적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
Microsoft Fabric의 데이터 팩토리는 더 간단한 아키텍처, 기본 제공 AI 및 새로운 기능을 갖춘 차세대 Azure 데이터 팩토리입니다. 데이터 통합을 접하는 경우 Fabric Data Factory부터 시작합니다. 기존 ADF 워크로드는 Fabric 업그레이드하여 데이터 과학, 실시간 분석 및 보고 전반에 걸쳐 새로운 기능에 액세스할 수 있습니다.
- Fabric 무료 평가판을 시작합니다.
Microsoft Fabric의 Data Factory로 Azure Data Factory를 업그레이드합니다
데이터 팩터리 및 Synapse 파이프라인에서의 Spark 작업은 사용자 고유 또는 주문형 HDInsight 클러스터에서 Spark 프로그램을 실행합니다. 이 문서는 데이터 변환 및 지원되는 변환 활동의 일반적인 개요를 표시하는 데이터 변환 활동 문서에서 작성합니다. 주문형 Spark 연결 서비스를 사용하면 서비스에서는 적시에 데이터를 처리할 수 있도록 자동으로 Spark 클러스터를 만든 다음, 처리가 완료되면 클러스터를 삭제합니다.
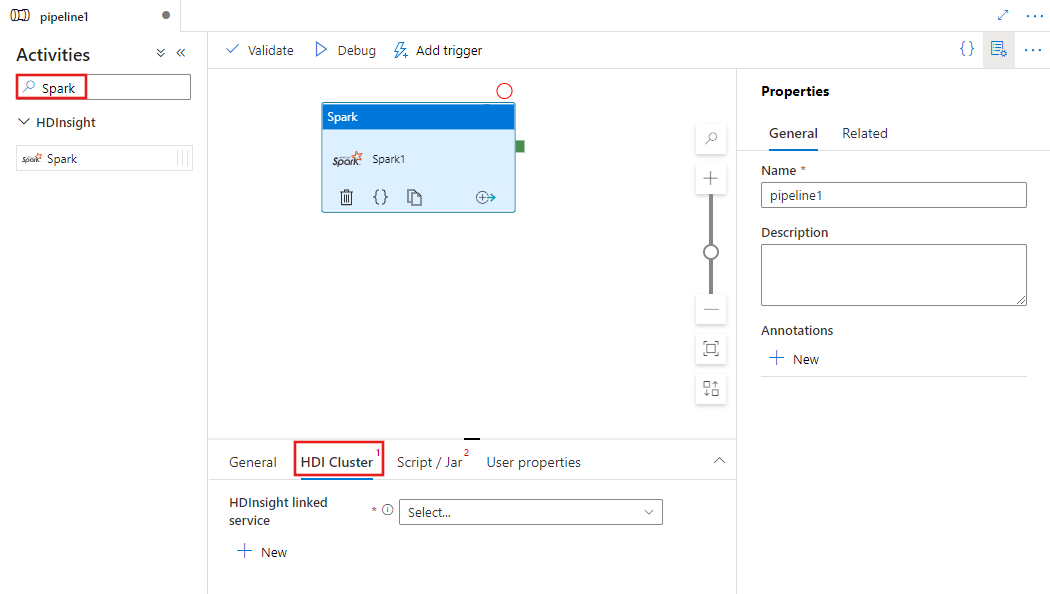
UI를 사용하여 파이프라인에 Spark 작업 추가
파이프라인에 Spark 작업을 사용하려면 다음 단계를 완료합니다.
파이프라인 작업 창에서 Spark를 검색하고 Spark 작업을 파이프라인 캔버스로 끕니다.
아직 선택하지 않은 경우 캔버스에서 새 Spark 작업을 선택합니다.
HDI 클러스터 탭을 선택하여 Spark 작업을 실행하는 데 사용할 HDInsight 클러스터에 연결된 새 서비스를 선택하거나 만듭니다.
Script/Jar 탭을 선택하여 스크립트를 호스트할 Azure Storage 계정에 대한 새 작업 연결 서비스를 선택하거나 만듭니다. 실행할 파일의 경로를 지정합니다. 프록시 사용자, 디버깅 구성, 인수 및 Spark 구성 매개 변수를 포함한 고급 세부 정보를 구성하여 스크립트에 전달할 수도 있습니다.
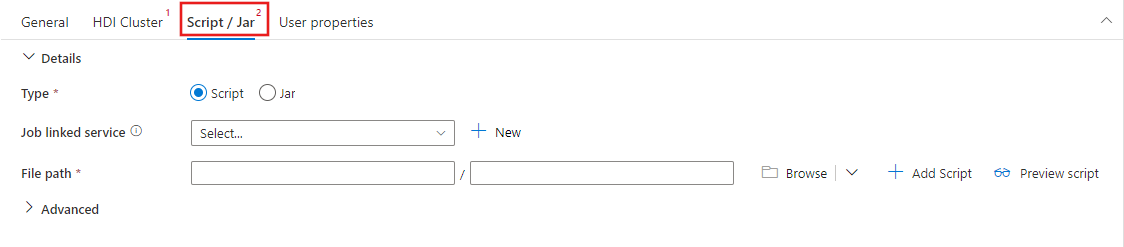
Spark 활동 속성
Spark 작업의 샘플 JSON 정의는 다음과 같습니다.
