Обзор и настройка единиц потоковой передачи в Stream Analytics
Общие сведения об единице потоковой передачи и узле потоковой передачи
Единицы потоковой передачи представляют вычислительные ресурсы, выделяемые для выполнения задания Stream Analytics. Чем больше число единиц потоковой передачи, тем больше выделяются дополнительные ресурсы ЦП и памяти для задания. Эта способность позволяет сосредоточиться на логике запросов и устраняет необходимость управления оборудованием для своевременного выполнения задания Stream Analytics.
Azure Stream Analytics поддерживает две структуры единиц потоковой передачи: SU V1 (не рекомендуется) и SU V2 (рекомендуется).
Модель SU V1 — это исходное предложение ASA, где каждые 6 единиц SUS соответствуют одному узлу потоковой передачи для задания. Задания могут выполняться с 1 и 3 единицами SUS и соответствующими дробным узлам потоковой передачи. Масштабирование выполняется на шаге от 6 до 6 заданий SU, до 12, 18, 24 и более, добавив дополнительные узлы потоковой передачи, которые предоставляют распределенные вычислительные ресурсы.
Модель SU версии 2 (рекомендуется) — это упрощенная структура с благоприятными ценами на те же вычислительные ресурсы. В модели SU V2 1 SU V2 соответствует одному узлу потоковой передачи для задания. 2 SU V2s соответствуют 2, 3–3 и т. д. Задания с 1/3 и 2/3 SU V2 также доступны с одним узлом потоковой передачи, но доля вычислительных ресурсов. Задания 1/3 и 2/3 SU V2 предоставляют экономичный вариант для рабочих нагрузок, требующих меньшего масштаба.
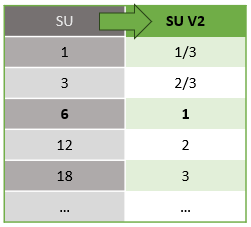
Базовая вычислительная мощность для единиц потоковой передачи V1 и V2 выглядит следующим образом:
Дополнительные сведения о ценах на SU см. на странице цен Azure Stream Analytics.
Общие сведения о преобразованиях единиц потоковой передачи и их применении
Существует автоматическое преобразование единиц потоковой передачи, которое происходит из слоя REST API в пользовательский интерфейс (портал Azure и Visual Studio Code). Вы заметите это преобразование в журнале действий, а также где значения SU отображаются по-разному, чем значения в пользовательском интерфейсе. Это связано с проектированием и причиной этого является то, что поля REST API ограничены целыми значениями, а задания ASA поддерживают дробные узлы (1/3 и 2/3 единиц потоковой передачи). Пользовательский интерфейс ASA отображает значения узлов 1/3, 2/3, 1, 2, 3, ... и т. д., в то время как серверная часть (журналы действий, уровень REST API) отображает те же значения, умноженные на 10, 30, 30, соответственно.
| Стандартные | Стандартная версия 2 (пользовательский интерфейс) | Стандартная версия 2 (серверная часть, например журналы, REST API и т. д.) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
Это позволяет передавать ту же степень детализации и устранять десятичную точку на уровне API для SKU версии 2. Это преобразование автоматически и не влияет на производительность задания.
Общие сведения об использовании потребления и памяти
Для обеспечения потоковой обработки с низкой задержкой все процессы Azure Stream Analytics происходят во временной памяти. При нехватке памяти выполнение потокового задания завершается с ошибкой. Поэтому для рабочего задания важно контролировать использование ресурсов задания потоковой передачи и следить за тем, чтобы было выделено достаточное количество ресурсов для непрерывного выполнения заданий в режиме 24/7.
Показатель использования единиц потоковой передачи (%), который колеблется от 0 до 100 %, описывает потребление памяти рабочей нагрузки. Для потокового задания с минимальным объемом памяти использование единиц потоковой передачи обычно составляет от 10 до 20 %. Если использование SU% высоко (выше 80%) или если события ввода не будут отложены (даже при низком использовании SU% так как он не показывает использование ЦП), то для рабочей нагрузки, скорее всего, требуется больше вычислительных ресурсов, что требует увеличения количества единиц потоковой передачи. Учитывая случайные всплески, лучше поддерживать показатель единиц потоковой передачи ниже 80 %. Чтобы своевременно реагировать на повышение объема рабочих нагрузок увеличением количества единиц потоковой передачи, настройте оповещение при значении 80 % для метрики потребления единиц потоковой передачи. Кроме того, вы можете использовать метрики предельной задержки и событий невыполненной работы, чтобы проверить влияние изменений.
