Руководство по использованию модели DirectQuery в Power BI Desktop
В этой статье рассматриваются модели данных, разрабатывающие модели Power BI DirectQuery, разработанные с помощью Power BI Desktop или служба Power BI. В нем описываются варианты использования DirectQuery, ограничения и рекомендации. В частности, руководство предназначено для определения того, является ли DirectQuery подходящим режимом для модели, а также для повышения производительности отчетов на основе моделей DirectQuery. Эта статья относится к моделям DirectQuery, размещенным в служба Power BI или Сервер отчетов Power BI.
Эта статья не предназначена для полного обсуждения проектирования модели DirectQuery. Общие сведения см . в статье о моделях DirectQuery в Power BI Desktop . Дополнительные сведения см. в техническом документе DirectQuery в SQL Server 2016 Analysis Services . Помните, что технический документ описывает использование DirectQuery в службах SQL Server Analysis Services. Однако большая часть содержимого по-прежнему применима к моделям Power BI DirectQuery.
Примечание.
Рекомендации по использованию режима хранения DirectQuery для Dataverse см . в руководстве по моделированию Power BI для Power Platform.
Эта статья не охватывает непосредственно составные модели. Составная модель состоит по крайней мере из одного источника DirectQuery и, возможно, больше. Инструкции, описанные в этой статье, по-прежнему актуальны ( по крайней мере в части) для составной модели. Однако последствия объединения таблиц импорта с таблицами DirectQuery не входят в область действия этой статьи. Дополнительные сведения см. в статье "Использование составных моделей в Power BI Desktop".
Важно понимать, что модели DirectQuery накладывают другую рабочую нагрузку в среде Power BI (служба Power BI или Сервер отчетов Power BI), а также базовые источники данных. Если вы определите, что DirectQuery является подходящим подходом к проектированию, рекомендуется привлечь нужных людей в проекте. Часто мы видим, что успешное развертывание модели DirectQuery является результатом совместной работы ит-специалистов. Команда обычно состоит из разработчиков моделей и администраторов исходной базы данных. Он также может включать архитекторов данных, а также хранилища данных и разработчиков ETL. Часто оптимизация должна применяться непосредственно к источнику данных для достижения хороших результатов производительности.
Оптимизация производительности источника данных
Источник реляционной базы данных можно оптимизировать несколькими способами, как описано в следующем маркированном списке.
Примечание.
Мы понимаем, что у всех моделей есть разрешения или навыки оптимизации реляционной базы данных. Хотя это предпочтительный уровень для подготовки данных для модели DirectQuery, некоторые оптимизации также можно достичь в проектировании модели, не изменяя исходную базу данных. Однако лучшие результаты оптимизации часто достигаются путем применения оптимизации к исходной базе данных.
Убедитесь, что целостность данных завершена. Особенно важно, чтобы таблицы измерений содержат столбец уникальных значений (ключ измерения), который сопоставляется с таблицами фактов. Также важно, чтобы столбцы измерения таблицы фактов содержали допустимые значения ключа измерения. Они позволяют настраивать более эффективные связи модели, ожидающие соответствующие значения на обеих сторонах отношений. Если исходные данные не имеют целостности, рекомендуется добавить запись измерения "неизвестного" для эффективного восстановления данных. Например, можно добавить строку в таблицу
Product, чтобы представить неизвестный продукт, а затем назначить его вне диапазонным ключом, например -1. Если строки в таблицеSalesсодержат отсутствующее значение ключа продукта, замените их значением -1. Это гарантирует, что каждое значение ключа продукта таблицыSalesсодержит соответствующую строку в таблицеProduct.Добавление индексов: Определение соответствующих индексов (в таблицах или представлениях) для поддержания эффективного извлечения данных при ожидаемой визуальной фильтрации и группировке отчетов. Для источников SQL Server База данных SQL Azure или Azure Synapse Analytics (прежнее название — хранилище данных SQL) см. руководство по архитектуре индекса SQL Server и руководство по проектированию полезных сведений о руководстве по проектированию индексов. Сведения о sql Server или База данных SQL Azure переменных источников см. в статье "Начало работы с Columnstore" для оперативной аналитики в режиме реального времени.
