Создание кластеров HDInsight, использующих Azure Data Lake Storage 1-го поколения, с помощью портала Azure
Узнайте, как создать кластер HDInsight с Azure Data Lake Storage 1-го поколения в качестве хранилища по умолчанию или дополнительного хранилища на портале Azure. Создавать дополнительное хранилище для кластера HDInsight необязательно, однако бизнес-данные рекомендуется хранить в дополнительных учетных записях хранения.
Предварительные требования
Прежде чем приступить к изучению этого руководства, убедитесь, что выполнены следующие требования.
- Подписка Azure. Перейдите на сайт бесплатной пробной версии Azure.
- Учетная запись Azure Data Lake Storage 1-го поколения. Следуйте инструкциям в статье Начало работы с Azure Data Lake Storage 1-го поколения с помощью портала Azure. В учетной записи также необходимо создать корневую папку. В этой статье используется корневая папка /clusters.
- субъект-служба Microsoft Entra. В этом практическом руководстве содержатся инструкции по созданию субъекта-службы в Microsoft Entra ID. Однако для создания субъекта-службы необходимо быть администратором Microsoft Entra. Если вы являетесь администратором, вы можете пропустить этот предварительный этап и перейти к следующим.
Примечание
Субъект-службу можно создать, только если вы являетесь администратором Microsoft Entra. Администратор Microsoft Entra должен создать субъект-службу, прежде чем создавать кластер HDInsight с Data Lake Storage 1-го поколения. При создании субъекта-службы также необходимо использовать сертификат, как описано в разделе Создание субъекта-службы с использованием сертификата.
Создание кластера HDInsight
В этом разделе описывается, как создать кластер HDInsight с Data Lake Storage 1-го поколения в качестве хранилища по умолчанию или дополнительного хранилища. В этой статье описывается только часть процесса настройки Data Lake Storage 1-го поколения. Общие сведения о создании кластеров и соответствующие процедуры см. в статье Создание кластеров Hadoop в HDInsight.
Создание кластера HDInsight, использующего Data Lake Storage 1-го поколения в качестве хранилища по умолчанию
Создание кластера HDInsight с Data Lake Storage 1-го поколения в качестве учетной записи хранения по умолчанию
Войдите на портал Azure.
Общие сведения о создании кластеров HDInsight см. в разделе Создание кластеров.
В колонке Хранилище в разделе Тип первичного хранилища выберите Data Lake Storage 1-го поколения, а затем введите указанные ниже сведения.

- Выбрать учетную запись Data Lake Store: выберите существующую учетную запись Data Lake Storage 1-го поколения. Требуется существующая учетная запись Data Lake Storage 1-го поколения. См. раздел Предварительные требования.
- Корневой путь: введите путь к каталогу, в котором будут храниться файлы, связанные с кластером. На снимке экрана это путь /clusters/myhdiadlcluster/, в котором должна существовать папка /clusters и в котором портал создает папку myhdicluster. myhdicluster — это имя кластера.
- Доступ к Data Lake Store: настройте доступ между учетной записью Data Lake Storage 1-го поколения и кластером HDInsight. Инструкции см. в разделе Настройка доступа к Data Lake Storage 1-го поколения.
- Дополнительные учетные записи хранения: добавьте учетные записи хранения Azure в качестве дополнительных учетных записей хранения для кластера. Добавление дополнительных хранилищ Data Lake Storage 1-го поколения осуществляется путем предоставления разрешений на доступ к данным в кластере дополнительным учетным записям Data Lake Storage 1-го поколения. При этом учетная запись Data Lake Storage 1-го поколения настраивается в качестве основного типа хранилища. Инструкции см. в разделе Настройка доступа к Data Lake Storage 1-го поколения.
В колонке Доступ к Data Lake Store нажмите кнопку Выбрать и продолжайте создание кластера, как описано в статье Создание кластеров под управлением Linux в HDInsight с помощью портала Azure.
Создание кластера HDInsight, использующего Data Lake Storage 1-го поколения в качестве дополнительного хранилища
Ниже приведены инструкции по созданию кластера HDInsight, где учетная запись хранения BLOB-объектов Azure используется в качестве хранилища по умолчанию, а учетная запись Data Lake Storage 1-го поколения — в качестве дополнительного хранилища.
Создание кластера HDInsight с Data Lake Storage 1-го поколения в качестве дополнительной учетной записи хранения
Войдите на портал Azure.
Общие сведения о создании кластеров HDInsight см. в разделе Создание кластеров.
В колонке Хранилище в разделе Тип первичного хранилища выберите Хранилище Azure, а затем введите указанные ниже сведения.
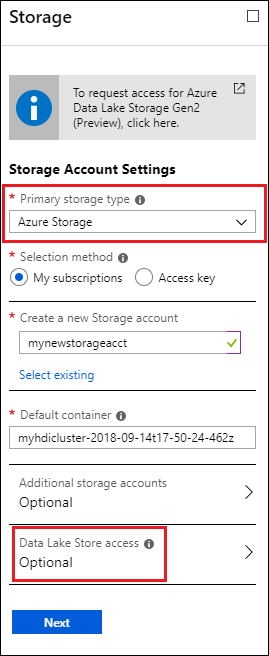
Метод выбора . Чтобы указать учетную запись хранения, которая является частью подписки Azure, выберите Мои подписки, а затем выберите учетную запись хранения. Чтобы указать учетную запись хранения, не входящую в вашу подписку Azure, выберите Ключ доступа, а затем введите данные внешней учетной записи хранения.
Контейнер по умолчанию. Используйте значение по умолчанию или укажите собственное имя.
Дополнительные учетные записи хранения. Добавьте другие учетные записи хранения Azure в качестве дополнительного хранилища.
Доступ к Data Lake Store. Настройте доступ между учетной записью Data Lake Storage 1-го поколения и кластером HDInsight. Инструкции см. в разделе Настройка доступа к Data Lake Storage 1-го поколения.
Настройка доступа к Data Lake Storage 1-го поколения
В этом разделе описана настройка доступа Data Lake Storage 1-го поколения из кластеров HDInsight с помощью субъекта-службы Microsoft Entra.
Указание субъекта-службы
На портале Azure можно использовать существующий субъект-службу или создать новый.
Создание субъекта-службы на портале Azure
- См. статью Создание субъекта-службы и Сертификатов с помощью Microsoft Entra ID.
Использование существующего субъекта-службы на портале Azure
Субъект-служба должен иметь разрешения владельца учетной записи хранения. См. раздел Настройка разрешений владельца учетной записи хранения для субъекта-службы.
Выберите Доступ к Data Lake Store.
В колонке Доступ к Data Lake Storage 1-го поколения выберите Использовать имеющийся.
Выберите Субъект-служба, затем выберите субъект-службу.
Отправьте связанный с выбранным субъектом-службой сертификат (PFX-файл) и введите пароль этого сертификата.

Выберите Доступ, чтобы настроить доступ к папке. См. раздел Настройка разрешений для файлов.
Настройка разрешений владельца учетной записи хранения для субъекта-службы
- В колонке "Управление доступом (IAM)" для учетной записи хранения нажмите "Добавить назначение роли".
- В колонке "Добавление назначения роли" выберите роль "Владелец", затем выберите имя субъекта-службы и нажмите "Сохранить".
Настройка разрешений для файлов
Настройки зависят от того, используется ли учетная запись для хранилища по умолчанию или для дополнительного хранилища.
В качестве хранилища по умолчанию:
- разрешение на корневом уровне учетной записи Data Lake Storage 1-го поколения;
- разрешение на корневом уровне хранилища кластера HDInsight. Например, в этом учебнике это папка /clusters.
В качестве дополнительного хранилища:
- разрешение на доступ к папкам, в которых находятся требуемые файлы.
Назначение разрешения в учетной записи хранения с Data Lake Storage 1-го поколения на корневом уровне
В колонке Доступ к Data Lake Storage 1-го поколения выберите Доступ. Откроется колонка Выбор разрешений для файла. В ней отображаются все учетные записи хранения, включенные в подписку.
Наведите указатель мыши (но не нажимайте) на имя учетной записи Data Lake Storage 1-го поколения, чтобы отобразился флажок, а затем установите этот флажок.

По умолчанию выбраны разрешения Чтение, Запись и Выполнение.
В нижней части страницы щелкните Выбрать.
Чтобы назначить разрешение, нажмите Выполнить.
Нажмите кнопку Готово.
Назначение разрешения на корневом уровне кластера HDInsight
- В колонке Доступ к Data Lake Storage 1-го поколения выберите Доступ. Откроется колонка Выбор разрешений для файла. В ней перечислены все учетные записи хранения Data Lake Storage 1-го поколения, включенные в подписку.
- В колонке Выбор разрешений для файла выберите имя учетной записи хранения Data Lake Storage 1-го, чтобы отобразилось ее содержимое.
- Выберите корень хранилища кластера HDInsight, установив флажок слева от папки. В соответствии с предыдущим снимком экрана корнем хранилища кластера является папка /clusters, указанная при выборе Data Lake Storage 1-го поколения в качестве хранилища по умолчанию.
- Задайте разрешения для папки. По умолчанию выбраны разрешения на чтение, запись и выполнение.
- В нижней части страницы щелкните Выбрать.
- Выберите Запуск.
- Нажмите кнопку Готово.
При использовании Data Lake Storage 1-го поколения в качестве дополнительного хранилища необходимо назначить разрешение только для папок, к которым нужен доступ из кластера HDInsight. Например, на снимке экрана ниже предоставляется доступ только к папке mynewfolder в учетной записи хранения Data Lake Storage 1-го поколения.

Проверка настроек кластера
После завершения настройки кластера проверьте результат в колонке кластера, выполнив одно или оба указанных ниже действия.
Чтобы проверить, является ли указанная вами учетная запись Data Lake Storage 1-го поколения связанным хранилищем для кластера, выберите Учетные записи хранения в левой области.

Чтобы проверить, правильно ли субъект-служба связан с кластером HDInsight, выберите Доступ к Data Lake Storage 1-го поколения в левой области.

Примеры
Настроив Data Lake Storage 1-го поколения в качестве хранилища для кластера, можно изучить следующие примеры использования кластера HDInsight для анализа данных, хранящихся в Data Lake Storage 1-го поколения.
Отправка запроса Hive к данным, хранящимся в Data Lake Storage 1-го поколения (основное хранилище)
Чтобы выполнить запрос Hive, используйте интерфейс представлений Hive, доступный на портале Ambari. Инструкции по использованию представлений Ambari Hive см. в статье Использование представления Hive с Hadoop в HDInsight.
При работе с данными в Data Lake Storage 1-го поколения изменить можно лишь несколько строк.
Если вы используете, например, кластер, созданный с Data Lake Storage 1-го поколения в качестве основного хранилища, путь к данным будет следующим: adl://< data_lake_storage_gen1_account_name>/azuredatalakestore.net/path/to/file. Запрос Hive для создания таблицы на основе демонстрационных данных, хранящихся в учетной записи Data Lake Storage 1-го поколения, выглядит следующим образом:
CREATE EXTERNAL TABLE websitelog (str string) LOCATION 'adl://hdiadlsg1storage.azuredatalakestore.net/clusters/myhdiadlcluster/HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/'
Описание
-
adl://hdiadlsg1storage.azuredatalakestore.net/— корневой элемент учетной записи Data Lake Storage 1-го поколения; -
/clusters/myhdiadlcluster— корень данных кластера, указанный при создании кластера; -
/HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/— расположение примера файла, который используется в запросе.
Отправка запроса Hive к данным, хранящимся в Data Lake Storage 1-го поколения (дополнительное хранилище)
Если в созданном кластере в качестве хранилища по умолчанию используется хранилище BLOB-объектов, то демонстрационные данные не будут находиться в учетной записи Data Lake Storage 1-го поколения, используемой в качестве дополнительного хранилища. В этом случае сначала перенесите эти данные из хранилища BLOB-объектов в Data Lake Storage 1-го поколения, а затем выполните запросы, как показано в предыдущем примере.
Сведения о том, как скопировать данные из хранилища BLOB-объектов в Data Lake Storage 1-го поколения, см. в следующих статьях:
- Использование Distcp для копирования данных между хранилищем BLOB-объектов и Data Lake Storage 1-го поколения
- Использование AdlCopy для копирования данных из хранилища BLOB-объектов в Data Lake Storage 1-го поколения
Использование Data Lake Storage 1-го поколения с кластером Spark
Кластер Spark можно использовать для выполнения заданий Spark с данными, хранящимися в Data Lake Storage 1-го поколения. Дополнительные сведения см. в статье Использование кластера HDInsight Spark для анализа данных в Data Lake Storage 1-го поколения.