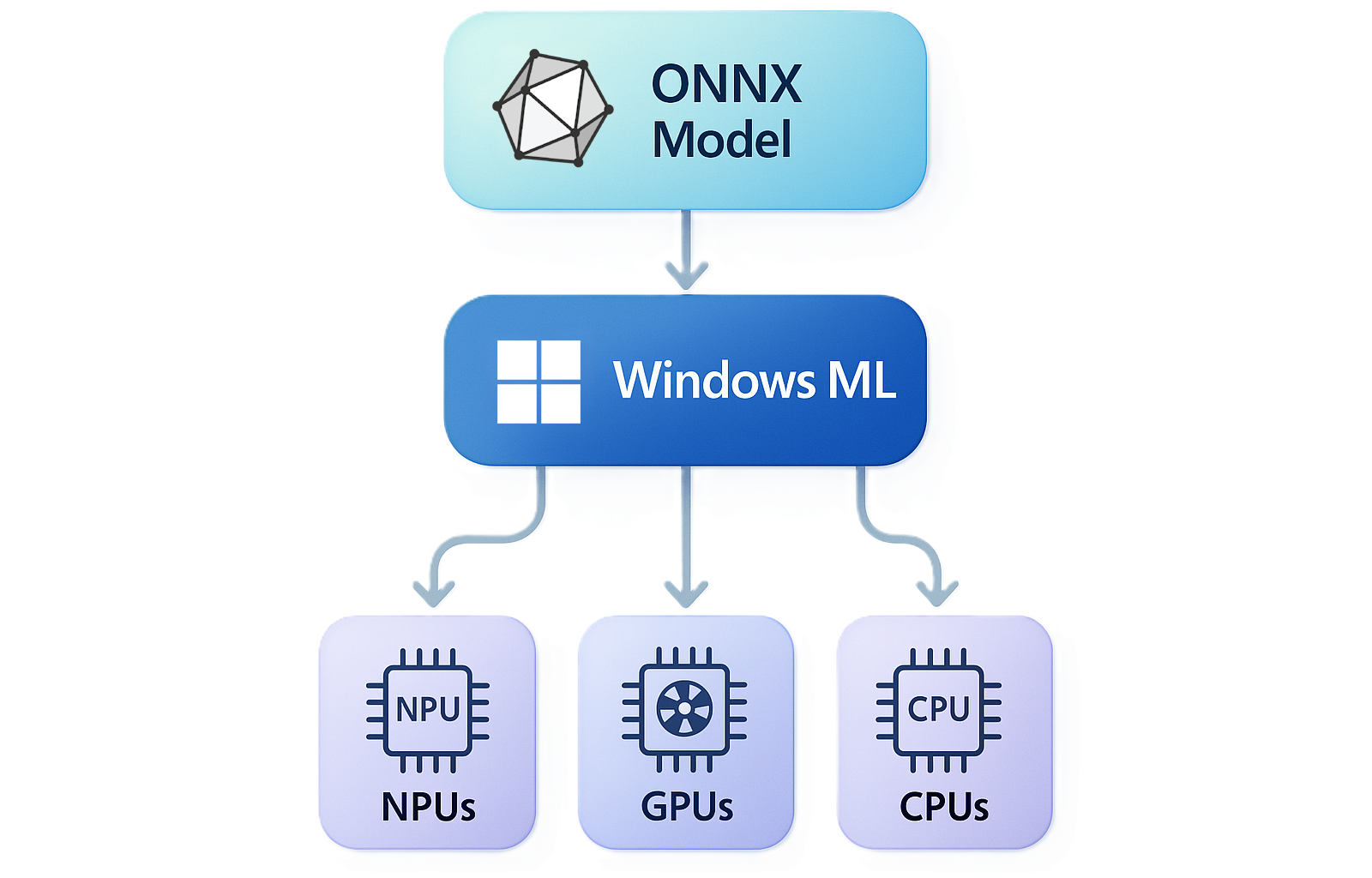
Windows ML は、 ONNX Runtime を利用した、Windows 用の統合および高パフォーマンスのローカル AI 推論フレームワークです。 Windows ML を使用すると、WINDOWS が管理および最新の状態を維持するオプションの実行プロバイダーを使用して、AI モデルをローカルで実行し、NPU、GPU、および CPU での推論を高速化できます。 PyTorch、TensorFlow/Keras、TFLite、scikit-learn、およびその他のフレームワークのモデルを Windows ML で使用できます。
主な利点
Windows ML を使用すると、任意の Windows アプリに AI 推論を簡単に取り込めます。
- デバイス上で AI を実行 する — モデルはユーザーのハードウェア上でローカルに実行され、データをプライベートに保ち、クラウド コストを排除し、インターネットに接続せずに動作します。
- 既に持っているモデルを使用ーPyTorch、TensorFlow、scikit-learn、Hugging Face などからモデルを持ち込むことができます。
- Windows によって促進されるハードウェア アクセラレーション — Windows ML では、Windows Update を介して Windows がインストールして最新の状態に保つ実行プロバイダーを介して IHV 固有の NPU、GPU、および CPU にアクセスできます。アプリに実行プロバイダーをバンドルする必要はありません。
- 1 つのランタイム、多くのアプリ — Windows ML を共有システムコンポーネントとしてオプションで使用することで、アプリはコンパクトに保たれ、デバイス上のすべてのアプリが最新のランタイムを共有し、それぞれのアプリが独自のコピーをバンドルせずに済みます。
- クラス最高のパフォーマンス — Windows ML は、RTX 用 TensorRT や Qualcomm の AI Engine Direct などの専用 SDK と同等に、NPU と GPU で金属に対するパフォーマンスを実現します。 パフォーマンスの結果は、ハードウェアの構成とモデルによって異なります。ハードウェア固有のガイダンスについては、 AI モデルの高速化 に関するページを参照してください。
Microsoft ORT の代わりに Windows ML を使用する理由
Windows ML は、システム全体のコピーまたは自己完結型として使用できる、Windows でサポートされ保守されている ONNX Runtime (ORT) のコピーです。
- 同じ ONNX API - 既存の ONNX ランタイム コードに変更はありません
- Windows でサポートされる — Windows チームによってサポートおよび保守されています
- 広範なハードウェア サポート — 任意のハードウェア構成で Windows PC (x64 および ARM64) および Windows Server 上で実行されます
- オプションの小さいアプリ サイズ — フレームワークに依存するデプロイを選択し、独自のコピーをバンドルするのではなく、アプリ間でランタイムを共有します
- オプションの常緑更新プログラム - フレームワークに依存する展開を選択し、ユーザーは常に Windows Update 経由で最新のランタイムを取得します
さらに、Windows ML を使用すると、アプリに実行プロバイダーを含めて異なるハードウェア用に個別のビルドを作成することなく、最新の実行プロバイダーを動的に取得してAIモデルの動作を加速できます。
「Windows ML の使用を開始して自分で試す」を参照してください。
NPU、GPU、および CPU でのハードウェア アクセラレーション
Windows ML を使用すると、最新の Windows PC に存在する 3 つのシリコン クラスで推論を高速化できる実行プロバイダーにアクセスできます。