Проектирование распределенных таблиц. Для источников Azure Synapse Analytics (прежнее название — хранилище данных SQL), которые используют архитектуру массивной параллельной обработки (MPP), рассмотрите возможность настройки больших таблиц фактов в виде хэш-распределенных и таблиц измерений для репликации на всех вычислительных узлах. Дополнительные сведения см. в руководстве по проектированию распределенных таблиц в Azure Synapse Analytics (ранее — хранилище данных SQL).
Убедитесь, что необходимые преобразования данных реализованы. Для источников реляционных баз данных SQL Server (и других реляционных источников данных) можно добавлять вычисляемые столбцы в таблицы. Эти столбцы основаны на выражении, например Количество , умноженное на UnitPrice. Вычисляемые столбцы можно сохранять (материализованные) и, например, обычные столбцы, иногда их можно индексировать. Дополнительные сведения см. в разделе Индексы вычисляемых столбцов.
Рассмотрим также индексированные представления, которые могут предварительно агрегировать данные таблицы фактов на более высоком уровне. Например, если таблица
Salesхранит данные на уровне строки заказа, можно создать представление для сводки этих данных. Представление может основываться на инструкцииSELECT, которая группирует данные таблицыSalesпо дате (на уровне месяца), клиенту, продукту и суммирует значения мер, такие как продажи, количество и т. д. Затем представление можно индексировать. Источники SQL Server или База данных SQL Azure см. в разделе "Создание индексированных представлений".Материализуйте таблицу дат: обычное требование моделирования включает добавление таблицы дат для поддержки фильтрации на основе времени. Чтобы поддерживать известные фильтры на основе времени в организации, создайте таблицу в исходной базе данных и убедитесь, что она загружается с диапазоном дат, охватывающих даты таблицы фактов. Кроме того, он включает столбцы для полезных периодов времени, таких как год, квартал, месяц, неделя и т. д.
Оптимизация проектирования модели
Модель DirectQuery может быть оптимизирована различными способами, как описано в следующем маркированном списке.
Избегайте сложных запросов Power Query. Эффективная модель может быть достигнута путем удаления необходимости применения любых преобразований в запросах Power Query. Это означает, что каждый запрос сопоставляется с одной исходной таблицей или представлением базы данных реляционной базы данных. Вы можете предварительно просмотреть представление фактической инструкции SQL-запроса для примененного шага Power Query, выбрав параметр View Native Query .
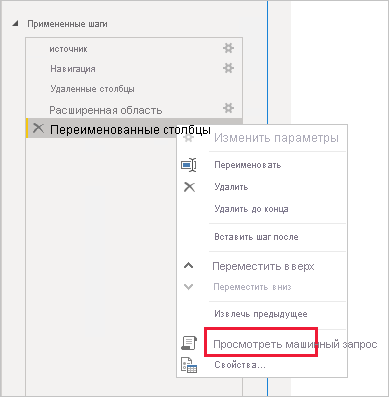
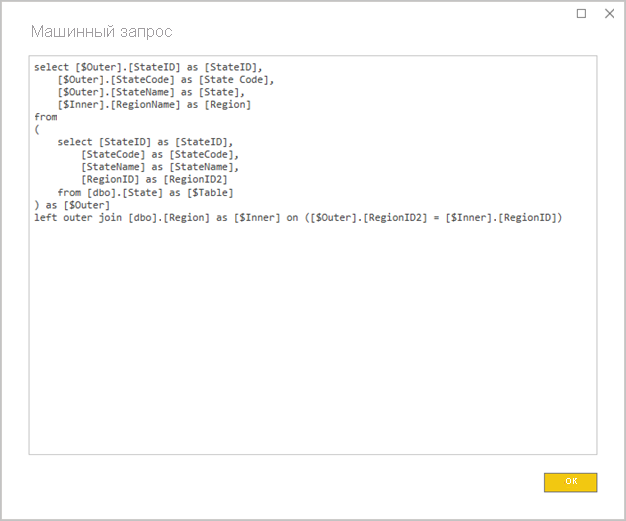
Изучение использования вычисляемых столбцов и изменений типа данных: модели DirectQuery поддерживают добавление вычислений и шагов Power Query для преобразования типов данных. Однако повышение производительности часто достигается путем материализации результатов преобразования в источнике реляционной базы данных, когда это возможно.
