Ескертпе
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Жүйеге кіруді немесе каталогтарды өзгертуді байқап көруге болады.
Бұл бетке кіру үшін қатынас шегін айқындау қажет. Каталогтарды өзгертуді байқап көруге болады.
Применимо к:✅ Fabric инженерии данных и науке о данных
Узнайте, как отправлять задания для сеансов Spark, используя API Livy для инженерии данных в Fabric.
Предварительные условия
Fabric Premium или пробная емкость с Lakehouse
Удаленный клиент, например Visual Studio Code с Jupyter Notebooks, PySpark и Microsoft Authentication Library (MSAL) для Python
Либо токен приложения Microsoft Entra. Зарегистрировать приложение в платформе идентификации Microsoft
Или SPN токен Microsoft Entra. Добавьте и управляйте учетными данными приложения в системе Microsoft Entra
Некоторые данные в озере данных, в этом примере используется Комиссия по такси и лимузинам Нью-Йорка parquet файл green_tripdata_2022_08, загруженный в озеро данных.
API Livy определяет единую конечную точку для операций. Замените заполнители {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID}, {Fabric_LakehouseID} соответствующими значениями при выполнении примеров в этой статье.
Настройка Visual Studio Code для сеанса API Livy
Выберите Lakehouse Settings в Fabric Lakehouse.

Перейдите к разделу конечной точки Livy.

Скопируйте строку подключения задачи сеанса (первое красное место на изображении) в ваш код.
Перейдите к Microsoft Entra admin center и скопируйте идентификатор приложения (клиента) и идентификатор каталога (клиента) в код.
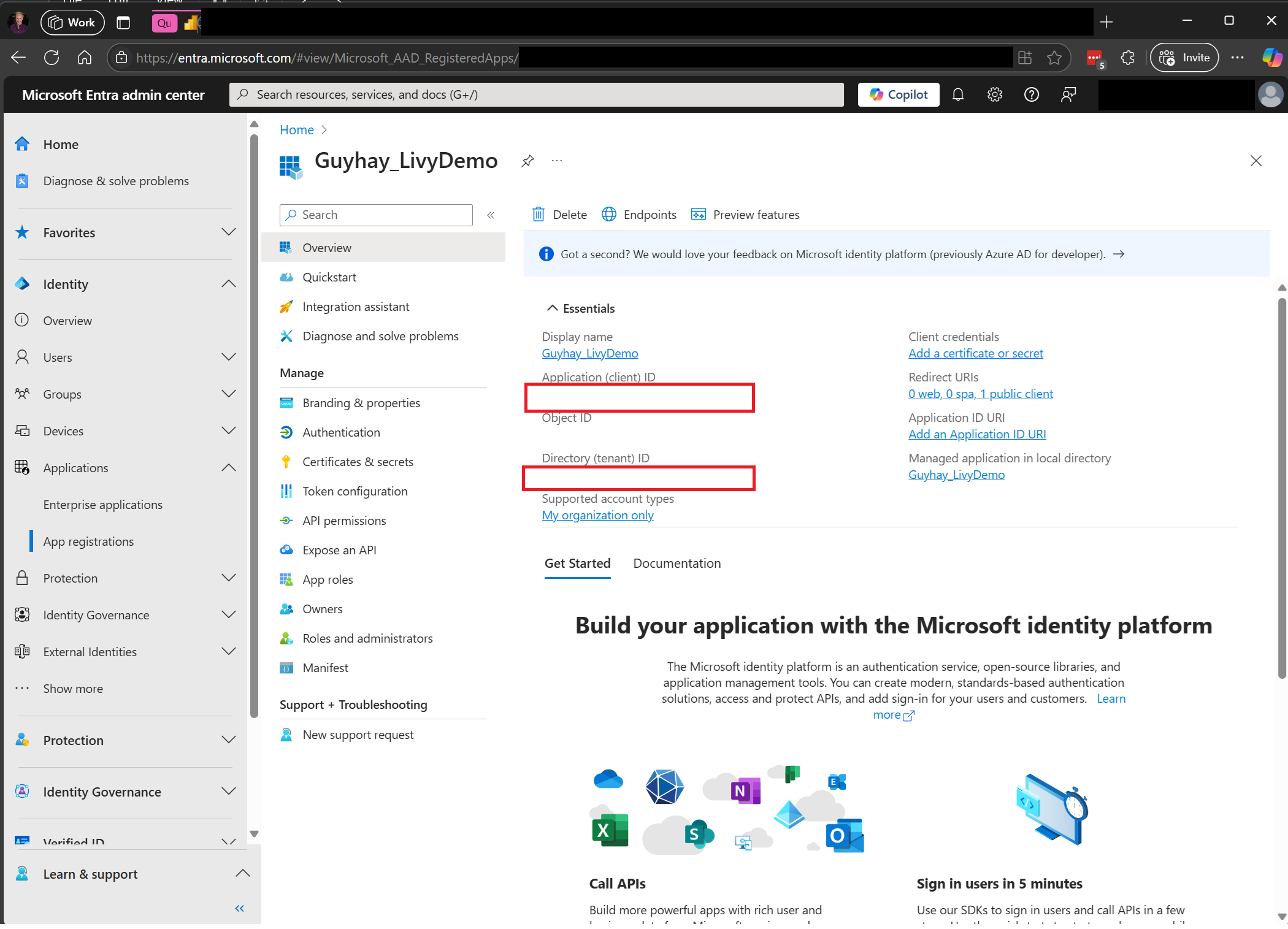



Аутентификация сеанса Livy API Spark с помощью токена пользователя Microsoft Entra или токена учетной записи службы Microsoft Entra
Проверка подлинности сеанса Spark API Livy при помощи токена SPN Microsoft Entra
Создайте записную книжку
.ipynbв Visual Studio Code и вставьте следующий код.import sys from msal import ConfidentialClientApplication # Configuration - Replace with your actual values tenant_id = "Entra_TenantID" # Microsoft Entra tenant ID client_id = "Entra_ClientID" # Service Principal Application ID # Certificate paths - Update these paths to your certificate files certificate_path = "PATH_TO_YOUR_CERTIFICATE.pem" # Public certificate file private_key_path = "PATH_TO_YOUR_PRIVATE_KEY.pem" # Private key file certificate_thumbprint = "YOUR_CERTIFICATE_THUMBPRINT" # Certificate thumbprint # OAuth settings audience = "https://analysis.windows.net/powerbi/api/.default" authority = f"https://login.windows.net/{tenant_id}" def get_access_token(client_id, audience, authority, certificate_path, private_key_path, certificate_thumbprint=None): """ Get an app-only access token for a Service Principal using OAuth 2.0 client credentials flow. This function uses certificate-based authentication which is more secure than client secrets. Args: client_id (str): The Service Principal's client ID audience (str): The audience for the token (resource scope) authority (str): The OAuth authority URL certificate_path (str): Path to the certificate file (.pem format) private_key_path (str): Path to the private key file (.pem format) certificate_thumbprint (str): Certificate thumbprint (optional but recommended) Returns: str: The access token for API authentication Raises: Exception: If token acquisition fails """ try: # Read the certificate from PEM file with open(certificate_path, "r", encoding="utf-8") as f: certificate_pem = f.read() # Read the private key from PEM file with open(private_key_path, "r", encoding="utf-8") as f: private_key_pem = f.read() # Create the confidential client application app = ConfidentialClientApplication( client_id=client_id, authority=authority, client_credential={ "private_key": private_key_pem, "thumbprint": certificate_thumbprint, "certificate": certificate_pem } ) # Acquire token using client credentials flow token_response = app.acquire_token_for_client(scopes=[audience]) if "access_token" in token_response: print("Successfully acquired access token") return token_response["access_token"] else: raise Exception(f"Failed to retrieve token: {token_response.get('error_description', 'Unknown error')}") except FileNotFoundError as e: print(f"Certificate file not found: {e}") sys.exit(1) except Exception as e: print(f"Error retrieving token: {e}", file=sys.stderr) sys.exit(1) # Get the access token token = get_access_token(client_id, audience, authority, certificate_path, private_key_path, certificate_thumbprint)Запустите ячейку записной книжки. Вы должны увидеть возвращённый токен Microsoft Entra.


