Azure HDInsight 고가용성 솔루션 아키텍처 사례 연구
Azure HDInsight의 복제 메커니즘을 고가용성 솔루션 아키텍처에 통합할 수 있습니다. 이 문서에서는 Contoso Retail에 대한 가상의 사례 연구를 통해 고가용성 재해 복구 방법, 비용 고려 사항 및 해당 디자인에 대해 설명합니다.
고가용성 재해 복구에 대한 권장 사항은 여러 방식으로 순서를 바꾸고 조합하여 사용할 수 있습니다. 해당 솔루션은 각 옵션의 장단점을 면밀하게 살핀 후에 결정해야 합니다. 이 문서에서는 한 가지 솔루션에 대해서만 설명합니다.
고객 아키텍처
다음 이미지는 Contoso Retail 기본 아키텍처를 그림으로 나타낸 것입니다. 아키텍처는 스트리밍 워크로드, 일괄 처리 워크로드, 서비스 계층, 소비 계층, 스토리지 계층 및 버전 제어로 구성됩니다.
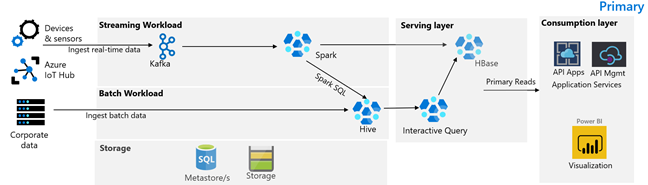
스트리밍 워크로드
디바이스 및 센서는 데이터를 생성하여 메시징 프레임워크를 구성하는 HDInsight Kafka로 보냅니다. HDInsight Spark 소비자는 Kafka 토픽에서 읽기를 수행합니다. Spark는 들어오는 메시지를 변환하고 이를 서비스 계층의 HDInsight HBase 클러스터에 씁니다.
일괄 처리 워크로드
Hive 및 MapReduce를 실행하는 HDInsight Hadoop 클러스터는 온-프레미스 트랜잭션 시스템에서 데이터를 수집합니다. Hive 및 MapReduce에 의해 변환된 원시 데이터는 Azure Data Lake Storage Gen2의 지원을 받는 데이터 레이크의 논리 파티션에서 Hive 테이블에 저장됩니다. Hive 테이블에 저장된 데이터는 Spark SQL에서도 사용할 수 있습니다. Spark SQL은 큐레이팅된 데이터를 HBase에 저장하여 서비스를 제공하기에 앞서 일괄 변환을 수행합니다.
서비스 계층
Apache Phoenix를 지원하는 HDInsight HBase 클러스터는 데이터를 웹 애플리케이션 및 시각화 대시보드에 제공하는 데 사용됩니다. HDInsight LLAP 클러스터는 내부 보고 요구 사항을 충족하는 데 사용됩니다.
소비 계층
Azure API Apps 및 API Management 계층은 퍼블릭 웹 페이지를 지원합니다. 내부 보고 요구 사항은 Power BI에 의해 충족됩니다.
스토리지 계층
논리적으로 분할된 Azure Data Lake Storage Gen2는 엔터프라이즈 데이터 레이크로 사용됩니다. HDInsight 메타스토어는 Azure SQL DB에서 지원됩니다.
버전 제어 시스템
Azure Pipelines에 통합되고 Azure 외부에 호스트되는 버전 제어 시스템입니다.
고객 비즈니스 연속성 요구 사항
재해가 발생할 경우에 필요한 최소한의 비즈니스 기능을 결정하는 것이 중요합니다.
Contoso Retail의 비즈니스 연속성 요구 사항
- 지역 오류 또는 지역별 서비스 상태 문제로부터 보호받아야 합니다.
- 고객에게 404 오류가 발생하면 안 됩니다. 퍼블릭 콘텐츠는 항상 제공되어야 합니다. (RTO = 0)
- 부실 상태에 있는 퍼블릭 콘텐츠를 연중 대부분 5시간마다 표시할 수 있습니다. (RPO = 5시간)
- 명절 연휴 기간 중 퍼블릭 콘텐츠를 항상 최신 상태로 유지해야 합니다. (RPO = 0)
- 내부 보고 요구 사항은 비즈니스 연속성에 중요한 요소로 간주되지 않습니다.
- 비즈니스 연속성 비용을 최적화합니다.
제안된 솔루션
다음 이미지는 Contoso Retail의 고가용성 재해 복구 아키텍처를 보여 줍니다.
