ローランク適応 (LoRA) を使用して Phi シリカ モデル を微調整し、特定のユース ケースのパフォーマンスを向上させることができます。 LoRA を使用して Phi Silica (Microsoft Windows のローカル言語モデル) を最適化することで、より正確な結果を得ることができます。 このプロセスでは、LoRA アダプターをトレーニングし、推論中に適用してモデルの精度を向上させます。
[前提条件]
- Phi シリカの応答を高めるためのユース ケースを特定しました。
- 評価基準を選択して、"適切な応答" を決定しました。
- Phi Silica API を試しましたが、評価基準を満たしていません。
アダプターをトレーニングする
Windows 11 で Phi Silica モデルを微調整するために LoRA アダプターをトレーニングするには、まずトレーニング プロセスで使用するデータセットを生成する必要があります。
LoRA アダプターで使用するデータセットを生成する
データセットを生成するには、データを 2 つのファイルに分割する必要があります。
train.json– アダプターのトレーニングに使用されます。test.json– トレーニング中およびトレーニング後にアダプターのパフォーマンスを評価するために使用されます。
どちらのファイルも JSON 形式を使用する必要があります。各行は 1 つのサンプルを表す個別の JSON オブジェクトです。 各サンプルには、ユーザーとアシスタントの間で交換されるメッセージの一覧が含まれている必要があります。
すべてのメッセージ オブジェクトには、次の 2 つのフィールドが必要です。
content: メッセージのテキスト。role: 送信者を示す"user"または"assistant"。
次の例を参照してください。
{"messages": [{"content": "Hello, how do I reset my password?", "role": "user"}, {"content": "To reset your password, go to the settings page and click 'Reset Password'.", "role": "assistant"}]}
{"messages": [{"content": "Can you help me find nearby restaurants?", "role": "user"}, {"content": "Sure! Here are some restaurants near your location: ...", "role": "assistant"}]}
{"messages": [{"content": "What is the weather like today?", "role": "user"}, {"content": "Today's forecast is sunny with a high of 25°C.", "role": "assistant"}]}
トレーニングのヒント:
各サンプル 行の末尾にコンマは必要ありません。
できるだけ多くの高品質で多様な例を含めます。 最適な結果を得るには、
train.jsonファイルに少なくとも数千のトレーニング サンプルを収集します。test.jsonファイルは小さくできますが、モデルで処理する必要がある相互作用の種類をカバーする必要があります。1 行に 1 つの JSON オブジェクトを含む
train.jsonファイルとtest.jsonファイルを作成します。それぞれに、ユーザーとアシスタントの間の簡単な会話が含まれています。 データの品質と量は、LoRA アダプターの有効性に大きく影響します。
AI ツールキットでの LoRA アダプターのトレーニング
AI Toolkit for Visual Studio Code を使用して LoRA アダプターをトレーニングするには、まず次の必須前提条件が必要です。
Azure サブスクリプションで、Azure Container Apps 用の使用可能なクォータを持っています。
- A100 GPU 以上を使用して、微調整ジョブを効率的に実行することをお勧めします。
- Azure Portal で使用可能なクォータがあることを確認します。 クォータの検索に関するヘルプが必要な場合は、「 クォータの表示」を参照してください。
Visual Studio Code をまだインストールしていない場合は、インストールする必要があります。
AI Toolkit for Visual Studio Code をインストールするには:
AI Toolkit 拡張機能がダウンロードされると、Visual Studio Code 内の左側のツール バー ウィンドウからアクセスできるようになります。
[ツール>微調整] に移動します。
プロジェクト名とプロジェクトの場所を入力します。
モデル カタログから "microsoft/phi-silica" を選択します。
[プロジェクトの構成] を選択します。
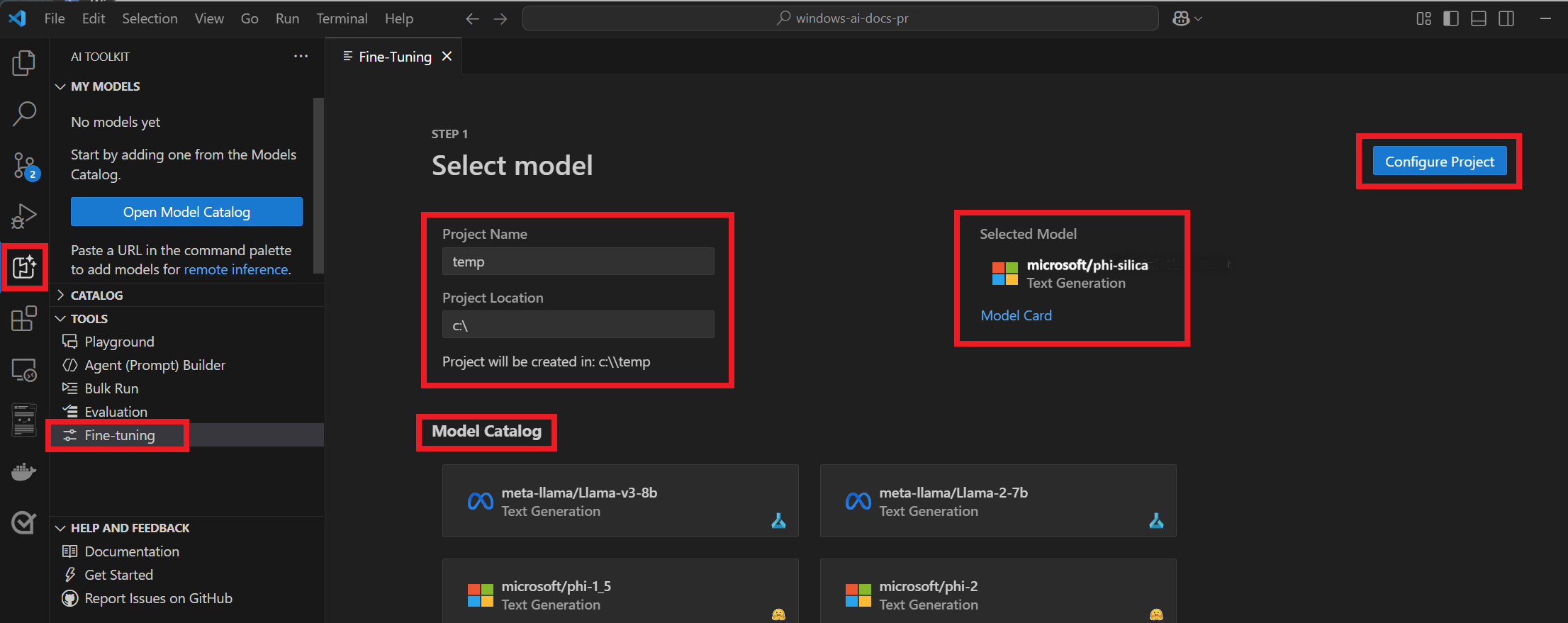
Phi Silica の最新バージョンを選択します。
[ データ>トレーニング データセット名 と テスト データセット名] で、
train.jsonファイルとtest.jsonファイルを選択します。[プロジェクトの生成] を選択します。新しい VS Code ウィンドウが開きます。
Azure ジョブが正しくデプロイおよび実行されるように、bicep ファイルで適切なワークロード プロファイルが選択されていることを確認します。
workloadProfilesの下に次のコードを追加します。{ workloadProfileType: 'Consumption-GPU-NC24-A100' name: 'GPU' }[新しい微調整ジョブ] を選択し、ジョブの名前を入力します。
Azure サブスクリプションにアクセスする Microsoft アカウントを選択するように求めるダイアログ ボックスが表示されます。
アカウントを選択したら、サブスクリプションのドロップダウン メニューからリソース グループを選択する必要があります。
これで、微調整ジョブが正常に開始され、ジョブの状態が表示されます。 ジョブが完了すると、[ダウンロード] ボタンを選択して、新しくトレーニングされた LoRA アダプターをダウンロードするオプションが表示されます。 通常、微調整ジョブが完了するまでに平均 45 ~ 60 分かかります。
推論
トレーニングは、AI モデルが大規模なデータセットから学習し、パターンと相関関係を認識する最初のフェーズです。 一方、推論は、トレーニング済みのモデル (この場合は Phi Silica) が新しいデータ (LoRA アダプター) を使用して、よりカスタマイズされた出力を生成する予測または決定を行うアプリケーション フェーズです。
トレーニング済みの LoRA アダプターを適用するには:
AI Dev Gallery アプリを使用します。 AI Dev Gallery は、サンプル コードの表示とエクスポートに加えて、ローカルの AI モデルと API を試用できるアプリです。 AI Dev Gallery の詳細を確認します。
AI Dev Gallery をインストールしたら、アプリを開いて [AI API] タブを選択し、[Phi Silica LoRA] を選択します。
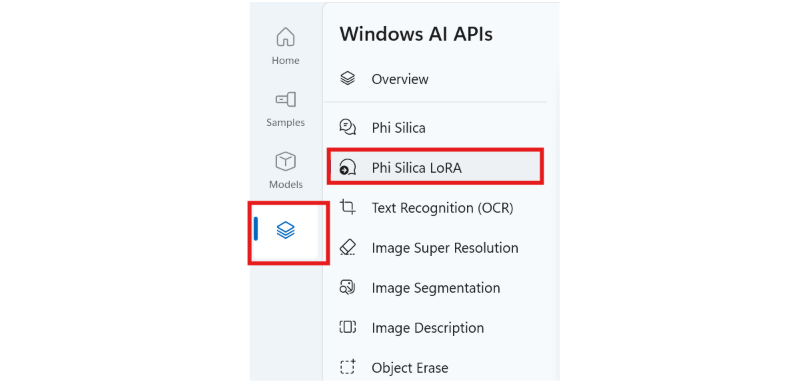
アダプター ファイルを選択します。 格納される既定の場所は、
Desktop/lora_lab/trainedLoraです。[システム プロンプト] フィールドと [プロンプト] フィールドを記入します。 次に、[生成] を選択して、LoRA アダプターの有無に関する Phi Silica の違いを確認します。
プロンプトとシステム プロンプトを試して、これが出力にどのように違いを生み出すのかを確認します。
[サンプルのエクスポート] を選択して、このサンプル コードのみを含むスタンドアロンの Visual Studio ソリューションをダウンロードします。
応答を生成する
AI Dev Gallery を使用して新しい LoRA アダプターをテストしたら、以下のコード サンプルを使用して、Windows アプリにアダプターを追加できます。
using Microsoft.Windows.AI.Text;
using Microsoft.Windows.AI.Text.Experimental;
// Path to the LoRA adapter file
string adapterFilePath = "C:/path/to/adapter/file.safetensors";
// Prompt to be sent to the LanguageModel
string prompt = "How do I add a new project to my Visual Studio solution?";
// Wait for LanguageModel to be ready