Аутентификация сеанса Spark API Livy с использованием токена пользователя Microsoft Entra
Создайте записную книжку
.ipynbв Visual Studio Code и вставьте следующий код.from msal import PublicClientApplication import requests import time # Configuration - Replace with your actual values tenant_id = "Entra_TenantID" # Microsoft Entra tenant ID client_id = "Entra_ClientID" # Application ID (can be the same as above or different) # Required scopes for Livy API access scopes = [ "https://api.fabric.microsoft.com/Lakehouse.Execute.All", # Required — execute operations in lakehouses "https://api.fabric.microsoft.com/Lakehouse.Read.All", # Required — read lakehouse metadata "https://api.fabric.microsoft.com/Code.AccessFabric.All", # Required — general Fabric API access from Spark Runtime "https://api.fabric.microsoft.com/Code.AccessStorage.All", # Required — access OneLake and Azure storage from Spark Runtime ] # Optional scopes — add these only if your Spark jobs need access to the corresponding services: # "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All" # Optional — access Azure Key Vault from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All" # Optional — access Azure Data Lake Storage Gen1 from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All" # Optional — access Azure Data Explorer from Spark Runtime # "https://api.fabric.microsoft.com/Code.AccessSQL.All" # Optional — access Azure SQL audience tokens from Spark Runtime def get_access_token(tenant_id, client_id, scopes): """ Get an access token using interactive authentication. This method will open a browser window for user authentication. Args: tenant_id (str): The Microsoft Entra tenant ID client_id (str): The application client ID scopes (list): List of required permission scopes Returns: str: The access token, or None if authentication fails """ app = PublicClientApplication( client_id, authority=f"https://login.microsoftonline.com/{tenant_id}" ) print("Opening browser for interactive authentication...") token_response = app.acquire_token_interactive(scopes=scopes) if "access_token" in token_response: print("Successfully authenticated") return token_response["access_token"] else: print(f"Authentication failed: {token_response.get('error_description', 'Unknown error')}") return None # Uncomment the lines below to use interactive authentication token = get_access_token(tenant_id, client_id, scopes) print("Access token acquired via interactive login")Запустите ячейку записной книжки. Вы должны увидеть возвращённый токен Microsoft Entra.

Общие сведения о областях Code.* для API Livy
Когда задания Spark выполняются через API Livy, Code.* границы управляют доступом к внешним службам среды выполнения Spark от имени аутентифицированного пользователя. Необходимо два, остальные зависят от вашей рабочей нагрузки.
Области обязательного кода.*
| Объем | Описание |
|---|---|
Code.AccessFabric.All |
Позволяет получать токены доступа для Microsoft Fabric. Требуется для всех операций API Livy. |
Code.AccessStorage.All |
Позволяет получать токены доступа к OneLake и хранилищу Azure. Требуется для чтения и записи данных в озерохранилищах. |
Необязательные области Code.*
Добавьте эти области только в том случае, если задания Spark должны получить доступ к соответствующим службам Azure во время выполнения.
| Объем | Описание | Когда использовать |
|---|---|---|
Code.AccessAzureKeyvault.All |
Позволяет получать токены доступа для Azure Key Vault. | Код Spark получает секреты, ключи или сертификаты из Azure Key Vault. |
Code.AccessAzureDataLake.All |
Позволяет получать маркеры доступа для Azure Data Lake Storage Gen1. | Код Spark считывает данные из учетных записей Azure Data Lake Storage Gen1 или записывает в них. |
Code.AccessAzureDataExplorer.All |
Позволяет получать токены доступа для Azure Data Explorer (Kusto). | Код Spark запрашивает или отправляет данные из Azure Data Explorer кластеров. |
Code.AccessSQL.All |
Позволяет получать маркеры доступа для Azure SQL. | Код Spark должен подключаться к базам данных Azure SQL. |
Замечание
Области Lakehouse.Execute.All и Lakehouse.Read.All также необходимы, но не являются частью группы Code.*. Они предоставляют разрешение на выполнение операций и чтение метаданных из Fabric lakehouses соответственно.