Настройка единиц потоковой передачи Stream Analytics
Войдите на портал Azure.
В списке ресурсов найдите задание Stream Analytics для масштабирования и откройте его.
На странице задания под заголовком Настройка выберите Масштаб. Число единиц SUS по умолчанию равно 1 при создании задания.
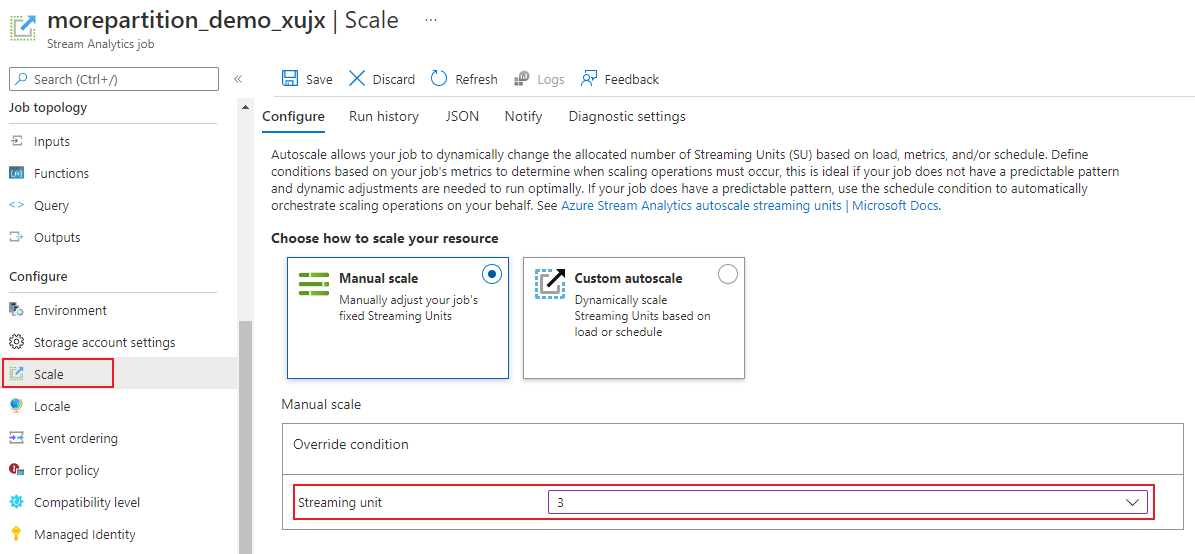
В раскрывающемся списке выберите параметр единиц потоковой передачи, чтобы задать единицы потоковой передачи задания. Обратите внимание, что вы ограничены определенным диапазоном SU.
Вы можете изменить количество единиц SUS, назначенных заданию во время его выполнения. Вы можете выбрать из набора значений SU при выполнении задания, если задание использует несекционированные выходные данные. Или имеет многофакторный запрос с различными значениями PARTITION BY.
Мониторинг производительности задания
На портале Azure можно отслеживать связанные с производительностью метрики задания. Дополнительные сведения об определении метрик см. в статье Метрики заданий Azure Stream Analytics. Дополнительные сведения о мониторинге метрик на портале см. в статье Мониторинг заданий Stream Analytics с помощью портала Azure.
