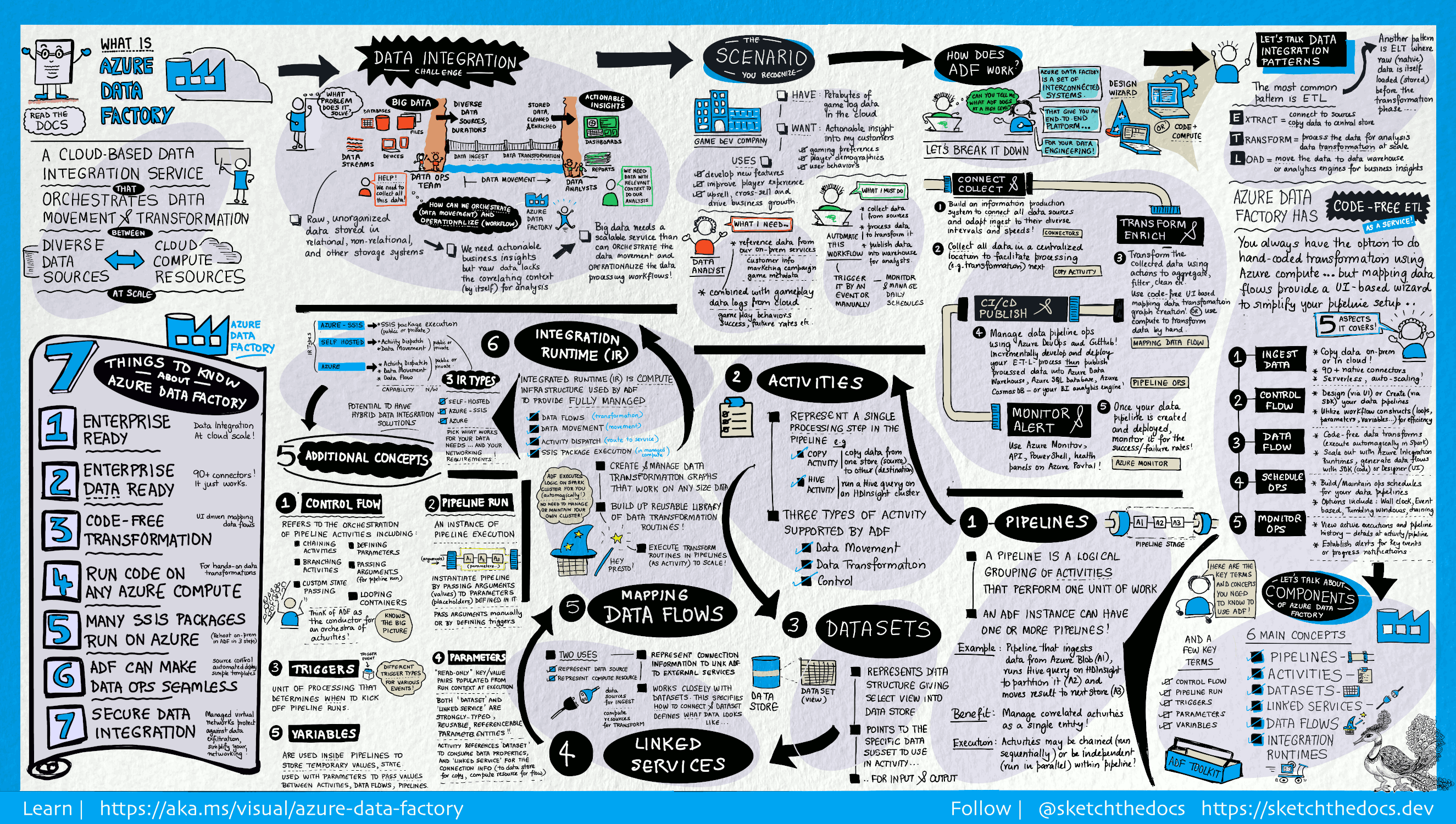
Что такое Фабрика данных Azure?
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure
Фабрика данных Azure  Azure Synapse Analytics
Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В мире больших данных в реляционных, нереляционных и других системах хранения часто хранятся необработанные и неорганизованные данные. Но необработанные данные сами по себе не содержат нужного контекста или значения, чтобы быть полезными для аналитиков, специалистов по анализу данных и руководителей компаний.