Создание сеанса Livy API Spark
Подсказка
Если для вашей рабочей нагрузки требуется одновременно выполнять несколько инструкций Spark, рекомендуется использовать сеансы высокой параллельности. Сеансы HC предоставляют независимые контексты выполнения, которые выполняются параллельно, в то время как система управляет повторным использованием основных сеансов Livy.
Добавьте еще одну ячейку записной книжки и вставьте этот код.
import json import requests api_base_url = "https://api.fabric.microsoft.com/" # Base URL for Fabric APIs # Fabric Resource IDs - Replace with your workspace and lakehouse IDs workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" # Construct the Livy API session URL # URL pattern: {base_url}/v1/workspaces/{workspace_id}/lakehouses/{lakehouse_id}/livyapi/versions/{api_version}/sessions livy_api_session_url = (f"{api_base_url}v1/workspaces/{workspace_id}/lakehouses/{lakehouse_id}/" f"livyapi/versions/2023-12-01/sessions") # Set up authentication headers headers = {"Authorization": f"Bearer {token}"} print(f"Livy API URL: {livy_api_session_url}") print("Creating Livy session...") try: # Create a new Livy session with default configuration create_livy_session = requests.post(livy_api_session_url, headers=headers, json={}) # Check if the request was successful if create_livy_session.status_code == 202: session_info = create_livy_session.json() print('Livy session creation request submitted successfully') print(f'Session Info: {json.dumps(session_info, indent=2)}') # Extract session ID for future operations livy_session_id = session_info['id'] livy_session_url = f"{livy_api_session_url}/{livy_session_id}" print(f"Session ID: {livy_session_id}") print(f"Session URL: {livy_session_url}") else: print(f"Failed to create session. Status code: {create_livy_session.status_code}") print(f"Response: {create_livy_session.text}") except requests.exceptions.RequestException as e: print(f"Network error occurred: {e}") except json.JSONDecodeError as e: print(f"JSON decode error: {e}") print(f"Response text: {create_livy_session.text}") except Exception as e: print(f"Unexpected error: {e}")Запустите ячейку записной книжки, вы увидите одну строку, напечатанную при создании сеанса Livy.

Вы можете убедиться, что сеанс Livy создан, используя [просмотр ваших заданий в узле мониторинга](#View-your-jobs-in-the-Monitoring-hub).

Интеграция с средами Fabric
По умолчанию этот сеанс API Livy выполняется в стандартном начальном пуле рабочей области. Кроме того, можно использовать среды Fabric Create, настроить и использовать среду в Microsoft Fabric для настройки пула Spark, используемого сеансом API Livy для этих заданий Spark. Чтобы использовать среду Fabric, обновите предыдущую ячейку записной книжки с помощью этого JSON-пейлоада.
create_livy_session = requests.post(livy_base_url, headers = headers, json = {
"conf" : {
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID""}"}
}
)
Отправка инструкции spark.sql с помощью сеанса Spark API Livy
Добавьте еще одну ячейку записной книжки и вставьте этот код.
