DirectML アクセラレーションを有効にする方法
DirectML デバイスは、適切な DirectX 12 GPU が使用可能であると仮定して、既定で有効になっています。 TensorFlow 操作は、可能であれば DirectML デバイスに自動的に割り当てられます。
モデルが DirectML アクセラレーションを使用して実行されているかどうかを判断できない場合は、プログラムの最初のステートメントとして tf.debugging.set_log_device_placement(True) を配置すると、TensorFlow によってデバイスの配置情報がコンソールに出力されます。
特定の操作のデバイス配置を制御するにはどうすればよいですか?
他のデバイスと同様に ( TensorFlow ガイド: GPU の使用を参照)、 tf.device() を使用して、実行するデバイスを制御できます。
TensorFlow-DirectML-Plugin を使用して DirectML バックエンドで TensorFlow 2 を実行する場合、デバイス文字列は 'GPU'され、他のすべてのデバイスが自動的にオーバーライドされます。 デバイス名を変更するには、 ソースから tensorflow-directml-plugin をビルドします。
TensorFlow-DirectML 1.15 の場合、デバイス文字列は 'DML'。
import tensorflow as tf
tf.debugging.set_log_device_placement(True)
tf.enable_eager_execution()
# Explicitly place tensors on the DirectML device
with tf.device('/DML:0'):
a = tf.constant([1.0, 2.0, 3.0])
b = tf.constant([4.0, 5.0, 6.0])
c = tf.add(a, b)
print(c)
Executing op Add in device /job:localhost/replica:0/task:0/device:DML:0
tf.Tensor([5. 7. 9.], shape=(3,), dtype=float32)
複数の GPU があります。 DirectML で使用するものを選択するにはどうすればよいですか?
これを行うには、プロセス全体またはセッションごと (またはその両方) を制御するかどうかに応じて、いくつかの方法があります。
プロセス全体で TensorFlow に表示されるデバイスを制御する場合は、 DML_VISIBLE_DEVICES 環境変数を使用します。 セッションごとに制御する場合は、 tf.GPUOptions.visible_device_listを使用します。
'DML_VISIBLE_DEVICES' 環境変数を使用して、DirectML で使用される GPU を制御するにはどうすればよいですか?
TensorFlow と DirectML では、 DML_VISIBLE_DEVICES 環境変数がサポートされています。この環境変数は、デバイス ID のコンマ区切りリスト ("アダプター インデックス" とも呼ばれます) の形式をとります。設定すると、そのリスト内のデバイス ID のみが TensorFlow プロセス全体に表示されます。
DML_VISIBLE_DEVICESを使用して除外されたデバイスは、TensorFlow で使用できる物理デバイスの一覧には表示されません。
import tensorflow as tf
tf.debugging.set_log_device_placement(True)
tf.enable_eager_execution()
a = tf.constant([1.])
b = tf.constant([2.])
c = tf.add(a, b)
print(c)
設定されていない出力DML_VISIBLE_DEVICES例を次に示します。
DirectML device enumeration: found 2 compatible adapters.
DirectML: creating device on adapter 0 (NVIDIA TITAN V)
DirectML: creating device on adapter 1 (AMD Radeon RX 5700 XT)
Executing op Add in device /job:localhost/replica:0/task:0/device:DML:0
tf.Tensor([3.], shape=(1,), dtype=float32)
DML_VISIBLE_DEVICES="1" を使用する場合:
DirectML device enumeration: found 1 compatible adapters.
DirectML: creating device on adapter 0 (AMD Radeon RX 5700 XT)
Executing op Add in device /job:localhost/replica:0/task:0/device:DML:0
tf.Tensor([3.], shape=(1,), dtype=float32)
表示されるデバイスをインデックス 1 (AMD Radeon RX 5700 XT) のみに制限することで、TensorFlow はこのデバイスに 0 の ID を割り当て、既定になります。
この環境変数を使用して、デバイスの順序を変更することもできます。 たとえば、 DML_VISIBLE_DEVICES="1,0"設定します。
DirectML device enumeration: found 2 compatible adapters.
DirectML: creating device on adapter 0 (AMD Radeon RX 5700 XT)
DirectML: creating device on adapter 1 (NVIDIA TITAN V)
Executing op Add in device /job:localhost/replica:0/task:0/device:DML:0
tf.Tensor([3.], shape=(1,), dtype=float32)
2 つの GPU (NVIDIA TITAN V と AMD Radeon RX 5700 XT) が場所を切り替えました。
特定のデバイスが表示されないようにするには、コンマ区切りの一覧に無効な ID ( -1 など) を指定します。 無効なエントリの後のすべてのデバイス ID は無視されます。 これを使用して、DirectML アクセラレーションを完全に無効にすることもできます。
DML_VISIBLE_DEVICES="-1":
DirectML device enumeration: found 0 compatible adapters.
