音声認識とテキスト読み上げ (TTS または音声合成とも呼ばれます) をアプリのユーザー エクスペリエンスに直接統合します。
音声認識 音声認識は、ユーザーが話した単語を、フォーム入力、テキストディクテーション、アクションまたはコマンドの指定、タスクの実行のためにテキストに変換します。 これは、フリー テキストディクテーションと Web 検索の定義済みの文法と、音声認識文法仕様 (SRGS) バージョン 1.0 を使用して作成されたカスタム文法の両方をサポートしています。
Speech synthesis/Text to Speech (TTS) TTS は音声合成エンジン (音声) を使用してテキスト文字列を音声に変換します。 入力文字列には、基本的な、非対応のテキスト、またはより複雑な音声合成マークアップ言語 (SSML) のいずれかを指定できます。 SSML は、発音、音量、ピッチ、速度、速度、強調など、音声出力の特性を制御する標準的な方法を提供します。
音声操作の設計
音声を慎重に設計して実装すると、ユーザーがWindows アプリケーションと対話し、マウス、キーボード、コントローラー、タッチに基づく従来の操作エクスペリエンスを補完または置き換える、効果的でアクセスしやすい自然な方法になります。
これらのガイドラインと推奨事項では、音声認識と TTS の両方をアプリの対話エクスペリエンスに最適に統合する方法について説明します。
アプリで音声操作をサポートすることを検討している場合は、次の点を自問してください。
- ユーザーは音声を通じてどのようなアクションを実行できますか? ページ間を移動したり、コマンドを呼び出したり、テキスト フィールド、簡単なメモ、または長いメッセージとしてデータを入力することはできますか?
- 音声入力は、タスクを完了するための適切なオプションですか?
- 音声入力が使用可能な場合、ユーザーはどのように認識されますか?
- アプリは常にリッスンしているか、またはユーザーがアプリがリッスン モードに入るためのアクションを実行する必要がありますか?
- アクションまたは動作を開始する語句は何ですか? 画面上でフレーズとアクションを列挙する必要がありますか?
- プロンプト、確認、あいまいさを解消する画面または TTS は必要ですか?
- アプリとユーザーの間の対話ダイアログとは
- アプリのコンテキストには、カスタムまたは制約付きのボキャブラリが必要ですか (医学、科学、ロケールなど)。
- ネットワーク接続は必要ですか?
テキスト入力
テキスト入力の範囲は、1 つの単語や語句などの短いフォーム入力から、複数の語句、段落、連続ディクテーションなどの長いフォーム入力までです。 短いフォーム入力の長さは通常 10 秒未満ですが、長いフォーム入力セッションの長さは最大 2 分です。 長いフォーム入力は、ユーザーの介入なしに再起動して、継続的なディクテーションの印象を与えることができます。
音声認識がサポートされ、ユーザーが使用できるかどうかを示す視覚的な手掛かりを提供し、ユーザーが有効にする必要があるかどうかを示します。 たとえば、マイク グリフ (コマンド バーを参照) と共にコマンド バー ボタンを使用して、可用性と状態の両方を表示します。
認識中の明らかな応答不足を最小限に抑えるために、継続的な認識フィードバックを提供します。
キーボード入力、あいまいさを解消するプロンプト、提案、または追加の音声認識を使用して、ユーザーが認識テキストを修正できるようにします。
タッチやキーボードなどの音声認識以外のデバイスから入力が検出された場合は、認識を停止します。 この入力は、認識テキストの修正や他のフォーム フィールドとの対話など、ユーザーが別のタスクに移動したことを示している可能性があります。