# call get session API import time table_name = "green_tripdata_2022" print("Checking session status...") # Get current session status get_session_response = requests.get(livy_session_url, headers=headers) session_status = get_session_response.json() print(f"Current session state: {session_status['state']}") # Wait for session to become idle (ready to accept statements) print("Waiting for session to become idle...") while session_status["state"] != "idle": print(f" Session state: {session_status['state']} - waiting 5 seconds...") time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) session_status = get_session_response.json() print("Session is now idle and ready to accept statements") # Execute a Spark SQL statement execute_statement_url = f"{livy_session_url}/statements" # Define your Spark SQL query - Replace with your actual table and query payload_data = { "code": "spark.sql(\"SELECT * FROM {table_name} WHERE column_name = 'some_value' LIMIT 10\").show()", "kind": "spark" # Type of code (spark, pyspark, sql, etc.) } print("Submitting Spark SQL statement...") print(f"Query: {payload_data['code']}") try: # Submit the statement for execution execute_statement_response = requests.post(execute_statement_url, headers=headers, json=payload_data) if execute_statement_response.status_code == 200: statement_info = execute_statement_response.json() print('Statement submitted successfully') print(f"Statement Info: {json.dumps(statement_info, indent=2)}") # Get statement ID for monitoring statement_id = str(statement_info['id']) get_statement_url = f"{livy_session_url}/statements/{statement_id}" print(f"Statement ID: {statement_id}") # Monitor statement execution print("Monitoring statement execution...") get_statement_response = requests.get(get_statement_url, headers=headers) statement_status = get_statement_response.json() while statement_status["state"] != "available": print(f" Statement state: {statement_status['state']} - waiting 5 seconds...") time.sleep(5) get_statement_response = requests.get(get_statement_url, headers=headers) statement_status = get_statement_response.json() # Retrieve and display results print("Statement execution completed!") if 'output' in statement_status and 'data' in statement_status['output']: results = statement_status['output']['data']['text/plain'] print("Query Results:") print(results) else: print("No output data available") else: print(f"Failed to submit statement. Status code: {execute_statement_response.status_code}") print(f"Response: {execute_statement_response.text}") except Exception as e: print(f"Error executing statement: {e}")Запустите ячейку записной книжки, вы увидите несколько добавочных строк, напечатанных по мере отправки задания и возвращаемых результатов.
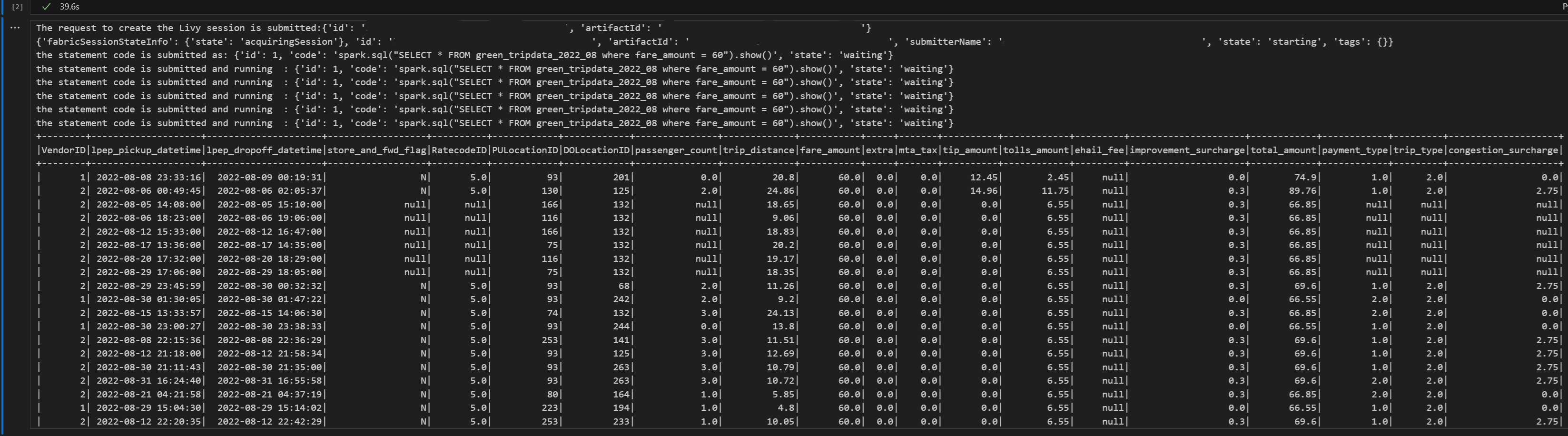

Отправка второй инструкции spark.sql с помощью сеанса Spark API Livy
Добавьте еще одну ячейку записной книжки и вставьте этот код.