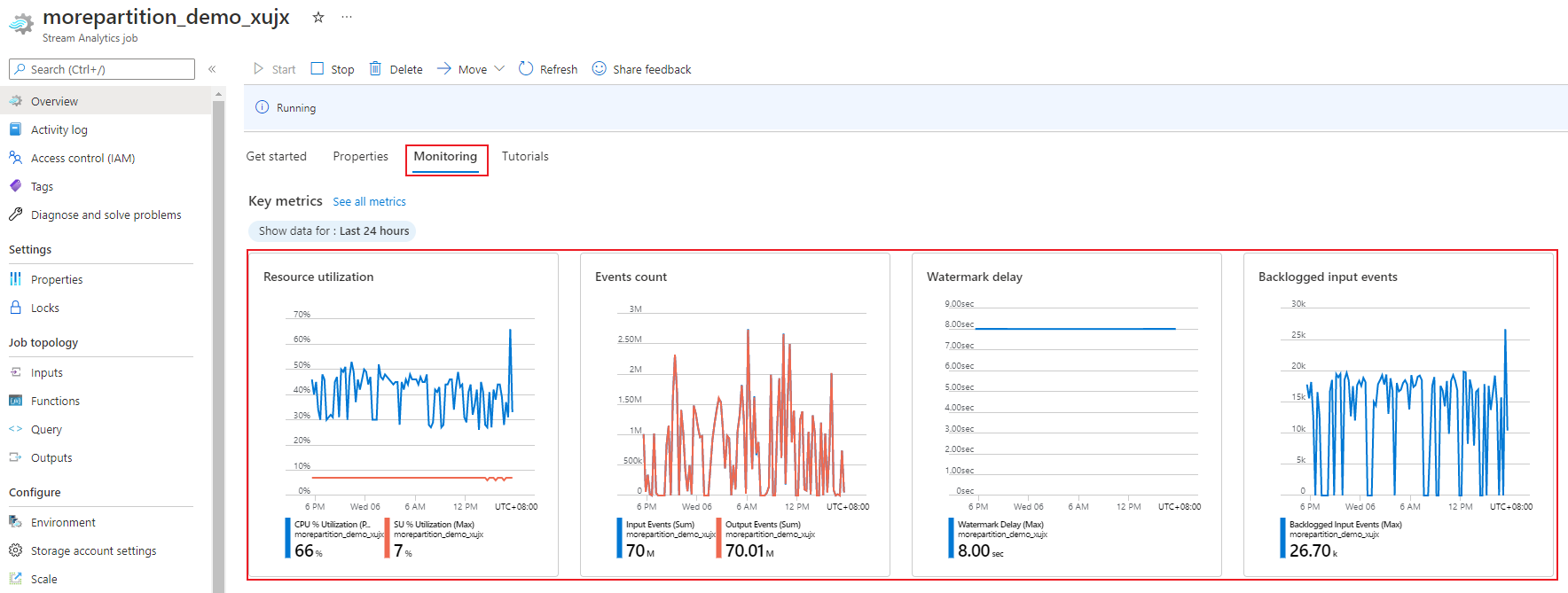
Рассчитайте ожидаемую пропускную способность рабочей нагрузки. Если пропускная способность меньше, чем ожидалось, настройте входную секцию и запрос, а также добавьте в задание дополнительные единицы потоковой передачи.
Сколько единиц потоковой передачи требуется для задания?
Выбор числа единиц потоковой передачи, требуемых для конкретного задания, зависит от конфигурации входных данных и запроса, определенного в задании. В колонке Масштаб можно задать требуемое число единиц потоковой передачи. Рекомендуется выделять больше единиц потоковой передачи, чем требуется. Модуль обработки Stream Analytics оптимизирует задержки и пропускную способность за счет выделения дополнительной памяти.
Как правило, рекомендуется начать с 1 SU V2 для запросов, которые не используют PARTITION BY. Затем определите "золотую середину", используя метод проб и ошибок, при котором вы изменяете число единиц потоковой передачи после передачи репрезентативного объема данных и просмотра метрики процента использования единицы потоковой передачи. Максимальное количество единиц потоковой передачи, которое может использовать задание Stream Analytics, зависит от количества шагов в запросе, определенном для задания и количества разделов на каждом шаге. Дополнительные сведения об ограничениях см. здесь.
Дополнительные сведения о выборе нужного количества единиц SUS см. на этой странице: масштабирование заданий Azure Stream Analytics для повышения пропускной способности.
Примечание.