音声認識が終了したことを音声入力が示さない時間を指定します。 通常、ユーザーがアプリの操作を停止したことを示しているため、この期間が経過した後に認識を自動的に再開しないでください。
場合によっては、音声認識をサポートするためにネットワーク接続が必要になる場合があります。 使用できない場合は、すべての継続的認識 UI を無効にして、認識セッションを終了します。
指揮
音声入力では、アクションの開始、コマンドの呼び出し、タスクの実行を行うことができます。
領域が許可されている場合は、有効な入力の例と共に、現在のアプリ コンテキストでサポートされている応答を表示することを検討してください。 この方法により、アプリで処理する必要がある潜在的な応答が減り、ユーザーの混乱も排除されます。
質問をフレームに収め、可能な限り具体的な回答を引き出すようにします。 たとえば、"今日何をしたいですか" は非常にオープンで、応答の種類がどのくらい異なるかによって、非常に大きな文法定義が必要です。 または、"ゲームをプレイしますか、音楽を聴くか" は、対応する小さな文法定義を持つ 2 つの有効な回答のいずれかに応答を制限します。 小さな文法を作成すると、はるかに簡単に作成でき、より正確な認識結果が得られます。
音声認識の信頼度が低い場合は、ユーザーに確認を要求します。 ユーザーの意図が明確でない場合は、意図しないアクションを開始するよりも明確にすることをお勧めします。
音声認識がサポートされ、ユーザーが使用できるかどうかを示す視覚的な手掛かりを提供し、ユーザーが有効にする必要があるかどうかを示します。 たとえば、マイク グリフ (コマンド バー のガイドラインを参照) と共にコマンド バー ボタンを使用して、可用性と状態の両方を表示します。
音声認識スイッチが通常表示外の場合は、アプリのコンテンツ領域に状態インジケーターを表示することを検討してください。
ユーザーが認識を開始する場合は、一貫性のために組み込みの認識エクスペリエンスを使用することを検討してください。 組み込みのエクスペリエンスには、プロンプト、例、あいまいさの解消、確認、エラーを含むカスタマイズ可能な画面が含まれます。
画面は、指定された制約によって異なります。
定義済みの文法 (ディクテーションまたは Web 検索)
- リスニング 画面。
- [考える] 画面。
- 「あなたの発言を聞いた」画面、またはエラー画面。
単語または語句の一覧、または SRGS 文法ファイル
- リスニング 画面。
- ユーザーの発言が複数の結果として解釈される可能性がある場合は、「言いましたか」画面が表示されます。
- 「あなたの発言を聞いた」画面、またはエラー画面。
[Listening]\(リスニング\) 画面では、次のことができます。
- 見出しテキストをカスタマイズします。
- ユーザーが言うことができる内容のテキストの例を指定します。
- あなたが言ったことを聞きました 画面が表示されるかどうかを指定します。
- 認識された文字列を「聞き取り内容」画面でユーザーに読み上げます。
次の図は、SRGS で定義された制約を使用する音声認識エンジンの組み込み認識フローの例を示しています。 この例では、音声認識は成功しています。
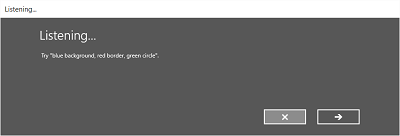
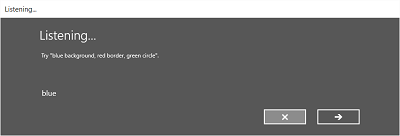
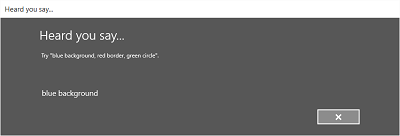
常に聞いている
アプリは、ユーザーの介入なしに、アプリが起動するとすぐに音声入力をリッスンして認識できます。
アプリコンテキストに基づいて文法の制約をカスタマイズします。 このアプローチにより、音声認識エクスペリエンスは、現在のタスクに対して非常にターゲットを絞り込み、関連を維持し、エラーを最小限に抑えます。
"私は何を言うことができますか?