print("Executing additional Spark SQL statement...") # Wait for session to be idle again get_session_response = requests.get(livy_session_url, headers=headers) session_status = get_session_response.json() while session_status["state"] != "idle": print(f" Waiting for session to be idle... Current state: {session_status['state']}") time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) session_status = get_session_response.json() # Execute another statement - Replace with your actual query payload_data = { "code": f"spark.sql(\"SELECT COUNT(*) as total_records FROM {table_name}\").show()", "kind": "spark" } print(f"Executing query: {payload_data['code']}") try: # Submit the second statement execute_statement_response = requests.post(execute_statement_url, headers=headers, json=payload_data) if execute_statement_response.status_code == 200: statement_info = execute_statement_response.json() print('Second statement submitted successfully') statement_id = str(statement_info['id']) get_statement_url = f"{livy_session_url}/statements/{statement_id}" # Monitor execution print("Monitoring statement execution...") get_statement_response = requests.get(get_statement_url, headers=headers) statement_status = get_statement_response.json() while statement_status["state"] != "available": print(f" Statement state: {statement_status['state']} - waiting 5 seconds...") time.sleep(5) get_statement_response = requests.get(get_statement_url, headers=headers) statement_status = get_statement_response.json() # Display results print("Second statement execution completed!") if 'output' in statement_status and 'data' in statement_status['output']: results = statement_status['output']['data']['text/plain'] print("Query Results:") print(results) else: print("No output data available") else: print(f"Failed to submit second statement. Status code: {execute_statement_response.status_code}") except Exception as e: print(f"Error executing second statement: {e}")Запустите ячейку записной книжки, вы увидите несколько добавочных строк, напечатанных по мере отправки задания и возвращаемых результатов.
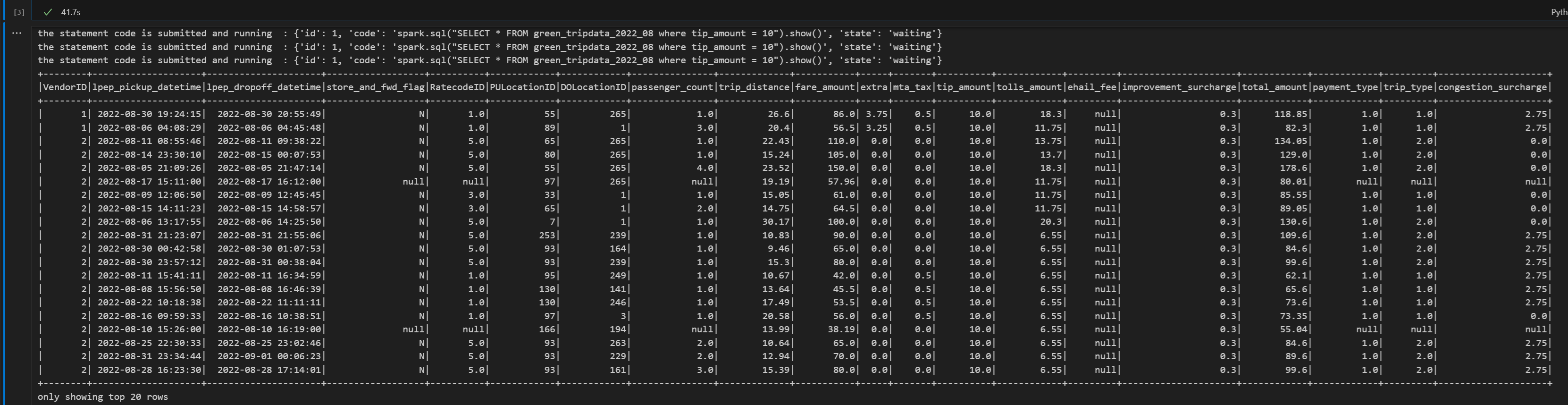

Завершение сеанса Livy
Добавьте еще одну ячейку записной книжки и вставьте этот код.