Для работы с большими данными нужна служба, которая поддерживает процессы организации и подготовки к использованию, для анализа этих огромных объемов необработанных данных и преобразования их в полезные данные. Фабрика данных Azure — это управляемая облачная служба, созданная для сложных гибридных процессов извлечения, преобразования и загрузки (или извлечения, загрузки и преобразования) и интеграции данных.
Функции Фабрика данных Azure
Сжатие данных. Во время действие Copy данных можно сжать данные и записать сжатые данные в целевой источник данных. Эта функция помогает оптимизировать использование пропускной способности при копировании данных.
Расширенная поддержка подключения для разных источников данных: Фабрика данных Azure обеспечивает широкую поддержку подключения к разным источникам данных. Это полезно, если требуется извлекать или записывать данные из разных источников данных.
Пользовательские триггеры событий: Фабрика данных Azure позволяет автоматизировать обработку данных с помощью пользовательских триггеров событий. Эта функция позволяет автоматически выполнять определенное действие при возникновении определенного события.
Предварительный просмотр и проверка данных. Во время действие Copy данных средства предоставляются для предварительного просмотра и проверки данных. Эта функция помогает убедиться, что данные копируются правильно и записываются в целевой источник данных.
Настраиваемые Поток данных: Фабрика данных Azure позволяет создавать настраиваемые потоки данных. Эта функция позволяет добавлять пользовательские действия или шаги для обработки данных.
Встроенная безопасность: Фабрика данных Azure предлагает интегрированные функции безопасности, такие как интеграция идентификатора Записи и управление доступом на основе ролей для управления доступом к потокам данных. Эта функция повышает безопасность обработки данных и защищает данные.
Сценарии использования
В качестве примера рассмотрим компанию, которая создает облачные игры и собирает петабайты информации в виде журналов этих игр. Компания хочет проанализировать эти журналы, чтобы получить сведения о предпочтениях клиентов, демографических параметрах и особенностях использования. Эти сведения помогут понять, как можно увеличить дополнительные и перекрестные продажи, разработать новые интересные функции, стимулировать развитие компании и улучшить качество обслуживания клиентов.
Чтобы проанализировать эти журналы, компании необходимо использовать справочные сведения, например информацию о клиентах, игре и маркетинговых действиях, которые хранятся в локальном хранилище данных. Компании нужно объединить эти данные из локального хранилища данных с дополнительными данными журналов, собранными в облачном хранилище данных.
Чтобы получить аналитические данные, компания обработает объединенные данные с помощью кластера Spark в облаке (Azure HDInsight), а затем опубликует преобразованные данные в облачное хранилище данных, например Azure Synapse Analytics, из которого можно будет легко получать нужные отчеты. Этот рабочий процесс должен выполняться автоматически при помещении файлов в контейнер хранилища больших двоичных объектов и должен ежедневно отслеживаться. Кроме того, должно быть налажено ежедневное управление им.
Фабрика данных Azure является идеальной платформой для таких сценариев обработки данных. Это облачная служба извлечения, преобразования, загрузки и интеграции данных, которая позволяет создавать управляемые данными рабочие процессы для оркестрации и автоматизации масштабных операций перемещения и преобразования данных. С помощью Фабрики данных Azure можно создавать и включать в расписание управляемые данными рабочие процессы (конвейеры), поддерживающие прием данных из разнородных хранилищ данных, Вы можете создавать сложные процессы извлечения, преобразования и загрузки, которые преобразуют данные через визуальный интерфейс потоков данных или служб вычислений, таких как Azure HDInsight Hadoop, Azure Databricks и База данных SQL Azure.
Кроме того, вы можете публиковать преобразованные данные в хранилищах данных (например, Azure Synapse Analytics) для использования приложениями бизнес-аналитики. Необработанные данные с помощью Фабрики данных Azure можно организовать в полезные хранилища данных и хранилища Data Lake для принятия лучших деловых решений.
Как это работает?
Фабрика данных содержит набор взаимосвязанных систем, предоставляющих комплексную платформу для специалистов по обработке данных.

Данное наглядное руководство обеспечивает подробный обзор всей архитектуры Фабрики данных:

Чтобы увидеть более подробную информацию, выберите предыдущее изображение, чтобы увеличить, или перейдите к изображению с высоким разрешением.