音声入力を有効にすると、アプリが理解できる内容と実行できるアクションをユーザーが見つけ出すことができます。
ユーザーが音声認識を有効にする場合は、コマンド バーまたはメニュー コマンドを使用して、現在のコンテキストでサポートされているすべての単語と語句を表示することを検討してください。
音声認識が常にオンになっている場合は、すべてのページに "What can I say?" という語句を追加することを検討してください。 ユーザーがこの語句を言うときは、現在のコンテキストでサポートされているすべての単語と語句を表示します。 このフレーズを使用すると、ユーザーがシステム全体で音声機能を検出するための一貫した方法が提供されます。
認識エラー
音声認識が失敗する可能性があります。 エラーは、オーディオ品質が低い場合、認識エンジンが語句の一部のみを検出した場合、または認識エンジンが入力をまったく検出しなかった場合に発生します。
エラーを適切に処理し、認識が失敗した理由をユーザーが理解し、回復できるようにします。
アプリは、認識エンジンが認識できなかったことをユーザーに通知し、もう一度試す必要があることを通知する必要があります。
サポートされている 1 つ以上のフレーズの例を提供することを検討してください。 ユーザーは、推奨されるフレーズを繰り返す可能性が高く、認識の成功率が向上します。
ユーザーが選択できる一致候補の一覧を表示します。 この方法は、再び認識プロセスを実行するよりもはるかに効率的です。
常に代替入力の種類をサポートします。これは、認識エラーの繰り返し処理に特に役立ちます。 たとえば、ユーザーがキーボードを使用しようとしたり、タッチやマウスを使用して一致する可能性のある一覧から選択したりすることを提案できます。
組み込みの音声認識エクスペリエンスを使用します。これには、認識が成功しなかったことをユーザーに通知し、ユーザーが別の認識を試みることができる画面が含まれているためです。
オーディオ入力の問題を聞いて修正してみてください。 音声認識エンジンは、音声認識の精度に悪影響を与える可能性があるオーディオ品質の問題を検出できます。 音声認識エンジンによって提供される情報を使用して、問題をユーザーに通知し、可能であれば修正措置を取るようにすることができます。 たとえば、マイクの音量設定が低すぎる場合は、ユーザーに大きな声で話すか、音量を上げるよう求めることができます。
制約
制約 (文法) は、音声認識エンジンが一致できる話し言葉と語句を定義します。 定義済みの Web サービス文法のいずれかを指定することも、アプリでインストールするカスタム文法を作成することもできます。
定義済みの文法
定義済みのディクテーションと Web 検索文法は、文法を作成しなくてもアプリの音声認識を提供します。 これらの文法を使用すると、リモート Web サービスが音声認識を実行し、結果をデバイスに返します。
- 既定のフリー テキストディクテーション文法は、ユーザーが特定の言語で言うことができるほとんどの単語と語句を認識します。 短い語句を認識するように最適化されています。 ユーザーが言える内容の種類を制限したくない場合は、フリー テキストディクテーションを使用します。 一般的な用途としては、ノートの作成やメッセージのコンテンツのディクテーションなどがあります。
- ディクテーション文法のような Web 検索文法には、ユーザーが言う可能性のある多数の単語や語句が含まれています。 ただし、ユーザーが Web を検索するときに通常使用する用語を認識するように最適化されています。
注
定義済みのディクテーションと Web 検索の文法は大きくなる可能性があり、オンラインであるため (デバイス上にないため)、デバイスにカスタム文法がインストールされている場合ほどパフォーマンスが速くない可能性があります。
これらの定義済みの文法では、最大 10 秒の音声入力を認識でき、作成作業は必要ありません。 ただし、ネットワークへの接続が必要です。
カスタム文法
カスタム文法を設計して作成し、アプリと共にインストールします。 デバイスは、カスタム制約を使用して音声認識を実行します。
プログラムによるリスト制約は、単語または語句のリストを使用して単純な文法を作成するための軽量なアプローチを提供します。 リスト制約は、短い個別の語句を認識する場合に適しています。 文法内のすべての単語を明示的に指定すると、音声認識エンジンは一致を確認するために音声のみを処理する必要があります。そのため、認識の精度も向上します。 プログラムを使用してリストを更新することもできます。