Не используйте фильтрацию относительных дат Power Query: можно определить относительную фильтрацию дат в запросе Power Query. Например, чтобы получить заказы на продажу, созданные в прошлом году (относительно сегодняшней даты). Этот тип фильтра преобразуется в неэффективный собственный запрос, как показано ниже.
… from [dbo].[Sales] as [_] where [_].[OrderDate] >= convert(datetime2, '2018-01-01 00:00:00') and [_].[OrderDate] < convert(datetime2, '2019-01-01 00:00:00'))Лучший подход к проектированию — включить относительные столбцы времени в таблицу дат. Эти столбцы хранят значения смещения относительно текущей даты. Например, в столбце
RelativeYearзначение число ноль обозначает текущий год, -1 обозначает предыдущий год и т. д. Предпочтительно, чтобы столбецRelativeYearбыл представлен в таблице дат. В то же время он также может быть добавлен в виде вычисляемого столбца модели на основе выражения с помощью функций TODAY и DATE DAX.Держать меры простыми: по крайней мере первоначально рекомендуется ограничить меры простыми агрегатами. Агрегатные функции включают SUM, COUNT, MIN, MAX и AVERAGE. Затем, если меры достаточно реагируют, можно поэкспериментировать с более сложными мерами, но обратить внимание на производительность для каждого. Хотя функцию CALCULATE DAX можно использовать для создания сложных выражений мер, которые управляют контекстом фильтра, они могут создавать дорогостоящие собственные запросы, которые не выполняются хорошо.
Избегайте связей с вычисляемыми столбцами. Связи модели могут связывать только один столбец в одной таблице с одним столбцом в другой таблице. Однако иногда необходимо связать таблицы с помощью нескольких столбцов. Например, таблицы
SalesиGeographyсвязаны двумя столбцами:CountryRegionиCity. Чтобы создать связь между таблицами, требуется один столбец, а в таблицеGeographyстолбец должен содержать уникальные значения. Объединение страны или региона и города с разделителем дефиса может достичь этого результата.Объединенный столбец можно создать с пользовательским столбцом Power Query или в модели в виде вычисляемого столбца. Однако следует избежать, так как выражение вычисления будет внедрено в исходные запросы. Это не только неэффективно, обычно это предотвращает использование индексов. Вместо этого добавьте материализованные столбцы в источник реляционной базы данных и рассмотрите возможность их индексирования. Вы также можете добавить суррогатные ключевые столбцы в таблицы измерений, что является распространенной практикой в структурах реляционного хранилища данных.
Существует одно исключение из этого руководства, и это касается использования функции COMBINEVALUES DAX. Эта функция предназначена для поддержки связей модели с несколькими столбцами. Вместо того чтобы создать выражение, которое использует связь, он создает предикат соединения SQL с несколькими столбцами.
Избегайте связей в столбцах "Уникальный идентификатор": Power BI не поддерживает собственный тип данных идентификатора (GUID). При определении связи между столбцами этого типа Power BI создает исходный запрос с присоединением, включающим приведение. Это преобразование данных во время запроса обычно приводит к снижению производительности. До оптимизации этого случая единственным решением является материализация столбцов альтернативного типа данных в базовой базе данных.