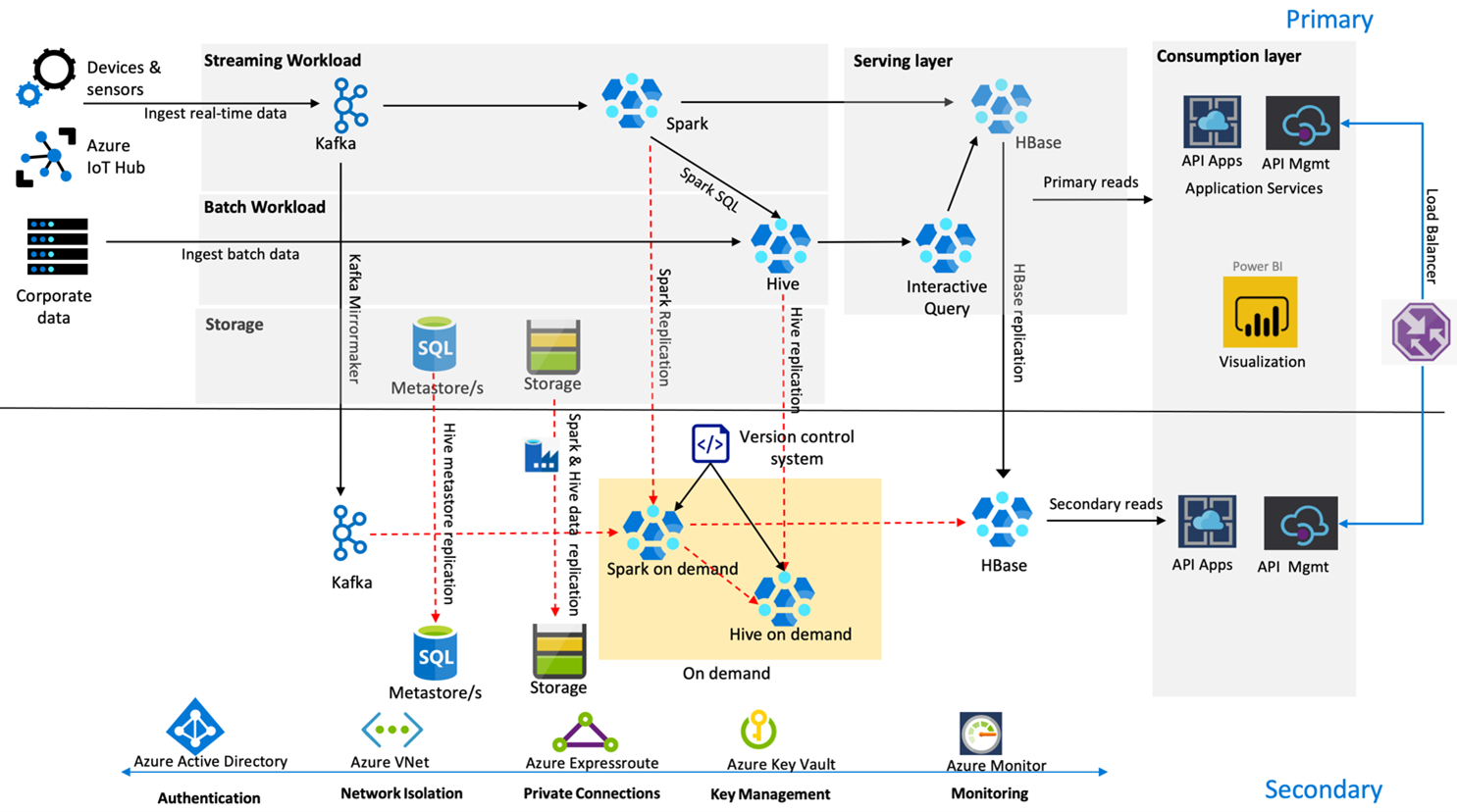
Kafka는 활성 – 수동 복제를 사용하여 Kafka 토픽을 주 지역에서 보조 지역으로 미러링합니다. Kafka 복제를 사용하는 대신 두 지역 모두에서 Kafka로의 생성 작업을 수행할 수 있습니다.
Hive 및 Spark는 평소에는 활성(주 지역) – 주문형(보조 지역) 복제 모델을 사용합니다. Hive 복제 프로세스는 주기적으로 실행되며 Hive Azure SQL 메타스토어 및 Hive 스토리지 계정 복제가 수반됩니다. Spark 스토리지 계정은 ADF DistCP를 사용하여 주기적으로 복제됩니다. 이러한 클러스터의 일시성이라는 특성은 비용을 최적화하는 데 도움이 됩니다. 복제는 4시간마다 실행되어 RPO를 달성하도록 예약되며 이는 5시간인 요구 사항을 여유 있게 충족하는 시간입니다.
HBase 복제는 평소에는 리더 – 팔로워 모델을 사용하여 지역 및 RPO가 매우 낮은지 여부와 관계없이 데이터가 항상 제공되도록 합니다.
주 지역에 지역 오류가 발생하는 경우 웹 페이지 및 백 엔드 콘텐츠가 보조 지역에서 어느 정도 부실한 상태로 5시간 동안 제공됩니다. Azure 서비스 상태 대시보드에 복구 예정 시간이 5시간 동안 표시되지 않으면 Contoso Retail에서 보조 지역에 Hive 및 Spark 변환 계층을 만들고 모든 업스트림 데이터 원본이 보조 지역으로 향하게 합니다. 보조 지역을 쓰기 가능으로 설정하면 주 지역으로의 역방향 복제를 포함하는 장애 조치(failback) 프로세스가 발생합니다.
쇼핑이 최고조에 이르는 기간에는 전체 보조 파이프라인이 항상 활성 상태에서 실행됩니다. Kafka 생산자는 두 지역 모두를 대상으로 생산 작업을 수행하며 HBase 복제는 퍼블릭 콘텐츠가 항상 최신 상태로 유지되도록 리더-팔로워 모델에서 리더-리더 모델로 변경됩니다.
장애 조치(failover) 솔루션은 비즈니스 연속성에 중요한 요소가 아니므로 내부 보고용으로 설계할 필요가 없습니다.
다음 단계
이 문서에서 설명한 항목에 관해 자세히 알아보려면 다음을 참조하세요.