- NPU — バッテリ効率に優れ、デバイス上で持続的な推論が可能で、Copilot+ PC で最も強力な NPU を使用できます
- GPU — 画像、ビデオ、生成 AI などの高スループットのワークロード。一般に、ディスクリート GPU で最大のパフォーマンスを提供します
- CPU — ユニバーサル フォールバックと IHV 最適化 CPU アクセラレーション
シリコンからEPへのマッピング、EPのドライバー要件、及びEP調達オプションについては、「AIモデルの高速化」を参照してください。
システム要件
- OS: Windows アプリ SDK がサポートするWindowsのバージョン
- アーキテクチャ: x64 または ARM64
- ハードウェア: 任意の PC 構成 (CPU、統合/個別 GPU、NPU)
注
CPU と GPU (DirectML 経由) のサポートは、サポートされているすべてのWindows バージョンで利用できます。 NPU および特定の GPU ハードウェア用のハードウェア最適化実行プロバイダーには、Windows 11 バージョン 24H2 (ビルド 26100) 以上が必要です。 詳細については、「 Windows ML 実行プロバイダー」を参照してください。
パフォーマンスの最適化
最新バージョンの Windows ML は GPU と NPU の専用実行プロバイダーと直接連携し、過去の専用 SDK (RTX 用 TensorRT、AI エンジン ダイレクト、PyTorch 用 Intel の拡張機能など) と同等のパフォーマンスを実現します。 IHV 固有の SDK を配布するアプリを必要とせずに、クラス最高の GPU と NPU のパフォーマンスを実現するように Windows ML を設計しました。 パフォーマンスの結果は、ハードウェアの構成とモデルによって異なります。ハードウェア固有のガイダンスについては、 AI モデルの高速化 に関するページを参照してください。
モデルを ONNX に変換する
モデルを他の形式から ONNX に変換して、Windows ML で使用できます。 詳細については、foundry Toolkit for Visual Studio Codeのドキュメントで、モデルを ONNX 形式に<>変換する方法を参照してください。 PyTorch、TensorFlow、Hugging Face モデルを ONNX に変換する方法の詳細については、 ONNX ランタイム チュートリアル も参照してください。
モデルの分布
Windows ML には、AI モデルを配布するための柔軟なオプションが用意されています。
- アプリ間でモデルを共有 する - 大きなファイルをバンドルすることなく、CDN からアプリ間でモデルを動的にダウンロードして共有する
- ローカル モデル - アプリケーション パッケージにモデル ファイルを直接含める
Windows AI エコシステムとの統合
Windows ML は、より広範なWindows AI プラットフォームの基盤として機能します。
- Windows AI API - 一般的なタスク用の組み込みモデル
- Foundry Local - すぐに使用できる AI モデル
- Custom モデル - 高度なシナリオにWindows ML API への直接アクセス
フィードバックの提供
問題が見つかったか、または提案がありますか? Windows アプリ SDK GitHubで問題を検索または作成します。
次のステップ
- AI モデルの実行 - Windows ML をインストールし、最初の ONNX モデルを実行する
- AI モデルの高速化 - 推論を高速化するために NPU、GPU、または CPU 実行プロバイダーを追加する
- モデルを検索またはトレーニング する - Windows ML と互換性のあるモデルを検索する
- API リファレンス - Microsoft.WindowsAppSDK.ML パッケージ内の WinRT および ONNX ランタイム API