{kind=link}
Подключение и сбор данных
Предприятия собирают данные различных типов в разнородных локальных и облачных источниках данных. Структурированные, неструктурированные или частично структурированные данные поступают с разными интервалами и с разной скоростью.
Первым этапом в создании системы производства информации является подключение ко всем необходимым источникам данных и службам обработки, таким как службы SaaS (программное обеспечение как услуга), базы данных, файловые ресурсы с общим доступом, FTP и веб-службы, и перемещение данных, нуждающихся в последующей обработке, в централизованное расположение.
Не имея фабрики данных предприятия вынуждены создавать компоненты для перемещения пользовательских данных или писать пользовательские службы для интеграции этих источников данных и обработки. Такие системы дорого стоят, их сложно интегрировать и обслуживать. Кроме того, они часто не включают функции мониторинга и оповещений корпоративного уровня, а также элементы управления, которые может предложить полностью управляемая служба.
В фабрике данных вы можете использовать действие копирования в конвейере данных для перемещения данных из локальных и облачных исходных хранилищ данных в централизованное хранилище данных в облаке для последующего анализа. Например, вы можете собирать данные в Azure Data Lake Storage и затем преобразовывать эти данные с помощью службы вычислений Azure Data Lake Analytics. Или же вы можете собрать данные в хранилище BLOB-объектов Azure и позже преобразовать их с помощью кластера Hadoop под управлением службы Azure HDInsight.
Преобразование и дополнение данных
Обрабатывайте или преобразовывайте данные, собранные в централизованном облачном хранилище, с помощью потоков сопоставления данных ADF. Потоки данных позволяют специалистам по обработке данных создавать и обслуживать схемы преобразования данных, которые выполняются в Spark, даже без знаний о кластерах Spark и программировании Spark.
Если вы предпочитаете вручную писать код преобразований, воспользуйтесь поддерживаемыми в ADF внешними действиями для преобразований в таких службах вычислений, как HDInsight Hadoop, Spark, Data Lake Analytics и Машинное обучение.
CI/CD и публикация
Фабрика данных обеспечивает полную поддержку CI/CD для конвейеров данных при использовании Azure DevOps и GitHub. Это позволяет постепенно разрабатывать и предоставлять процессы извлечения, преобразования и загрузки перед публикацией готового продукта. Когда необработанные данные преобразованы в готовую к использованию форму, вы можете передать данные в хранилище данных Azure, Базу данных SQL Azure, Azure Cosmos DB или в любую аналитическую платформу, которую могут выбрать бизнес-пользователи для своих средств бизнес-аналитики.
Azure Monitor
После создания и развертывания конвейера интеграции данных, который извлекает полезные данные из обработанных данных, вам понадобится отслеживать успешное выполнение и сбои запланированных операций и конвейеров. Фабрика данных Azure имеет встроенную поддержку мониторинга конвейеров с помощью Azure Monitor, API, PowerShell, журналов Azure Monitor и панелей работоспособности на портале Azure.
Основные понятия
В подписке Azure может быть один или несколько экземпляров фабрики данных Azure. Фабрика данных Azure состоит из следующих ключевых компонентов:
- Pipelines
- Процедуры
- Наборы данных
- Связанные службы
- Потоки данных
- Среды выполнения интеграции
Они образуют платформу, на которой можно создавать управляемые данными рабочие процессы, предусматривающие перемещение и преобразование данных.
Pipeline
В фабрике данных можно использовать один или несколько конвейеров. Конвейер — это логическая группа действий, которые выполняют определенный блок задач. Действия в конвейере совместно выполняют задачу. Например, конвейер может включать группу действий, которые принимают данные из большого двоичного объекта Azure и выполняют запрос Hive в кластере HDInsight для секционирования данных.
Преимущество конвейера в том, что он позволяет управлять группами действий, а не каждым отдельным действием. Действия в конвейере можно связывать друг с другом последовательно или выполнять параллельно и независимо друг от друга.
Сопоставление потоков данных
Создавайте и администрируйте графов логики преобразования данных, с помощью которых можно преобразовывать данные любого размера. Вы можете повторно создать используемую библиотеку подпрограмм преобразования данных и выполнять эти процессы из конвейеров ADF с поддержкой горизонтального масштабирования. Фабрика данных будет выполнять логику в кластере Spark, который увеличивается и уменьшается по мере необходимости. Вам не придется ни управлять кластерами, ни обслуживать их.