print("Cleaning up Livy session...") try: # Check current session status before deletion get_session_response = requests.get(livy_session_url, headers=headers) if get_session_response.status_code == 200: session_info = get_session_response.json() print(f"Session state before deletion: {session_info.get('state', 'unknown')}") print(f"Deleting session at: {livy_session_url}") # Delete the session delete_response = requests.delete(livy_session_url, headers=headers) if delete_response.status_code == 200: print("Session deleted successfully") elif delete_response.status_code == 404: print("Session was already deleted or not found") else: print(f"Delete request completed with status code: {delete_response.status_code}") print(f"Response: {delete_response.text}") print(f"Delete response details: {delete_response}") except requests.exceptions.RequestException as e: print(f"Network error during session deletion: {e}") except Exception as e: print(f"Error during session cleanup: {e}")
Просмотр заданий в центре мониторинга
Вы можете получить доступ к центру мониторинга для просмотра различных действий Apache Spark, выбрав монитор в левой части ссылок навигации.
Когда сеанс выполняется или находится в состоянии завершения, можно просмотреть состояние сеанса, перейдя к монитору.
Выберите и откройте название последнего действия.
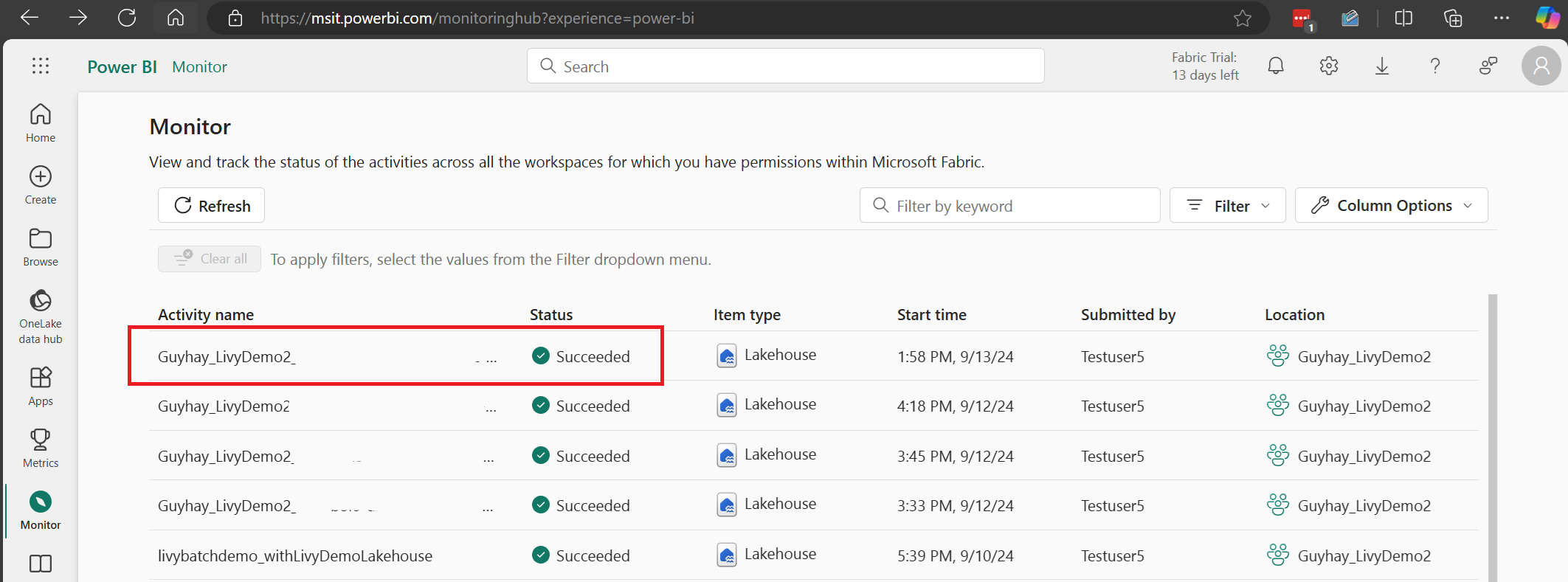
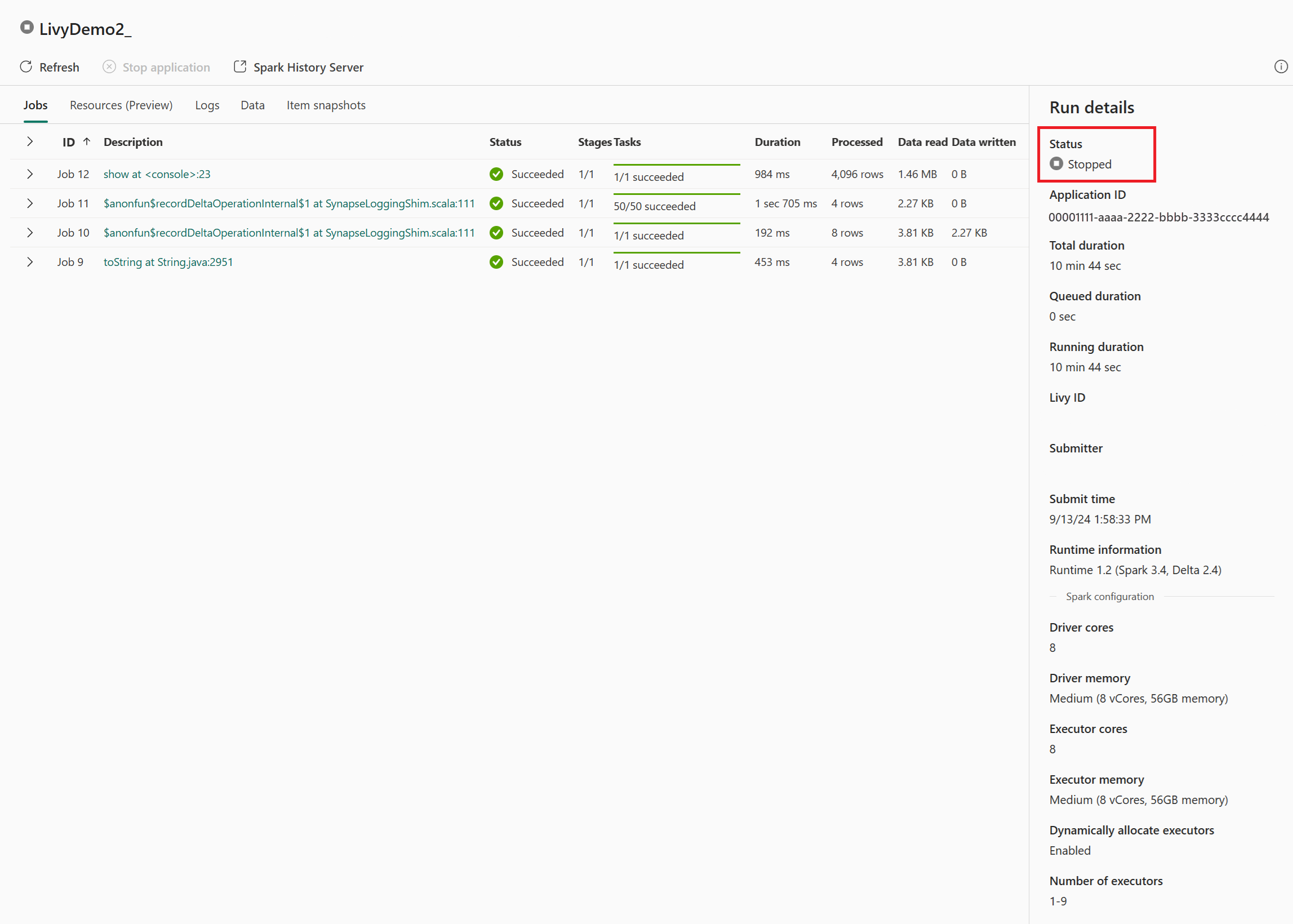
В этой сессии API Livy можно просмотреть предыдущие отправки сеансов, подробности выполнения, версии Spark и конфигурацию. Обратите внимание на остановленное состояние в правом верхнем углу.



Чтобы подытожить весь процесс, вам нужен удаленный клиент, такой как Visual Studio Code, маркер приложения или субъекта-службы Microsoft Entra, URL-адрес конечной точки API Livy, аутентификация в вашей Lakehouse и, наконец, API Livy для сеанса.