Выбор необходимого количества единиц потоковой передачи для конкретного задания зависит от конфигурации секции для входных данных и запроса, определенного для задания. Вы можете выбрать для задания количество единиц потоковой передачи согласно указанной квоте. Сведения о квоте подписки Azure Stream Analytics см . в ограничениях Stream Analytics. Чтобы увеличить количество единиц потоковой передачи для своей подписки, свяжитесь со службой технической поддержки Майкрософт. Допустимые значения для единиц SUS для каждого задания: 1/3, 2/3, 1, 2, 3 и т. д.
Факторы, повышающие процент использования единиц потоковой передачи
Элементы темпорального запроса (ориентированные на время) являются основным набором операторов с отслеживанием состояния, которые предоставляет Stream Analytics. Stream Analytics контролирует состояние этих операций изнутри от имени пользователя, управляя уровнем потребления памяти, контрольными точками для обеспечения устойчивости и восстановлением состояния во время обновления. Несмотря на то что Stream Analytics полностью управляет состоянием, существует целый ряд рекомендаций, которые следует учитывать пользователям.
Обратите внимание на то, что задание со сложной логикой запроса может иметь высокий процент использования единиц потоковой передачи даже в том случае, если оно не получает входные события на постоянной основе. Это может произойти после внезапного пика в событиях ввода-вывода. При сложном запросе задание может продолжать хранить состояние в памяти.
Использование единиц хранения может внезапно упасть до 0 в течение короткого периода времени, прежде чем ожидаемый уровень будет восстановлен. Это происходит из-за временных ошибок или системных обновлений. Увеличение числа единиц потоковой передачи для задания может не снизить показатель потребления единиц потоковой передачи, если используется не полностью параллельный запрос.
Для сравнения потребления в разные периоды времени используйте метрики частоты событий. Метрики InputEvents и OutputEvents показывают, сколько событий было прочитано и обработано. Также есть метрики, указывающие количество событий ошибок, например ошибок десериализации. При увеличении числа событий на единицу времени в большинстве случаев повышается и процент потребления единиц потоковой передачи.
Логика запроса с отслеживанием состояния во временных элементах
Одной из уникальных возможностей задания Azure Stream Analytics является выполнение обработки с учетом состояния, например агрегаты данных на основе периодов, темпоральные соединения и темпоральные аналитические функции. Каждый из этих операторов сохраняет сведения о состоянии. Максимальный период времени для этих элементов запроса составляет семь дней.
Концепция временного окна представлена в следующих элементах запросов Stream Analytics.
Агрегаты данных на основе периодов (оператор группирования GROUP BY по "переворачивающимся", "прыгающим" и "скользящим" окнам).
Темпоральные соединения: функция JOIN с DATEDIFF.
Темпоральные аналитические функции: ISFIRST, LAST и LAG с LIMIT DURATION.
Следующие факторы влияют на объем памяти (элемент метрики единиц потоковой передачи), потребляемый заданиями Stream Analytics.
Агрегаты данных на основе периодов
Объем потребляемой памяти (размер состояния) для агрегата данных на основе периодов не всегда прямо пропорционален периоду. На самом деле, потребляемая память пропорциональна кратности данных или количеству групп в каждом периоде.
Например, в следующем запросе число, связанное с clusterid, является кратностью запроса.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
Для устранения проблем, вызванных высокой кратностью в предыдущем запросе, можно отправить события с разбивкой по clusterid в Центры событий и горизонтально увеличить масштаб запроса, позволив системе обрабатывать каждый входной раздел по отдельности, используя ключевое слово PARTITION BY, как показано в следующем примере:
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
Секционированный запрос распределяется между несколькими узлами. В результате число значений clusterid, попадающих в каждый узел, уменьшается, тем самым уменьшая кратность группы по оператору.
Секции Центров событий должны быть разделены с помощью ключа группирования, чтобы вам не нужно было выполнять шаг по уменьшению. Дополнительные сведения см. в статье Что такое Центры событий?
Временные соединения
Потребляемая память (размер состояния) для темпорального соединения пропорциональна количеству событий в области темпорального колебания соединения, которое представляет собой частоту входных событий, умноженную на размер области колебания. Другими словами, память, потребляемая соединением, пропорциональна диапазону времени DateDiff, умноженному на среднюю частоту событий.