if (LanguageModel.GetReadyState() == AIFeatureReadyState.NotReady)
{
var languageModelDeploymentOperation = LanguageModel.EnsureReadyAsync();
await languageModelDeploymentOperation;
}
// Create the LanguageModel session
var session = LanguageModel.CreateAsync();
// Create the LanguageModelExperimental
var languageModelExperimental = new LanguageModelExperimental(session);
// Load the LoRA adapter
LowRankAdaptation loraAdapter = languageModelExperimental.LoadAdapter(adapterFilePath);
// Set the adapter in LanguageModelOptionsExperimental
LanguageModelOptionsExperimental options = new LanguageModelOptionsExperimental
{
LoraAdapter = loraAdapter
};
// Generate a response with the LoRA adapter provided in the options
var response = await languageModelExperimental.GenerateResponseAsync(prompt, options);
責任ある AI - 微調整のリスクと制限
お客様が Phi Silica を微調整すると、特定のタスクやドメインでモデルのパフォーマンスと精度を向上させることができますが、お客様が認識する必要がある新しいリスクや制限が生じる可能性もあります。 これらのリスクと制限事項の一部を次に示します。
データの品質と表現: 微調整に使用されるデータの品質と代表性は、モデルの動作と出力に影響を与える可能性があります。 データがノイズ、不完全、古い場合、またはステレオタイプなどの有害なコンテンツが含まれている場合、モデルはこれらの問題を継承し、不正確または有害な結果を生成する可能性があります。 たとえば、データに性別ステレオタイプが含まれている場合、モデルはそれらを増幅して性差別言語を生成できます。 お客様は、データを慎重に選択して前処理し、目的のタスクとドメインに対して関連性があり、多様でバランスが取れるようにする必要があります。
モデルの堅牢性と一般化: モデルの多様で複雑な入力とシナリオを処理する機能は、微調整後、特にデータが狭すぎる場合や特定の場合に低下する可能性があります。 モデルはデータに過剰に適合し、その一般的な知識と機能の一部を失う可能性があります。 たとえば、データがスポーツについてのみである場合、モデルは質問に答えたり、他のトピックに関するテキストを生成したりするのに苦労する可能性があります。 お客様は、さまざまな入力とシナリオでモデルのパフォーマンスと堅牢性を評価し、スコープ外のタスクまたはドメインにモデルを使用しないようにする必要があります。
逆流: トレーニング データは Microsoft やサード パーティのお客様には利用できませんが、微調整が不十分なモデルでは、トレーニング データが逆流したり、直接繰り返されたりする可能性があります。 お客様は、トレーニング データから PII またはその他の方法で保護された情報を削除する責任を負い、オーバーフィットやその他の低品質の応答のために微調整されたモデルを評価する必要があります。 逆流を避けるために、顧客は大規模で多様なデータセットを提供することをお勧めします。
モデルの透明性と説明性: モデルのロジックと推論は、微調整後、特にデータが複雑または抽象的な場合に、より不透明になり、理解しにくくなる可能性があります。 微調整されたモデルでは、予期しない、矛盾した、または矛盾する出力が生成される可能性があり、モデルがそれらの出力に到達した方法や理由を顧客が説明できない場合があります。 たとえば、データが法的用語または医療用語に関する場合、モデルは不正確または誤解を招く出力を生成し、顧客がそれらを検証または正当化できない可能性があります。 お客様は、モデルの出力と動作を監視および監査し、モデルのエンド ユーザーに明確で正確な情報とガイダンスを提供する必要があります。