Действие (Activity)
Действия представляют отдельные этапы обработки в конвейере. Например, действие копирования может использоваться для копирования данных из одного хранилища данных в другое. Точно так же можно использовать действие Hive, которое выполняет запрос Hive к кластеру Azure HDInsight, для преобразования или анализа данных. Фабрика данных поддерживает три типа действий: действия перемещения данных, действия преобразования данных и действия управления.
Наборы данных
Наборы данных представляют структуры данных в хранилищах. Эти структуры указывают данные, необходимые для использования в действиях, разделяя их на входные и выходные.
Связанные службы
Связанные службы напоминают строки подключения, определяющие сведения о подключении, необходимые для подключения фабрики данных к внешним ресурсам. Таким образом, набор данных представляет структуру данных, а связанная служба определяет подключение к источнику данных. Например, связанная служба хранилища Azure определяет строку подключения для подключения к учетной записи хранения Azure. Кроме того, набор данных больших двоичных объектов Azure определяет контейнер больших двоичных объектов и папку, которая содержит данные.
Связанные службы используются в фабрике данных для двух целей:
Для представления хранилища данных, включая, помимо прочего, базу данных SQL Server, базу данных Oracle, общую папку и учетную запись хранилища BLOB-объектов Azure. Список поддерживаемых хранилищ см. в статье о действии копирования.
Для представления вычислительного ресурса, в котором можно выполнить действие. Например, действие HDInsightHive выполняется в кластере Hadoop в HDInsight. Список поддерживаемых действий преобразования и вычислительных сред см. в статье о преобразовании данных.
Integration Runtime
В фабрике данных действия определяют выполняемые операции. Связанная служба обозначает целевое хранилище данных или службу вычислений. Среда выполнения интеграции соединяет между собой действия и связанные службы. На нее ссылаются связанные с ней службы или действия, а кроме того она предоставляет вычислительную среду, в которой действие выполняется или из которой оно диспетчеризируется. Такая схема позволяет выполнять действия в регионе, который максимально близко расположен к целевому хранилищу данных или службе вычислений, обеспечивает высокую производительность и соблюдение требований по безопасности и соответствию.
Триггеры
Триггеры обозначают единицу обработки, которая определяет время запуска для выполнения конвейера. Существует несколько типов триггеров для разных событий.
Запуски конвейера
Запуск конвейера — это экземпляр выполнения конвейера. Запуск конвейера обычно создается путем передачи аргументов для параметров, определенных в конвейерах. Аргументы можно передавать вручную или в определении триггера.
Параметры
Параметры представляют собой пары "ключ — значение" в конфигурации только для чтения. Параметры определяются в конвейере, а аргументы для них передаются во время выполнения из контекста запуска, созданного триггером, или из конвейера, который выполняется вручную. Действия в конвейере используют значения параметров.
Набор данных — это строго типизированный параметр и сущность, доступная для ссылок и повторного использования. Действие может ссылаться на наборы данных и может использовать параметры, определенные в определении набора данных.
Связанная служба также является строго типизированным параметром, который содержит сведения о подключении к хранилищу данных или среде вычислений. Служба также доступна для ссылок и (или) повторного использования.
Поток управления
Поток управления — это оркестрация действий в конвейере, которая включает связывание действий в последовательности, ветвление, определение параметров на уровне конвейера и передачу аргументов во время вызова конвейера по запросу или из триггера. Кроме того, сюда входит передача пользовательского состояния и контейнеров зацикливания (то есть итераторы For-each).
Переменные
Переменные можно использовать внутри конвейеров для хранения временных значений, а также в сочетании с параметрами для передачи значений между конвейерами, потоками данных и другими действиями.
Связанный контент
Вот несколько важных документов, которые следует изучить на следующем этапе:
- Datasets and linked services in Azure Data Factory (Наборы данных и связанные службы в фабрике данных Azure)
- Конвейеры и действия
- Среда выполнения интеграции в фабрике данных Azure
- Потоки сопоставления данных
- Пользовательский интерфейс фабрики данных на портале Azure
- Средство копирования данных на портале Azure
- PowerShell
- .NET
- Python
- REST
- Шаблон Azure Resource Manager