibleDataPartition,0,0,0,false,false,NVMe,INTEL SSDPE7KX02,PHLF7330004V2P0LGN,0170,{79b4d631-976f-4c94-a783-df950389fd38},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],SDDCDiagnosticInfo から Get-PhysicalDisk.xml を使用します。
- "$d = Import-Clixml GetPhysicalDisk.XML" を使用して XML ファイルを開きます。
-
ipmo storageを実行します。 -
$dを実行します。 Usage が Journal ではなく Auto-Select であることがわかります。
次のような出力が表示されるはずです。
フレンドリーネーム シリアルナンバー メディアタイプ キャンプール OperationalStatus 健康状態 使用 サイズ NVMe INTELのSSDPE7KX02 PHLF733000372P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの NVMe INTELのSSDPE7KX02 PHLF7504008J2P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの NVMe INTELのSSDPE7KX02 PHLF7504005F2P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの NVMe INTELのSSDPE7KX02 PHLF7504002A2P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの NVMe INTELのSSDPE7KX02 PHLF7504004T2P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの NVMe INTELのSSDPE7KX02 PHLF7504002E2P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの NVMe INTELのSSDPE7KX02 PHLF7330002Z2P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの NVMe INTELのSSDPE7KX02 PHLF733000272P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの NVMe INTELのSSDPE7KX02 PHLF7330001J2P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの NVMe INTELのSSDPE7KX02 PHLF733000302P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの NVMe INTELのSSDPE7KX02 PHLF7330004D2P0LGN ソリッドステートドライブ (SSD) いいえ [OK] 元気 自動選択 1.82 TBの
同じディスクを再度使用できるよう、既存のクラスターを破棄する方法
記憶域スペース ダイレクト クラスターで、記憶域スペース ダイレクトを無効にし、「ドライブをクリーンアップする」で説明されているクリーンアップ プロセスを使用します。 クラスター化された記憶域プールは引き続きオフライン状態のままであり、ヘルス サービスはクラスターから削除されます。
次の手順では、ファントム記憶域プールを削除します。
Get-ClusterResource -Name "Cluster Pool 1" | Remove-ClusterResource
これで、任意のノードで Get-PhysicalDisk を実行すると、プール内のすべてのディスクが表示されます。 たとえば、4 つの SAS ディスクを含む 4 ノード クラスターを含むラボでは、各ノードにそれぞれ 100 GB が表示されます。 その場合、記憶域スペース ダイレクトを無効にして SBL (記憶域バス層) を削除し、フィルターを残した状態で Get-PhysicalDisk を実行すると、ローカル OS ディスクを除く 4 つのディスクが報告されます。 代わりに、16 が報告されました。 この動作は、クラスター内のすべてのノードで同じです。 Get-Disk コマンドを実行すると、次のサンプル出力に示されている 0、1、2 などの番号が付けられたローカルに接続されたディスクが表示されます。
| 数値 | フレンドリ名 | シリアル番号 | 健康状態 | OperationalStatus | 総サイズ | パーティションの形式 |
|---|---|---|---|---|---|---|
| 0 | MSFTバーチャル | 元気 | オンライン | 127ギガバイト | GPT | |
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| 1 | MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | |
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| 2 | MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | |
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| 4 | MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | |
| 3 | MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | |
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 | ||
| MSFTバーチャル | 元気 | オフライン | 100 GB | 未加工 |
Enable-ClusterS2D を使用して記憶域スペース ダイレクト クラスターを作成すると表示される「サポートされていないメディアの種類」というエラーメッセージについて
Enable-ClusterS2D コマンドレットを実行すると、次のようなエラーが表示される場合があります。
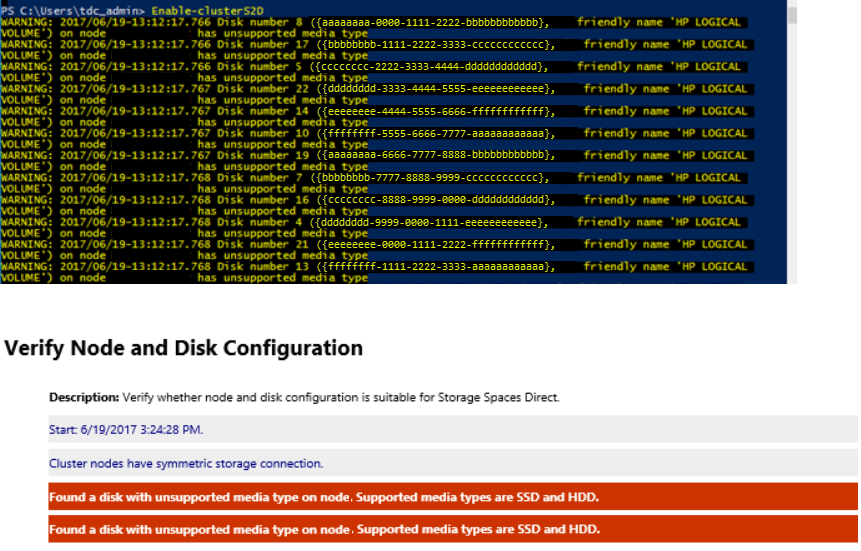
この問題を解決するには、HBA アダプターが HBA モードで構成されていることを確認します。 RAID モードで HBA を構成する必要はありません。
Enable-ClusterStorageSpacesDirect が「SBL ディスクを浮上させるまで待機中」または 27% でハングする
検証レポートに次の情報が表示されます。
ノード <identifier> に接続されているディスク <nodename> が SCSI ポートの関連付けを返し、対応するエンクロージャ デバイスが見つかりませんでした。 ハードウェアは記憶域スペース ダイレクト (S2D) と互換性がありません。 SCSI エンクロージャ サービス (SES) のサポートを確認するには、ハードウェア ベンダーに問い合わせてください。
問題は、ディスクと HBA カードの間にある HPE SAS エキスパンダー カードにあります。 SAS エキスパンダーは、エキスパンダーに接続された最初のドライブとエキスパンダー自身の間に重複した ID を作成します。 この問題は、HPE Smart アレイ コントローラーの SAS エキスパンダー ファームウェア: 4.02 で解決されました。
Intel SSD DC P4600 シリーズに一意ではない NGUID がある
次の例では、Intel SSD DC P4600 シリーズ デバイスで、0100000001000000E4D25C000014E214 や 0100000001000000E4D25C0000EEE214 などの複数の名前空間に対して同様の 16 バイト NGUID が報告されているような問題が発生する可能性があります。
| ユニークID | デバイスID | メディアタイプ | バスの種類 | シリアルナンバー | サイズ | キャンプール | フレンドリーネーム | OperationalStatus |
|---|---|---|---|---|---|---|---|---|
| 5000CCA251D12E30 | 0 | HDD(ハードディスクドライブ) | SASの | 7PKR197G | 10000831348736 | いいえ | HGSTの | HUH721010AL4200 |
| eui.0100000000100000E4D25C000014E214 | 4 | ソリッドステートドライブ (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214。 | 1600321314816 | 正しい | インテル | SSDPE2KE016T7 |
| eui.0100000000100000E4D25C000014E214 | 5 | ソリッドステートドライブ (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214。 | 1600321314816 | 正しい | インテル | SSDPE2KE016T7 |
| eui.0100000000100000E4D25C0000EEE214 | 6 | ソリッドステートドライブ (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214。 | 1600321314816 | 正しい | インテル | SSDPE2KE016T7 |
| eui.0100000000100000E4D25C0000EEE214 | 7 | ソリッドステートドライブ (SSD) | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214。 | 1600321314816 | 正しい | インテル | SSDPE2KE016T7 |