SRGS 文法は、プログラムによるリスト制約とは異なり、 SRGS バージョン 1.0 で定義された XML 形式を使用する静的ドキュメントです。 SRGS 文法では、1 回の認識で複数のセマンティック意味をキャプチャできるため、音声認識エクスペリエンスを最大限に制御できます。
SRGS 文法を作成するためのヒントを次に示します。
- 各文法を簡潔に保ちます。 語句が少ない文法では、多くの語句を含む大きな文法よりも正確な認識が提供される傾向があります。 アプリ全体に対して 1 つの文法を使用するよりも、特定のシナリオに合わせていくつかの小さな文法を使用することをお勧めします。
- アプリ コンテキストごとに何を言うかをユーザーに知らせ、必要に応じて文法を有効または無効にします。
- ユーザーがさまざまな方法でコマンドを話すことができるように、各文法を設計します。 たとえば、 ガベージ ルールを使用して、文法で定義されていない音声入力と一致させます。 このルールにより、ユーザーはアプリに意味のない追加の単語を話すことができます。 たとえば、"give me"、"and"、"uh"、"maybe"などです。
- sapi:subset 要素を使用して、音声入力の一致を支援します。 この要素は、部分的な語句の照合に役立つ、SRGS 仕様に対する Microsoft の拡張機能です。
- 1 つの音節のみを含む語句を文法で定義しないようにします。 2 つ以上の音節を含む語句では、認識がより正確になる傾向があります。
- 似た音の語句は使用しないでください。 たとえば、"hello"、"bellow"、"fellow" などの語句は、認識エンジンを混乱させ、認識精度が低下する可能性があります。
注
使用する制約の種類は、作成する認識エクスペリエンスの複雑さによって異なります。 任意の種類が特定の認識タスクに最適な選択肢であり、アプリ内のすべての種類の制約の用途が見つかる場合があります。
カスタム発音
通常とは異なる単語や架空の単語を含む特殊なボキャブラリや、一般的でない発音の単語がアプリに含まれている場合は、カスタム発音を定義することで、それらの単語の認識パフォーマンスを向上させることができます。
単語や語句の小さな一覧、または使用頻度の低い単語や語句の一覧については、SRGS 文法でカスタム発音を作成します。 詳細については、 token 要素 を参照してください。
単語や語句の一覧が大きい場合、またはよく使用される単語や語句の場合は、個別の発音辞書ドキュメントを作成します。 詳細については、「辞書と音声記号について」を参照してください。
テスト
音声認識の精度とサポート UI をアプリの対象ユーザーでテストします。 このアプローチは、アプリでの音声対話エクスペリエンスの効果を判断するのに役立ちます。 たとえば、アプリが一般的な語句をリッスンしないために、ユーザーの認識結果が悪くなっているとします。
この語句をサポートするように文法を変更するか、サポートされている語句の一覧をユーザーに提供します。 サポートされている語句の一覧を既に指定している場合は、ユーザーが簡単に見つけられるようにします。
テキスト読み上げシステム (TTS)
TTS は、プレーン テキストまたは SSML から音声出力を生成します。
丁寧で励みになるプロンプトを設計してみてください。
長い文字列のテキストを読む必要があるかどうかを検討します。 テキスト メッセージを聞くのは 1 つのことですが、覚えにくい検索結果の長い一覧を聞くのもまったく別の方法です。
ユーザーが TTS を一時停止または停止できるようにメディア コントロールを提供します。
すべての TTS 文字列に耳を傾けて、理解可能で自然な音になるようにします。
- 通常とは異なる一連の単語を一緒に文字列化したり、パート番号や句読点を話したりすると、語句が理解できなくなる可能性があります。
- プロソディやケイデンスがネイティブスピーカーがフレーズを言う方法と異なる場合、音声は不自然に聞こえる可能性があります。
音声シンセサイザーへの入力としてプレーン テキストではなく SSML を使用することで、両方の問題に対処できます。 SSML の詳細については、「 SSML を使用して合成音声 と 音声合成マークアップ言語リファレンスを制御する」を参照してください。