Число несопоставленных событий в соединении влияет на использование памяти для выполнения запроса. Следующий запрос ищет просмотры рекламы, которые привели к переходам:
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
Например, возможно, рекламу просмотрело множество людей, но только некоторые щелкнули ее. При этом все события требуется хранить в рамках временного окна. Объем используемой памяти пропорционален размеру окна и частоте событий.
Чтобы исправить эту ошибку, отправьте в Центры событий события с секционированием по ключам соединения (в этом случае по id) и горизонтально увеличьте масштаб запроса, разрешив системе обрабатывать каждый входной раздел отдельно, используя PARTITION BY, как показано ниже:
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
Секционированный запрос распределяется между несколькими узлами. В результате уменьшается не только число событий, поступающих на каждый узел, но и размер состояния, сохраненного в окне соединения.
Темпоральные аналитические функции
Потребляемая память (размер состояния) темпоральной аналитической функции пропорциональна частоте событий, умноженной на длительность. Память, потребляемая аналитическими функциями, не пропорциональна периоду, но пропорциональна количеству секций в каждом периоде времени.
Решение аналогично решению для темпорального соединения. Вы можете горизонтально увеличить масштаб запроса, используя PARTITION BY.
Буфер вне порядка
Пользователь может настроить размер неупорядоченного буфера на панели конфигурации упорядочения событий. Буфер используется для хранения входных данных в течение определенного периода и изменения их порядка. Размер буфера пропорционален частоте ввода событий, умноженной на размер неупорядоченного окна. Размер окна по умолчанию равен 0.
Для устранения переполнения неупорядоченного буфера нужно горизонтально увеличить масштаб запроса с помощью ключевого слова PARTITION BY. Секционированный запрос распределяется между несколькими узлами. В результате уменьшается не только число событий, поступающих на каждый узел, но и количество событий в каждом упорядоченном буфере.
Количество входных секций
Для каждого входящего раздела входных данных задания предусмотрен буфер. Чем больше количество входных разделов, тем больше ресурсов потребляет задание. Для каждой единицы потоковой передачи Azure Stream Analytics может обрабатывать примерно 7 МБ/с входных данных. Таким образом можно выполнить оптимизацию, сопоставив число единиц потоковой передачи Stream Analytics с числом секций в концентраторе событий.
Как правило, задание, настроенное с единицей потоковой передачи 1/3, достаточно для концентратора событий с двумя секциями (что является минимальным для концентратора событий). Если концентратор событий содержит большее число секций, задание Stream Analytics потребляет больше ресурсов, но не всегда использует дополнительную пропускную способность, предоставляемую Центрами событий.
Для задания с 1 единицей потоковой передачи версии 2 может потребоваться 4 или 8 секций из концентратора событий. Однако избегайте создания слишком большого количества ненужных разделов, так как это приводит к чрезмерному использованию ресурсов. Например, концентратор событий с 16 секциями (и больше) в задании Stream Analytics с 1 единицей потоковой передачи.
Справочные данные
Ссылочные данные в ASA загружаются в память для быстрого поиска. В текущей реализации для каждой операции соединения со ссылочными данными их копия сохраняется в памяти даже при соединении с использованием одних ссылочных данных несколько раз. Для запросов, содержащих PARTITION BY, каждый раздел имеет копию ссылочных данных, поэтому разделы полностью разделены. Если вы несколько раз присоединяетесь к ссылочным данным с несколькими разделами, то из-за эффекта увеличения использование памяти может быстро вырасти.
Использование определяемых пользователем функций
При добавлении определяемой пользователем функции Azure Stream Analytics загружает в память среду выполнения JavaScript. Это влияет на процент единиц потоковой передачи.
Следующие шаги
- Leverage query parallelization in Azure Stream Analytics (Использование параллелизации запросов в Azure Stream Analytics)
- Масштабирование заданий Azure Stream Analytics для повышения пропускной способности базы данных
- Метрики заданий Azure Stream Analytics
- Измерения метрик Azure Stream Analytics
- Мониторинг заданий Stream Analytics с помощью портала Azure
- Анализ производительности заданий Stream Analytics с помощью измерений метрик
- Обзор и настройка единиц потоковой передачи