Executing op Add in device /job:localhost/replica:0/task:0/device:CPU:0
tf.Tensor([3.], shape=(1,), dtype=float32)
"visible_device_list" セッション オプションを使用して、セッションの実行に使用する GPU DirectML を制御するにはどうすればよいですか?
DML_VISIBLE_DEVICESと同様に、同様の文字列を設定して、セッション レベルで表示されるデバイスを制御することもできます。
visible_device_list属性は、TensorFlow セッションを作成するときに、GPUOptions クラスで使用できます。
import tensorflow as tf
a = tf.constant([1.])
b = tf.constant([2.])
c = tf.add(a, b)
gpu_config = tf.GPUOptions()
gpu_config.visible_device_list = "1"
session = tf.Session(config=tf.ConfigProto(gpu_options=gpu_config))
print(session.run(c))
DirectML device enumeration: found 2 compatible adapters.
DirectML: creating device on adapter 1 (AMD Radeon RX 5700 XT)
[3.]
詳細については、 TensorFlow GPUOptions API リファレンス を参照してください。
tensorflow-directml の共有 GPU メモリ使用率が高い理由
大規模なモデルをトレーニングすると、タスク マネージャーで共有 GPU メモリの使用率が高くなる場合があります。
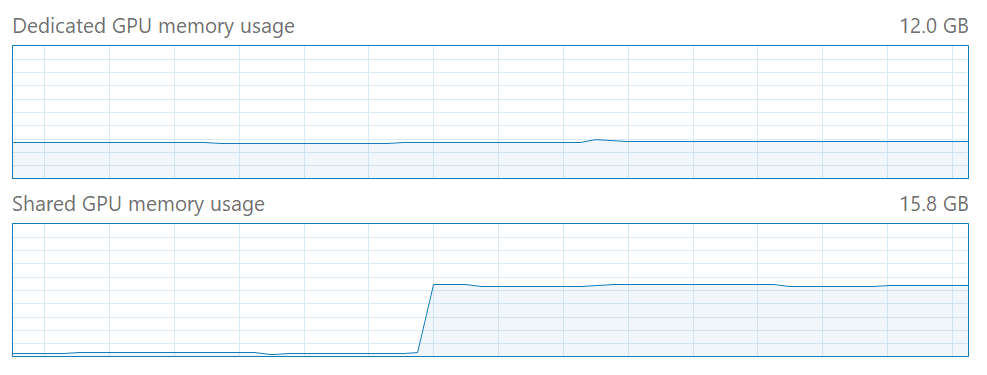
これは正常です。 TensorFlow-DirectML は、GPU との間でテンソル データをアップロードおよび読み取りバックするためのステージング領域として共有 GPU メモリを使用します。 このため、共有 GPU メモリ使用率の一部の増加が予想されます。
DirectML では、システム メモリ (使用可能な場合) に優先して専用 GPU メモリ (VRAM のオンボードなど) が常に使用されることに注意してください。 ただし、DirectML で必要なステージング メモリの量に応じて、共有 GPU メモリの一部の使用量が引き続き予想されます。
DirectML で使用可能なすべての専用 GPU メモリが利用されないのはなぜですか?
CUDA デバイスなどの一部のデバイスでは、既定では、起動時に使用可能な専用 GPU メモリの大部分が予約されます。
ただし、DirectML デバイスは、メモリを予約するのではなく、必要に応じて割り当てます。 この動作により、GPU メモリの他のシステム プロセスが不足することは回避されますが、メモリ オーバーヘッドが若干高くなる場合があります。
メモリを事前に予約する場合は、TF_FORCE_GPU_ALLOW_GROWTH環境変数をに設定することで、それを制御できます。
tensorflow-directml で使用される環境変数の詳細については、「 環境変数」を参照してください。
DXGI_ERROR_DEVICE_REMOVEDエラーまたはDEVICE_HUNG エラーが表示されます。 これらの問題を解決するにはどうすればよいですか?
GitHub: tensorflow-directml での GPU タイムアウトのトラブルシューティングに関するページの手順を参照してください。
デバイスの割り当てまたはノードのコロケーション エラーが発生する理由
次のようなエラーが表示される場合:
tensorflow.python.framework.errors_impl.InvalidArgumentError: Cannot assign a
device for operation
tensorflow/core/common_runtime/colocation_graph.cc:983] Failed to place the
graph without changing the devices of some resources. Some of the operations
(that had to be colocated with resource generating operations) are not
supported on the resources' devices. Current candidate devices are [...]
これは通常、DirectML デバイスでサポートされていない演算子、またはサポートされていない演算子とデータ型の組み合わせを使用しようとしていることを意味します。 サポートされている演算子の完全な一覧については、Wiki の ロードマップ (演算子) を参照してください。