Скрытие одностороннего столбца связей: односторонний столбец связи должен быть скрыт. (Обычно это основной ключевой столбец таблиц измерений.) При скрытии он недоступен в области данных и поэтому не может использоваться для настройки визуального элемента. Многосторонняя колонка может оставаться видимой, если полезно группировать или фильтровать отчеты по значениям столбцов. Например, рассмотрим модель, в которой существует связь между
SalesиProductтаблицами. Столбцы связей содержат значения SKU продукта (единица хранения запасов). Если номер SKU продукта должен быть добавлен в визуальные элементы, он должен быть виден только в таблицеSales. Если этот столбец используется для фильтрации или группировки в визуальном элементе, Power BI создает запрос, который не требует присоединения кSalesиProductтаблицам.Установить связи для обеспечения целостности: свойство Предполагать целостность ссылок связей DirectQuery определяет, создает ли Power BI исходные запросы с помощью
INNER JOIN, а неOUTER JOIN. Как правило, он улучшает производительность запросов, хотя он зависит от особенностей источника реляционной базы данных. Дополнительные сведения см. в разделе "Предположим, что параметры целостности данных" в Power BI Desktop.Избегайте использования двухнаправленной фильтрации связей. Использование двухнаправленной фильтрации связей может привести к неправильному выполнению инструкций запросов. Используйте эту функцию связи только при необходимости, и обычно это происходит при реализации связи "многие ко многим" в таблице бриджинга. Дополнительные сведения см. в разделе "Связи" с кратностью "многие многие" в Power BI Desktop.
Ограничить параллельные запросы. Можно задать максимальное количество подключений DirectQuery для каждого базового источника данных. Он управляет числом запросов, которые одновременно отправляются в источник данных.
- Параметр включен только в том случае, если в модели есть по крайней мере один источник DirectQuery. Значение применяется ко всем источникам DirectQuery и к новым источникам DirectQuery, добавленным в модель.
- Увеличение максимального количества подключений на значение источника данных гарантирует, что больше запросов (до максимального числа), можно отправлять в базовый источник данных, который полезен, если многочисленные визуальные элементы находятся на одной странице или многие пользователи обращаются к отчету одновременно. После достижения максимального количества подключений дальнейшие запросы помещаются в очередь до тех пор, пока подключение не станет доступным. Увеличение этого ограничения приводит к увеличению нагрузки на базовый источник данных, поэтому параметр не гарантирует повышение общей производительности.
- При публикации модели в Power BI максимальное количество одновременных запросов, отправленных в базовый источник данных, также зависит от среды. Разные среды (например, Power BI, Power BI Premium или Сервер отчетов Power BI) могут накладывать различные ограничения пропускной способности. Дополнительные сведения об ограничениях ресурсов емкости см. в разделе лицензий на емкость Microsoft Fabric и настройка емкостей и управление ими в Power BI Premium.
Внимание
Иногда эта статья относится к Power BI Premium или ее подпискам на емкость (SKU). Обратите внимание, что корпорация Майкрософт в настоящее время объединяет варианты покупки и отставает от номера SKU емкости Power BI Premium. Новые и существующие клиенты должны рассмотреть возможность приобретения подписок на емкость Fabric (SKU) вместо этого.
Дополнительные сведения см. в разделе "Важные обновления", поступающие в лицензирование Power BI Premium и вопросы и ответы по Power BI Premium.
Оптимизация макетов отчетов
Отчеты на основе семантической модели DirectQuery можно оптимизировать различными способами, как описано в следующем маркированном списке.
- Включить методы уменьшения запросов: Power BI Desktop Параметры и настройки включает страницу «Сокращение запросов». На этой странице есть три полезных варианта. По умолчанию можно отключить перекрестное выделение и перекрестную фильтрацию, хотя его можно переопределить путем редактирования взаимодействий. Кроме того, можно отобразить кнопку "Применить" для срезов и фильтров. Параметры среза или фильтра не будут применяться, пока пользователь отчета не нажимает кнопку. При включении этих параметров рекомендуется сделать это при первом создании отчета.