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
다음 표에서는 JSON 정의에 사용하는 JSON 속성을 설명합니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| 이름 | 파이프라인의 작업 이름입니다. | 예 |
| 설명 | 작업이 어떤 일을 수행하는지 설명하는 텍스트입니다. | 아니요 |
| 타입 | Spark 작업의 경우 작업 유형은 HDInsightSpark입니다. | 예 |
| 연동된 서비스 이름 | Spark 프로그램이 실행되는 HDInsight Spark 연결된 서비스의 이름입니다. 이 연결된 서비스에 대한 자세한 내용은 컴퓨팅 연결 서비스 문서를 참조하세요. | 예 |
| SparkJobLinkedService | Spark 작업 파일, 종속성 및 로그를 보유하는 Azure Storage 연결된 서비스입니다. 여기에서는 Azure Blob Storage 및 ADLS Gen2 연결된 서비스만 지원됩니다. 이 속성에 대한 값을 지정하지 않으면 HDInsight 클러스터와 연결된 스토리지가 사용됩니다. 이 속성의 값은 Azure Storage에 연결된 서비스만 될 수 있습니다. | 아니요 |
| 루트 경로 | Azure Blob 컨테이너 및 Spark 파일이 포함된 폴더입니다. 파일 이름은 대/소문자를 구분합니다. 이 폴더의 구조에 대한 자세한 내용은 폴더 구조 섹션(다음 섹션)을 참조하세요. | 예 |
| 진입파일경로 | Spark 코드/패키지의 루트 폴더에 대한 상대 경로입니다. 항목 파일은 Python 파일 또는 .jar 파일이어야 합니다. | 예 |
| className | 애플리케이션의 Java/Spark 기본 클래스 | 아니요 |
| 인수 | Spark 프로그램에 대한 명령줄 인수 목록입니다. | 아니요 |
| proxyUser | Spark 프로그램을 실행하기 위해 가장할 사용자 계정 | 아니요 |
| sparkConfig | Spark 구성 - 애플리케이션 속성 항목에 나열된 Spark 구성 속성의 값을 지정합니다. | 아니요 |
| getDebugInfo | Spark 로그 파일이 HDInsight 클러스터(또는 sparkJobLinkedService에서 지정한)에서 사용하는 Azure 스토리지에 복사되는 시기를 지정합니다. 허용되는 값: None, Always 또는 Failure. 기본값은 None입니다. | 아니요 |
폴더 구조
Spark 작업은 Pig/Hive 작업보다 확장성이 뛰어납니다. Spark 작업의 경우 jar 패키지(Java CLASSPATH에 배치), Python 파일(PYTHONPATH에 배치됨) 및 기타 파일과 같은 여러 종속성을 제공할 수 있습니다.
HDInsight 연결된 서비스에서 참조하는 Azure Blob Storage에 다음 폴더 구조를 만듭니다. 그런 다음 종속 파일을 entryFilePath로 표시되는 루트 폴더의 해당 하위 폴더에 업로드합니다. 예를 들어 pyFiles 하위 폴더에 Python 파일을 업로드하고 jar 파일을 루트 폴더의 jars 하위 폴더에 업로드합니다. 런타임 시 서비스는 Azure Blob Storage에서 다음과 같은 폴더 구조를 예상합니다.
| 경로 | 설명 | 필수 | 형식 |
|---|---|---|---|
.(루트) |
스토리지 연결된 서비스에서 Spark 작업의 루트 경로 | 예 | 폴더 |
| <사용자 정의 > | Spark 작업의 엔트리 파일을 가리키는 경로 | 예 | 파일 |
| ./jars | 이 폴더 아래의 모든 파일이 업로드되고 클러스터의 Java 클래스 경로에 배치됩니다. | 아니요 | 폴더 |
| ./pyFiles | 이 폴더 아래 모든 파일이 업로드되고 클러스터의 PYTHONPATH에 배치됨 | 아니요 | 폴더 |
| ./files | 이 폴더 아래 모든 파일이 업로드되고 실행기 작업 디렉터리에 배치됨 | 아니요 | 폴더 |
| ./archives | 이 폴더 아래 모든 파일이 압축 해제됨 | 아니요 | 폴더 |
| ./logs | Spark 클러스터의 로그를 포함하는 폴더입니다. | 아니요 | 폴더 |
다음은 HDInsight 연결된 서비스에서 참조하는 Azure Blob Storage 두 개의 Spark 작업 파일이 포함된 스토리지의 예입니다.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
관련 콘텐츠
다른 방법으로 데이터를 변환하는 방법을 설명하는 다음 문서를 참조하세요.