この問題を解決するには、Intel ドライブのファームウェアを最新バージョンに更新します。 2018 年 5 月のファームウェア バージョン QDV101B1 では、この問題を解決できることが確認されています。
2018 年 5 月リリースの Intel SSD データ センター ツールには、Intel SSD DC P4600シリーズ用のファームウェア更新プログラム、QDV101B1 が含まれています。
物理ディスクの HealthStatus と OperationalStatus
Windows Server 2016 記憶域スペース ダイレクト クラスターでは、1 つ以上の物理ディスクの HealthStatus が Healthy と表示されるのに対し、OperationalStatus は "プールから削除しています、OK" と表示される場合があります。
"プールから削除しています" 状態は Remove-PhysicalDisk が呼び出されたときに設定されるインテントですが、状態を維持し、削除操作に失敗した場合に回復できるように Health に格納されています。 以下のいずれかの方法を使用して、OperationalStatus を Healthy に手動で変更できます。
- プールから物理ディスクを削除し、追加し戻します。
- Import-Module Clear-PhysicalDiskHealthData.ps1 を実行します。
- Clear-PhysicalDiskHealthData.ps1 スクリプトを実行し、インテントをクリアします。 このスクリプトは .txt ファイルとしてダウンロード可能です。 実行する前に ps1 ファイルとして保存する必要があります。
スクリプトを実行する方法の例を次に示します。
SerialNumberパラメーターを使用して、Healthy に設定する必要があるディスクを指定します。 シリアル番号は、WMI MSFT_PhysicalDiskまたはGet-PhysicalDiskから取得できます。 この例では、ゼロを使用してシリアル番号を表します。Clear-PhysicalDiskHealthData -Intent -Policy -SerialNumber 000000000000000 -Verbose -ForceUniqueIdパラメーターを使用して、もう一度WMI MSFT_PhysicalDiskまたはGet-PhysicalDiskからディスクを指定します。Clear-PhysicalDiskHealthData -Intent -Policy -UniqueId 00000000000000000 -Verbose -Force
ファイルのコピーが遅い
エクスプローラーを使用して大容量の VHD を仮想ディスクにコピーする際に、ファイルのコピーに予想以上に時間がかかる場合があります。
エクスプローラー、Robocopy、または Xcopy を使用して大容量の VHD を仮想ディスクにコピーすることはお勧めしません。 結果として、予想よりもパフォーマンスが低下します。 コピー処理は、ストレージ スタックの下位に位置する記憶域スペース ダイレクト スタックを経由せず、ローカル コピー処理のように動作します。
記憶域スペース ダイレクトのパフォーマンスをテストする場合は、VMFleet と Diskspd を使用して、サーバーを読み込んでストレス テストを行い、基本ラインを取得し、記憶域スペース ダイレクトのパフォーマンスに対する期待値を設定することをお勧めします。
ノードの再起動中に残りのノードに表示されることが予想されるイベント
次のイベントは無視しても問題はありません。
Event ID 205: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Event ID 203: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Azure VM を実行している場合は、このイベントを無視できます。イベント ID 32: ドライバーは、デバイス \Device\Harddisk5\DR5 の書き込みキャッシュが有効になっていることを検出しました。データの破損が発生する可能性があります。
Intel P3x00 NVMe デバイスを使用した展開におけるパフォーマンスの低下または「通信の切断」、「IO エラー」、「デタッチ」、「冗長性なし」エラー
Intel P3x00 ファミリの NVM Express (NVMe) デバイスに基づいたハードウェアを "メンテナンス リリース 8" より前のファームウェア バージョンで使用している一部の記憶域スペース ダイレクト ユーザーに影響を与える重大な問題が確認されました。
注意
個々の OEM は、固有のファームウェア バージョン文字列を持つ Intel P3x00 ファミリの NVMe デバイスに基づくデバイスを持つ場合があります。 ファームウェアの最新バージョンの詳細については、OEM にお問い合わせください。
NVMe デバイスの Intel P3x00 ファミリに基づいて展開でハードウェアを使用している場合は、使用可能な最新のファームウェア (メンテナンス リリース 8 以上) をすぐに適用することをお勧めします。