-
Применять фильтры сначала. При первом проектировании отчетов рекомендуется применить все применимые фильтры (на уровне отчета, страницы или визуального элемента), прежде чем сопоставлять поля с визуальными полями. Например, вместо того чтобы сначала перетаскивать меры
CountryRegionиSales, а потом фильтровать по определённому году, сначала применяйте фильтр к полюYear. Это связано с тем, что каждый шаг создания визуального элемента будет отправлять запрос, и в то время как можно затем внести другое изменение до завершения первого запроса, он по-прежнему помещает ненужную нагрузку на базовый источник данных. Применяя фильтры раньше, обычно это делает эти промежуточные запросы менее дорогостоящими и более быстрыми. Кроме того, сбой применения фильтров рано может привести к превышению ограничения на 1 миллион строк, как описано в разделе DirectQuery. - Ограничить количество визуальных элементов на странице: при открытии страницы отчета (и при применении фильтров страниц) все визуальные элементы на странице обновляются. Однако существует ограничение на количество запросов, которые могут быть отправлены параллельно, вводимыми средой Power BI и параметром максимальной нагрузки на модель источника данных, как описано выше. Таким образом, по мере увеличения количества визуальных элементов страницы более высока вероятность того, что они будут обновляться последовательно. Это увеличивает время обновления всей страницы, а также увеличивает вероятность того, что визуальные элементы могут отображать несогласованные результаты (для переменных источников данных). По этим причинам рекомендуется ограничить количество визуальных элементов на любой странице и вместо этого использовать более простые страницы. Замена нескольких визуальных элементов карточки одним визуальным элементом с несколькими строками может достичь аналогичного макета страницы.
- отключить взаимодействие между визуализациями: перекрестное выделение и фильтрация требуют отправки запросов в основной источник. Если эти взаимодействия необходимы, рекомендуется отключить их, если время, затраченное на реагирование на выбор пользователей, будет неоправданно долго. Эти взаимодействия можно отключить либо для всего отчета (как описано выше для параметров сокращения запросов), так и по регистру. Дополнительные сведения см. в статье о перекрестном фильтрации визуальных элементов в отчете Power BI.
В дополнение к приведенному выше списку методов оптимизации каждая из следующих возможностей отчетов может способствовать проблемам с производительностью:
фильтры мер: визуальные элементы, содержащие меры (или агрегаты столбцов), могут применять фильтры к этим мерам. Например, в приведенном ниже визуальном элементе показаны продажи по категориям, но только для категорий с более чем $15 млн продаж.
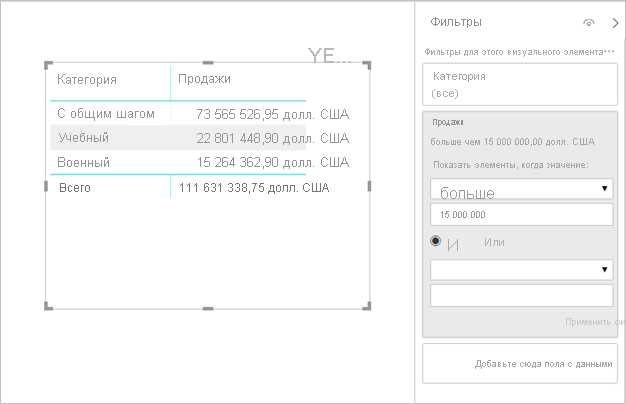
Это может привести к отправке двух запросов в базовый источник:
- Первый запрос получит категории с условием (продажи > $ 15 млн)
- Затем второй запрос получит необходимые данные для визуального элемента, добавив категории, которые соответствовали условию в предложение
WHERE
Обычно он выполняется хорошо, если есть сотни или тысячи категорий, как в этом примере. Производительность может снизиться, однако, если число категорий гораздо больше (и, действительно, запрос завершится ошибкой, если существует более 1 миллионов категорий, удовлетворяющих условию, из-за 1 миллиона строк, рассмотренных выше).
фильтры TopN: Расширенные фильтры можно задать для фильтрации только верхних (или нижних) N значений, ранжированных по показателю. Например, чтобы отобразить только пять лучших категорий в приведенном выше визуальном элементе. Как и фильтры мер, он также приведет к отправке двух запросов в базовый источник данных. Однако первый запрос вернет все категории из базового источника, а затем верхний N определяется на основе возвращаемых результатов. В зависимости от кратности используемого столбца это может привести к проблемам производительности (или сбоям запросов из-за ограничения на 1 миллион строк).
Медиана: Как правило, любые агрегирования (Сумма, Подсчет отдельных и т. д.) передаются в исходный источник. Однако это не верно для Median, так как этот агрегат не поддерживается базовым источником. В таких случаях подробные данные извлекаются из базового источника, и Power BI оценивает медиану из возвращаемых результатов. Это нормально, если медиана вычисляется относительно небольшое количество результатов, но проблемы с производительностью (или сбои запросов из-за ограничения на 1 миллион строк) будут возникать, если кратность большая. Например, медианная страна или население региона может быть разумной, но медианная цена на продажу может не быть.
Срезы с возможностью множественного выбора. Предоставление возможности множественного выбора в срезах и фильтрах может привести к проблемам с производительностью. Это связано с тем, что при выборе пользователем дополнительных элементов среза (например, создание до 10 продуктов, которые они интересуют), каждый новый выбор приводит к отправке нового запроса в базовый источник. Хотя пользователь может выбрать следующий элемент до завершения запроса, он приводит к дополнительной нагрузке на базовый источник. Эту ситуацию можно избежать, нажав кнопку "Применить", как описано выше в методах сокращения запросов.
Визуальные итоги: таблицы и матрицы по умолчанию отображают общие и промежуточные итоги. Во многих случаях дополнительные запросы необходимо отправлять в базовый источник, чтобы получить значения итогов. Он применяется всякий раз, когда используется агрегаты Count Distinct или Median, и во всех случаях при использовании DirectQuery в SAP HANA или хранилище SAP Business Warehouse. При необходимости такие итоги следует отключить (с помощью области форматирования).
Преобразование в составную модель
Преимущества моделей Import и DirectQuery можно объединить в одну модель, настроив режим хранения таблиц моделей. Режим хранения таблиц можно импортировать или DirectQuery или оба, известные как Двойное. Если модель содержит таблицы с различными режимами хранения, она называется составной моделью. Дополнительные сведения см. в статье "Использование составных моделей в Power BI Desktop".
Существует множество функциональных и функциональных улучшений производительности, которые можно достичь, преобразовав модель DirectQuery в составную модель. Составная модель может интегрировать несколько источников DirectQuery, а также включать агрегаты. Таблицы агрегирования можно добавить в таблицы DirectQuery для импорта сводного представления таблицы. Они могут добиться драматических улучшений производительности, когда визуальные элементы запрашивают агрегаты более высокого уровня. Дополнительные сведения см. в разделе "Агрегаты" в Power BI Desktop.
Обучение пользователей
Важно обучить пользователей эффективно работать с отчетами на основе семантических моделей DirectQuery. Авторы отчетов должны быть осведомлены о содержимом, описанном в разделе "Оптимизация проектов отчетов".
Рекомендуется обучить потребителей отчетов пользователям отчетов, основанным на семантических моделях DirectQuery. Это может быть полезно для них, чтобы понять общую архитектуру данных, включая любые соответствующие ограничения, описанные в этой статье. Сообщите им, что ответы обновления и интерактивная фильтрация иногда могут быть медленными. Когда пользователи отчетов понимают, почему происходит снижение производительности, они, скорее всего, теряют доверие к отчетам и данным.
При доставке отчетов о переменных источниках данных обязательно обучите пользователей отчетов использованию кнопки "Обновить". Сообщите им также, что может возникнуть несогласованность результатов и что обновление отчета может устранить любые несоответствия на странице отчета.
Связанный контент
Дополнительные сведения о DirectQuery см. в следующих ресурсах: