Azure HDInsight 비즈니스 연속성 아키텍처
이 문서에서는 Azure HDInsight에서 고려할 수 있는 비즈니스 연속성 아키텍처의 예제를 몇 가지 제공합니다. 재해 시 축소되는 기능의 허용 범위는 애플리케이션마다 다른 비즈니스 결정 사항입니다. 일부 애플리케이션을 사용할 수 없거나, 기능이 축소되거나 일정 기간 처리가 지연되어 부분적으로 사용 가능하도록 허용될 수 있습니다. 다른 애플리케이션에서는 축소된 기능이 허용되지 않을 수 있습니다.
참고 항목
이 문서에 제시된 아키텍처가 완전하지는 않습니다. 예상되는 비즈니스 연속성, 운영 복잡성 및 소유 비용에 대한 객관적인 결정을 내린 후에는 고유한 아키텍처를 디자인해야 합니다.
Apache Hive 및 Interactive Query
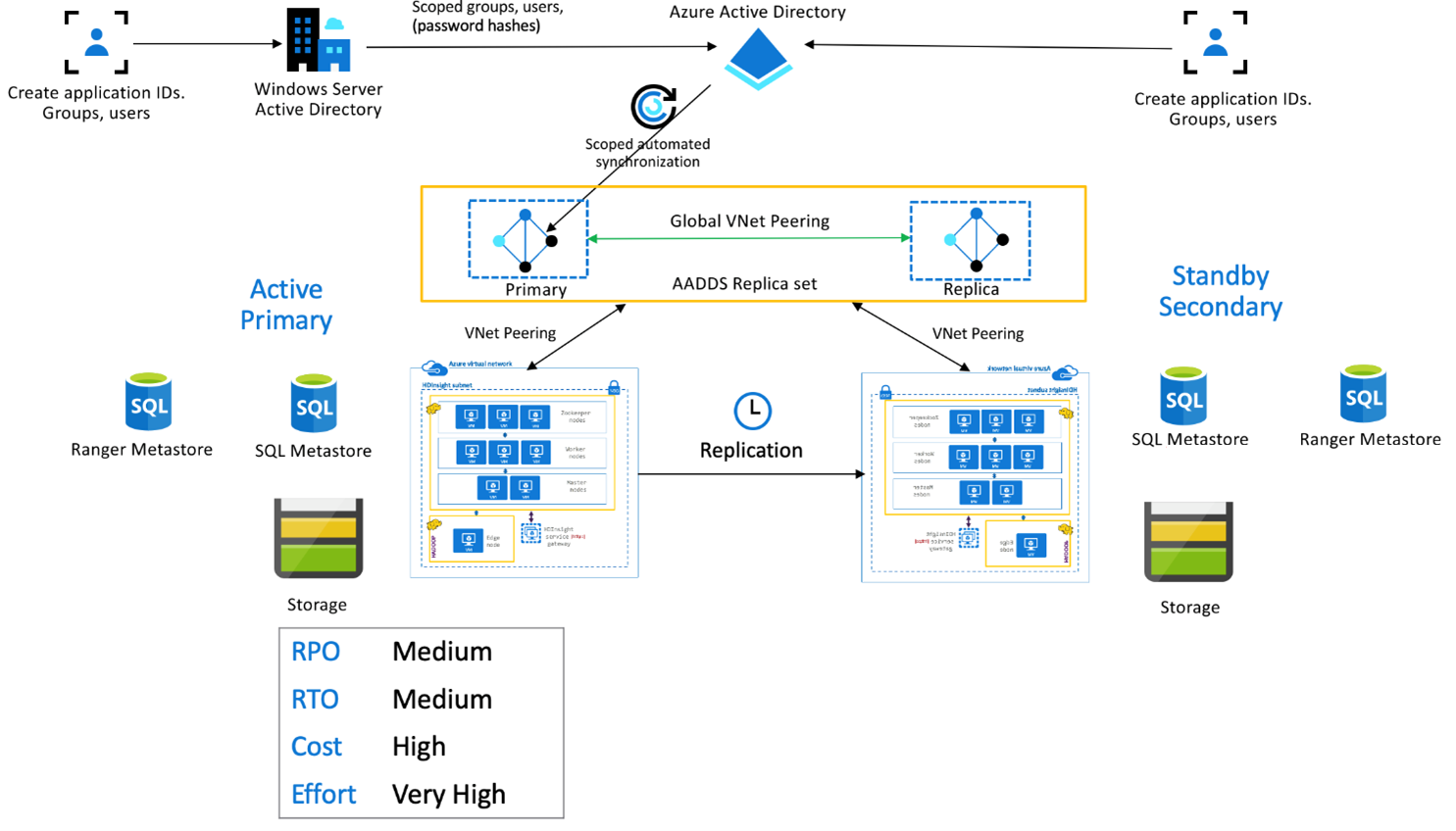
HDInsight Hive 및 Interactive Query 클러스터에서 비즈니스 연속성을 얻으려면 Hive Replication V2를 사용하는 것이 좋습니다. 복제해야 하는 독립 실행형 Hive 클러스터의 영구 섹션은 스토리지 계층 및 Hive 메타스토어입니다. Enterprise Security Package를 사용하는 다중 사용자 시나리오의 Hive 클러스터에는 Microsoft Entra Domain Services 및 Ranger Metastore가 필요합니다.
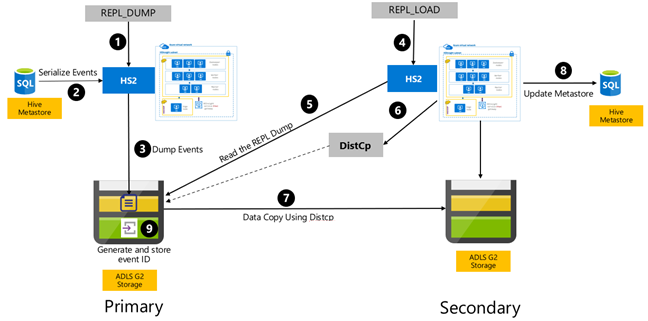
Hive 이벤트 기반 복제는 주 클러스터와 보조 클러스터 사이에 구성됩니다. 이 단계는 부트스트랩과 증분 실행의 두 가지 별도 단계로 구성됩니다.
부트스트랩은 Hive 메타스토어 정보를 포함한 전체 Hive 웨어하우스를 주 클러스터에서 보조 클러스터로 복제합니다.
증분 실행은 주 클러스터에서 자동화되며, 증분 실행 중에 생성된 이벤트는 보조 클러스터에서 재생됩니다. 보조 클러스터는 주 클러스터에서 생성된 이벤트를 캐치업하여 복제 실행 후 보조 클러스터가 주 클러스터의 이벤트와 일치하도록 합니다.
보조 클러스터는 분산 복사(DistCp)를 실행하는 동안에만 필요하지만, 스토리지와 메타데이터는 영구적이어야 합니다. 복제하기 전에 주문형으로 스크립팅된 보조 클러스터를 실행하도록 선택하고 복제 스크립트를 실행한 후 복제에 성공하면 이 클러스터를 종료할 수 있습니다.
보조 클러스터는 일반적으로 읽기 전용입니다. 보조 클러스터를 읽기/쓰기용으로 만들 수 있지만, 그러면 보조 클러스터에서 주 클러스터로 변경 내용을 복제하는 작업이 더 복잡해집니다.
Hive 이벤트 기반 복제 RPO 및 RTO
RPO: 데이터 손실이 마지막으로 성공한 주 클러스터에서 보조 클러스터로의 증분 복제 이벤트로 제한됩니다.
RTO: 보조 클러스터와의 업스트림/다운스트림 트랜잭션에 실패한 후 다시 시작하는 그 사이 시간입니다.
Apache Hive 및 Interactive Query 아키텍처
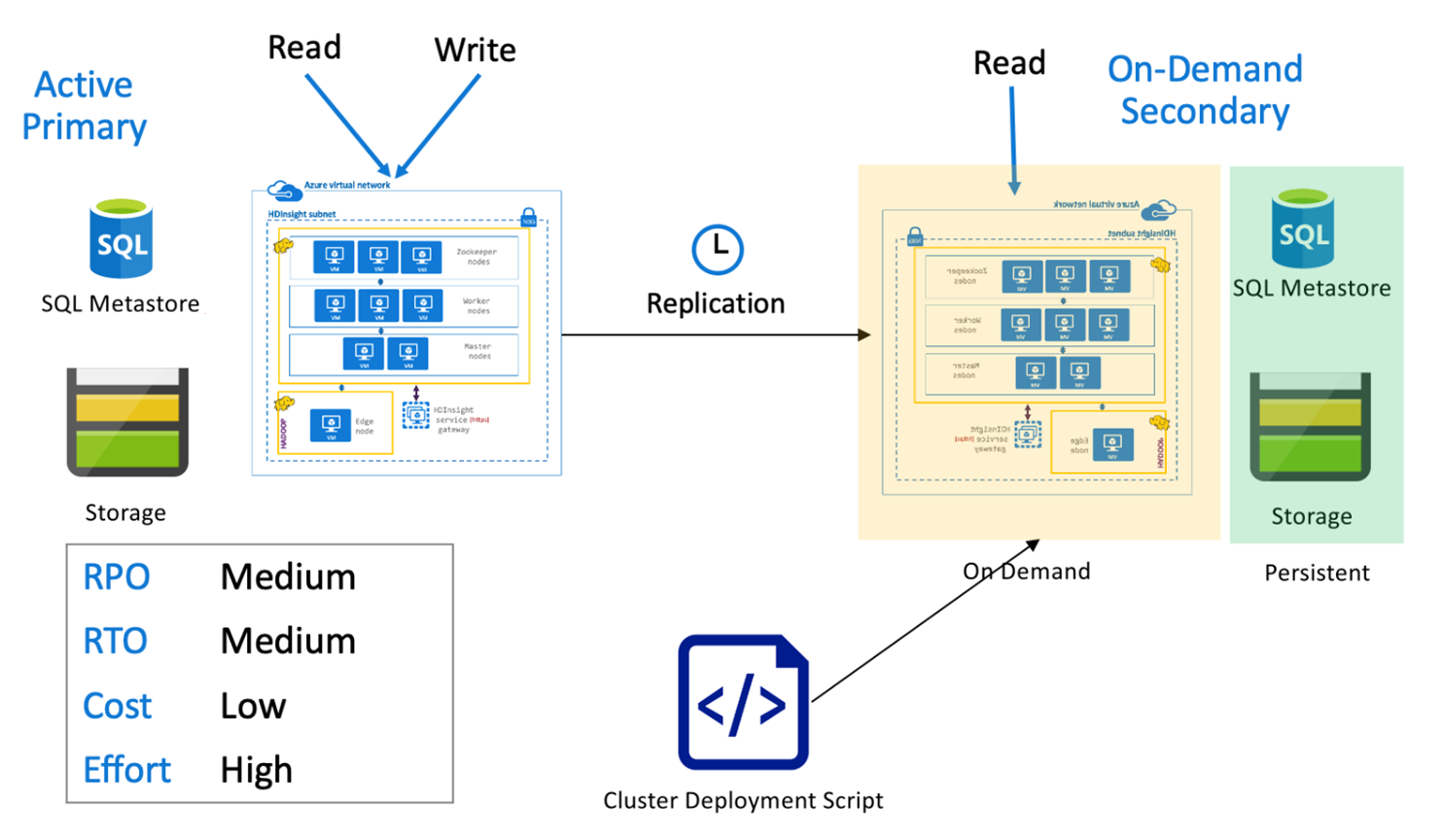
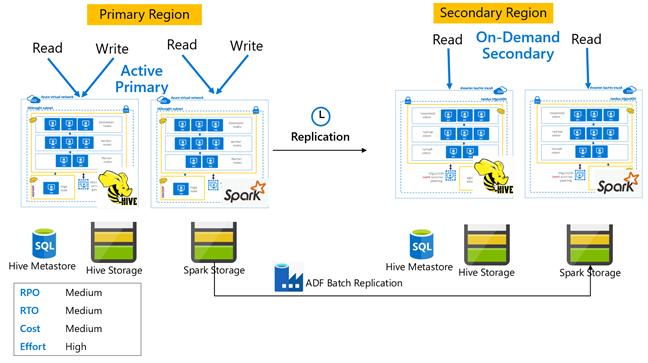
주문형 보조를 사용하는 Hive 활성 주
주문형 보조를 사용하는 활성 주 아키텍처의 애플리케이션은 활성 주 영역에 기록되며, 정상 작동 중에는 클러스터가 보조 영역에 프로비저닝되지 않습니다. 보조 영역의 SQL Metastore와 스토리지는 영구적이며, HDInsight 클러스터는 예약된 Hive 복제가 실행되기 전에만 주문형으로 스크립팅 및 배포됩니다.
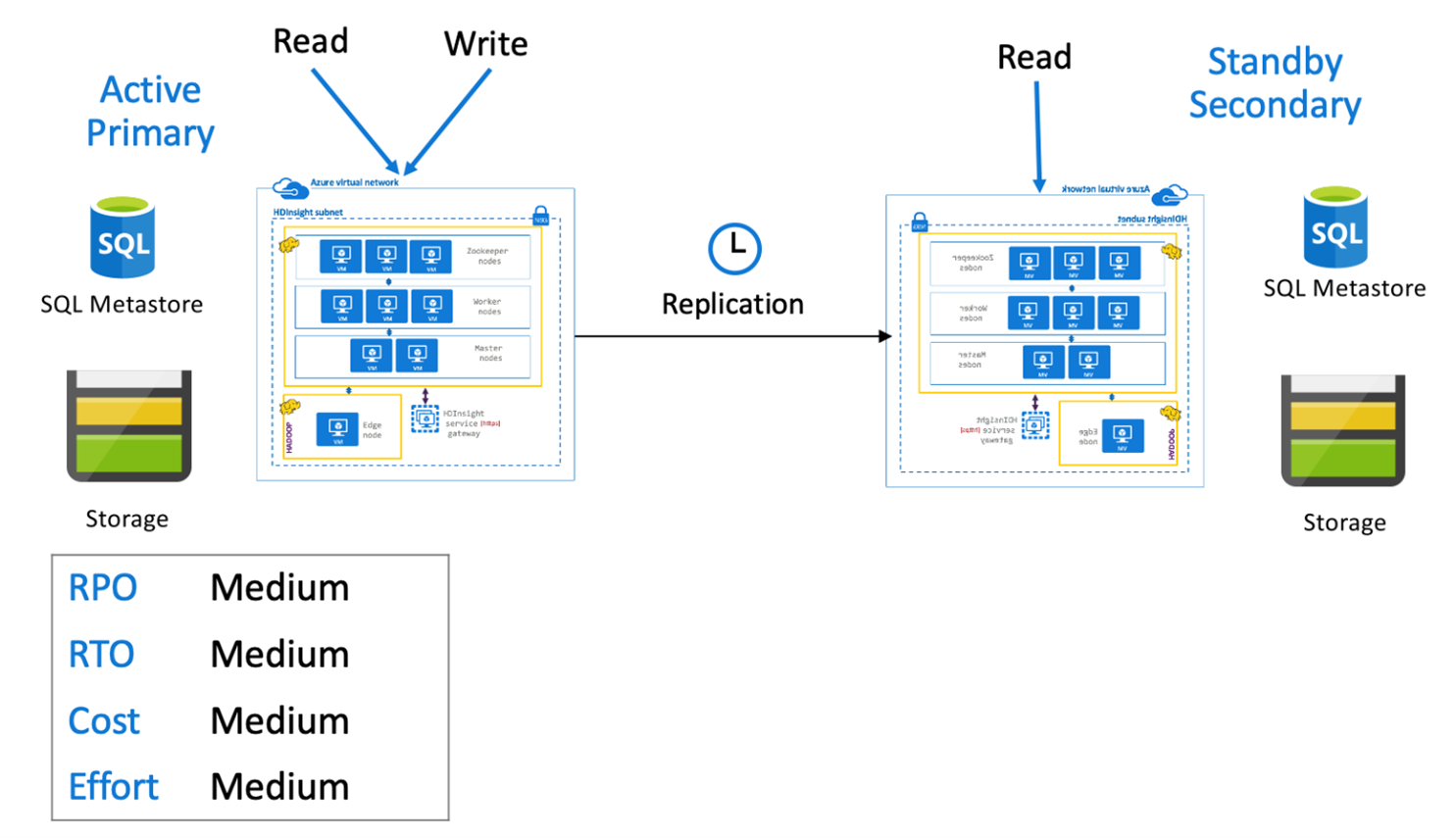
대기 보조를 사용하는 Hive 활성 주
대기 보조를 사용하는 활성 주 애플리케이션은 활성 주 영역에 기록되며, 정상 작동 중에는 읽기 전용 모드의 축소된 대기 상태 보조 클러스터가 실행됩니다. 정상 작동 중에는 지역별 읽기 작업을 보조 영역에 오프로드하도록 선택할 수 있습니다.
Hive 복제 및 코드 샘플에 대한 자세한 내용은 Azure HDInsight 클러스터의 Apache Hive 복제를 참조하세요.
Apache Spark
Spark 워크로드에는 Hive 구성 요소가 포함될 수도 있고, 포함되지 않을 수도 있습니다. Spark SQL 워크로드가 Hive에서 데이터를 읽고 쓸 수 있도록 하기 위해, HDInsight Spark 클러스터는 동일한 영역의 Hive/Interactive 쿼리 클러스터에서 Hive 사용자 지정 메타스토어를 공유합니다. 이러한 시나리오에서는 Spark 워크로드의 지역 간 복제도 Hive 메타스토어 및 스토리지의 복제와 함께 제공되어야 합니다. 이 섹션의 장애 조치(failover) 시나리오는 다음의 두 가지에 모두 적용됩니다.
- HDInsight Interactive Query 클러스터를 사용하는 HWC(Hive Warehouse Connector) 설정 사용 ACID 테이블의 Spark SQL
- HDInsight Hadoop 클러스터를 사용하는 비ACID 테이블의 Spark SQL 워크로드
Spark가 독립 실행형 모드에서 작동하는 시나리오의 경우, 큐레이팅된 데이터와 저장된 Spark Jar(Livy 작업용)를 Azure Data Factory의 DistCP를 사용하여 주 지역에서 보조 지역으로 정기적으로 복제해야 합니다.
버전 제어 시스템을 사용하여 주 또는 보조 클러스터에 쉽게 배포할 수 있는 Spark Notebook 및 라이브러리를 저장하는 것이 좋습니다. Notebook 기반 솔루션 및 Notebook 기반이 아닌 솔루션이 주 또는 보조 작업 영역에 올바른 데이터 탑재를 로드할 준비가 되었는지 확인합니다.
HDInsight에서 기본적으로 제공하는 것 이상의 고객별 라이브러리가 있는 경우, 이를 추적하여 대기 보조 클러스터에 주기적으로 로드해야 합니다.
Apache Spark 복제 RPO 및 RTO
RPO: 데이터 손실이 마지막으로 성공한 주 클러스터에서 보조 클러스터로의 증분 복제(Spark 및 Hive)로 제한됩니다.
RTO: 보조 클러스터와의 업스트림/다운스트림 트랜잭션에 실패한 후 다시 시작하는 그 사이 시간입니다.
Apache Spark 아키텍처
주문형 보조를 사용하는 Spark 활성 주
애플리케이션은 주 지역의 Spark 및 Hive 클러스터에 읽고 쓰며, 정상 작동 중에는 클러스터가 보조 영역에 프로비전되지 않습니다. 보조 영역의 SQL Metastore, Hive Storage 및 Spark Storage는 영구적입니다. Spark 및 Hive 클러스터는 스크립팅되어 주문형으로 배포됩니다. Hive 복제는 Hive Storage 및 Hive 메타스토어 복제에 사용되며, Azure Data Factory의 DistCP는 독립 실행형 Spark 스토리지를 복사하는 데 사용될 수 있습니다. 종속성 DistCp 컴퓨팅으로 인해 모든 Hive 복제가 실행되기 전에 Hive 클러스터를 배포해야 합니다.
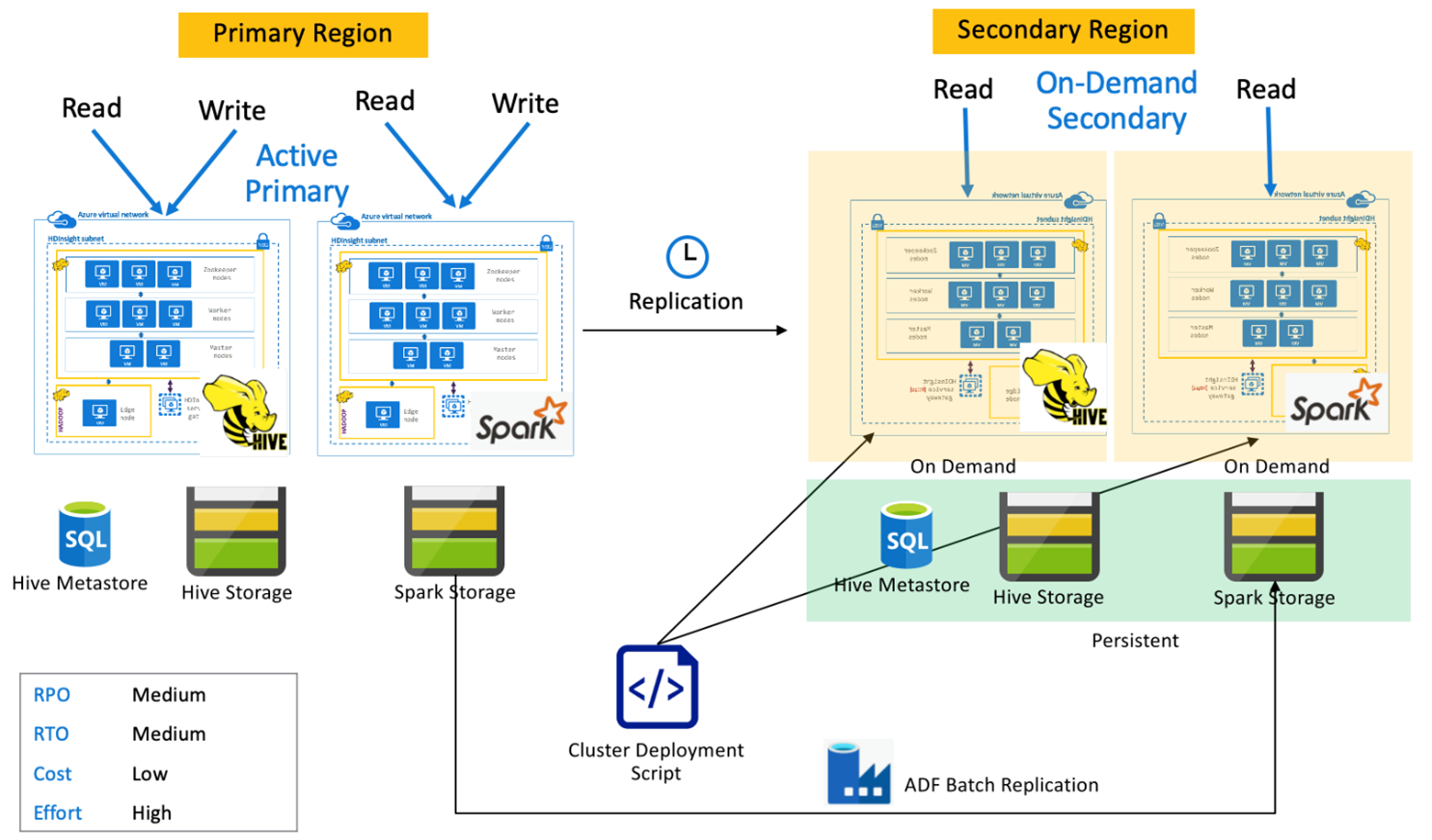
대기 보조를 사용하는 Spark 활성 주
애플리케이션은 주 영역의 Spark 및 Hive 클러스터에 읽고 쓰며, 읽기 전용 모드의 축소된 대기 Hive 및 Spark 클러스터는 정상 작동 중에 보조 영역에서 실행됩니다. 정상 작동 중에는 지역별 Hive 및 Spark 읽기 작업을 보조에 오프로드하도록 선택할 수 있습니다.
Apache HBase
HBase 내보내기 및 HBase 복제는 HDInsight HBase 클러스터 간에 비즈니스 연속성을 지원하는 일반적인 방법입니다.
HBase 내보내기는 HBase 내보내기 유틸리티를 사용하여 주 HBase 클러스터에서 기본 Azure Data Lake Storage Gen 2 스토리지로 테이블을 내보내는 일괄 처리 복제 프로세스입니다. 내보낸 데이터는 보조 HBase 클러스터에서 액세스하고, 테이블로 가져올 수 있습니다. 이때 보조 클러스터에 있어야 합니다. HBase 내보내기에서는 테이블 수준 세분성을 제공하지만, 증분 업데이트 상황에서 내보내기 자동화 엔진은 각 실행에 포함할 증분 행의 범위를 제어합니다. 자세한 내용은 HDInsight HBase 백업 및 복제를 참조하세요.
HBase 복제는 완전히 자동화된 방식으로 HBase 클러스터 간에 근 실시간 복제를 사용합니다. 복제는 테이블 수준에서 수행됩니다. 모든 테이블 또는 특정 테이블을 복제 대상으로 지정할 수 있습니다. HBase 복제는 결과적으로 일관적입니다. 즉, 주 영역의 테이블에 대한 최근 편집 항목을 모든 보조 데이터베이스에서 즉시 사용할 수 없습니다. 보조 영역은 결과적으로 주 영역과 일치하게 됩니다. 다음과 같은 경우 둘 이상의 HDInsight HBase 클러스터 간에 HBase 복제를 설정할 수 있습니다.
- 주/보조는 동일한 가상 네트워크에 있습니다.
- 주/보조는 동일한 지역에 피어링된 다른 Vnet에 있습니다.
- 주/보조는 다른 지역에 피어링된 다른 Vnet에 있습니다.
자세한 내용은 Azure Virtual Network에서 Apache HBase 클러스터 복제 설정을 참조하세요.
HBase 폴더 복사, 테이블 복사 및 스냅샷 등 HBase 클러스터 백업을 수행하는 몇 가지 다른 방법이 있습니다.
HBase RPO 및 RTO
HBase 내보내기
- RPO: 데이터 손실이 마지막으로 성공한 주 클러스터에서 보조 클러스터로의 일괄 증분 가져오기로 제한됩니다.
- RTO: 주 클러스터에서 실패한 후 보조 클러스터에서 다시 시작하는 그 사이 시간입니다.
HBase 복제
- RPO: 데이터 손실이 보조 클러스터에서 받은 마지막 WalEdit 배송으로 제한됩니다.
- RTO: 주 클러스터에서 실패한 후 보조 클러스터에서 다시 시작하는 그 사이 시간입니다.
HBase 아키텍처
HBase 복제는 Leader-Follower, Leader-Leader, Cyclic의 세 가지 모드에서 설정할 수 있습니다.
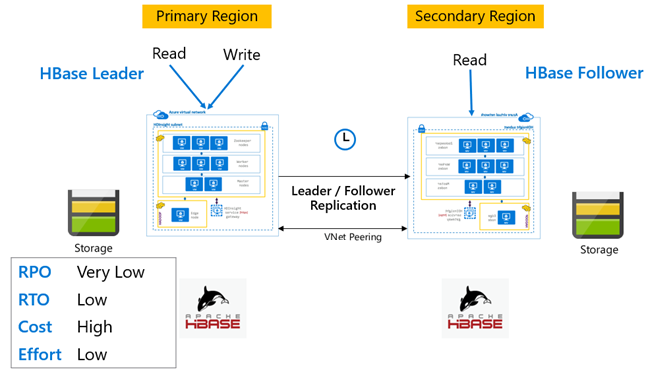
HBase 복제: Leader – Follower 모델
이 영역 간 설정의 복제는 주 영역에서 보조 영역으로 진행되는 단방향입니다. 단방향 복제 시 주 영역의 모든 테이블 또는 특정 테이블을 식별할 수 있습니다. 정상 작동 중에는 보조 클러스터를 사용하여 자체 영역에서 읽기 요청을 처리할 수 있습니다.
보조 클러스터는 자체 테이블을 호스트할 수 있고 영역 애플리케이션에서 읽기와 쓰기를 제공할 수 있는 일반적인 HBase 클러스터로 작동합니다. 그러나 복제된 테이블이나 보조 클러스터에 대한 기본 테이블의 쓰기 작업은 주 클러스터에 다시 복제되지 않습니다.
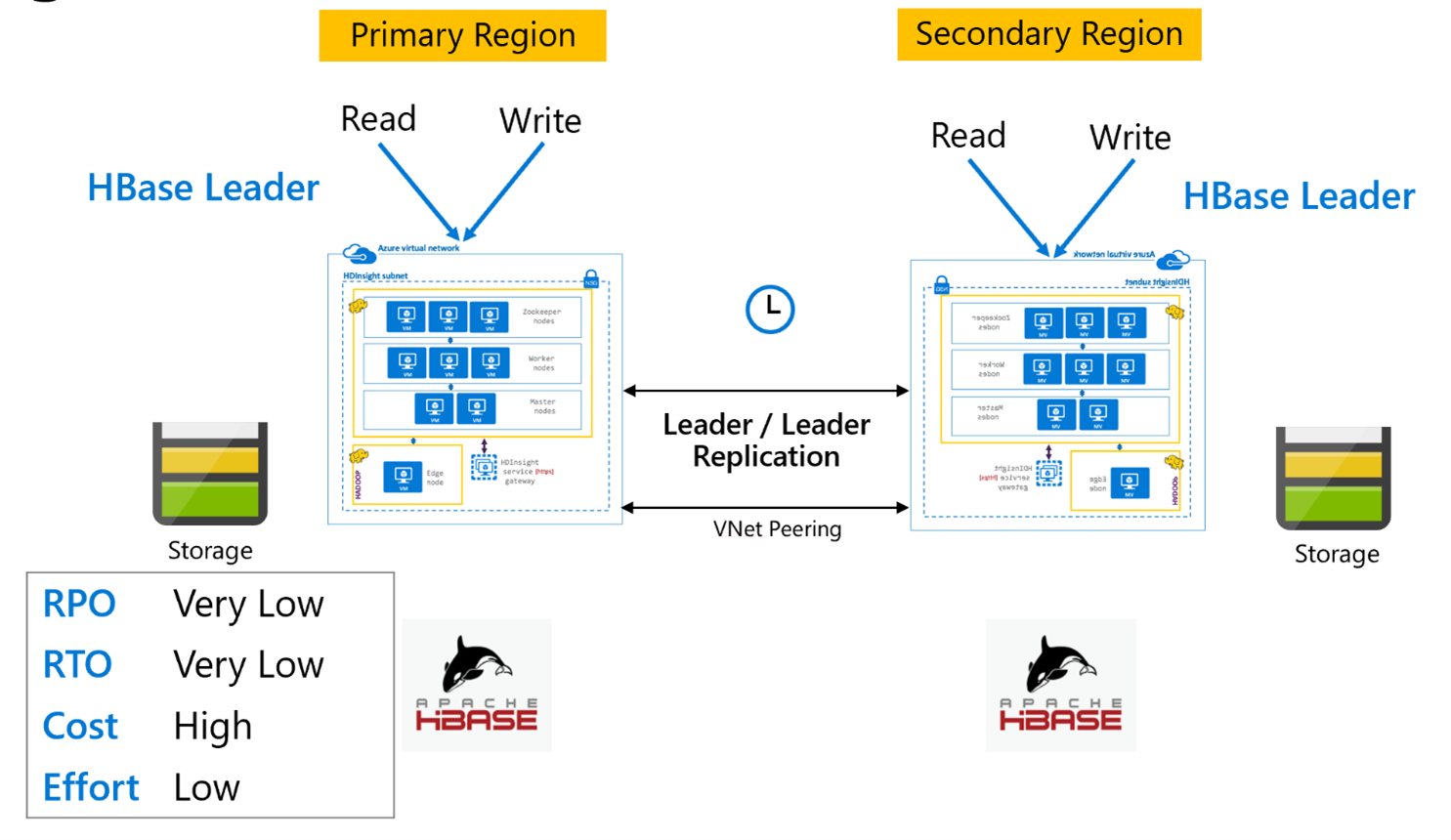
HBase 복제: Leader – Leader 모델
이 영역 간 설정은 복제가 주 영역과 보조 영역 사이에서 양방향으로 발생한다는 점을 제외하고는 단방향 설정과 매우 유사합니다. 애플리케이션은 읽기-쓰기 모드에서 두 클러스터를 모두 사용할 수 있고, 업데이트는 클러스터 간에 비동기적으로 교환됩니다.
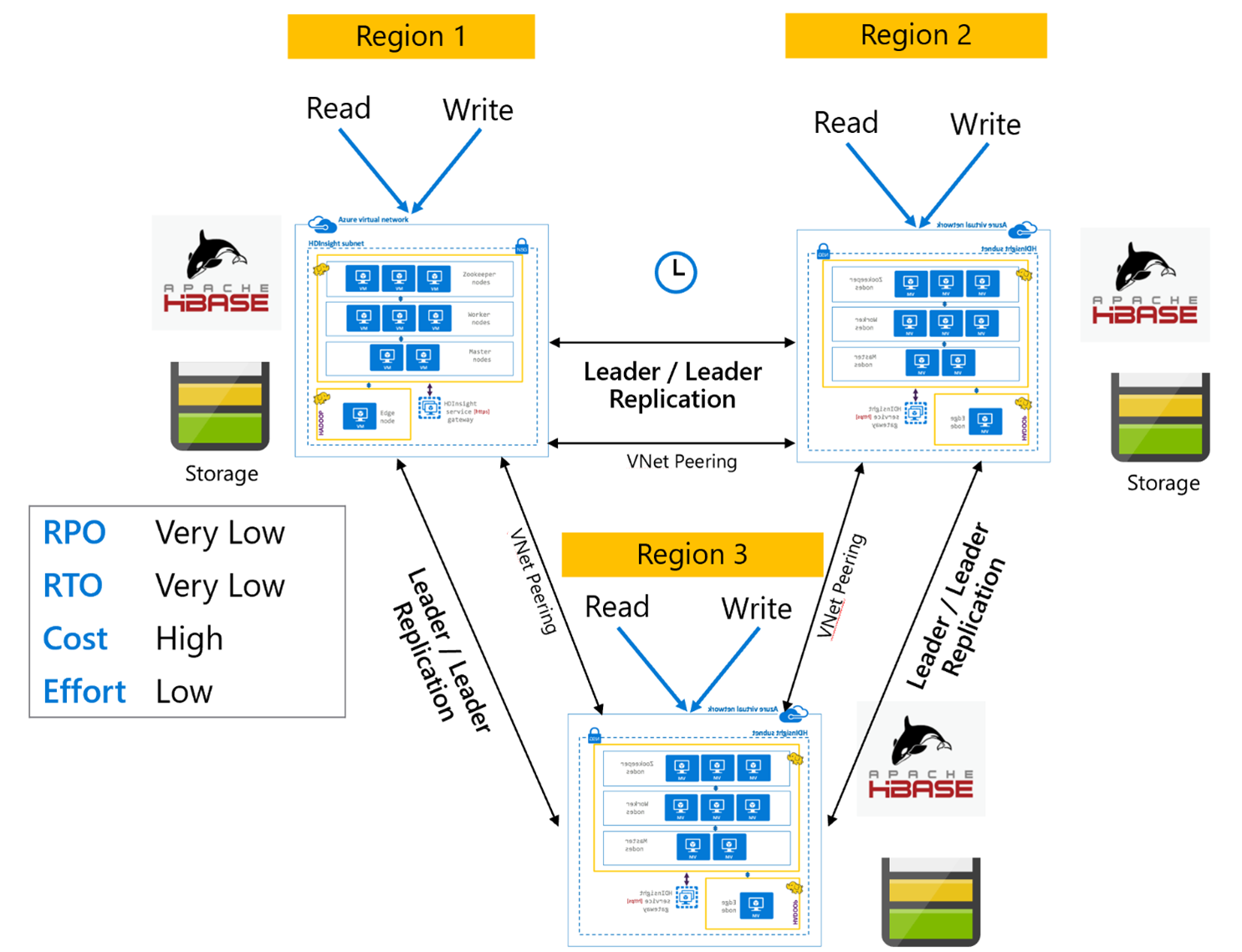
HBase 복제: Multi-Region 또는 Cyclic
Multi-Region/Cyclic 복제 모델은 HBase 복제의 확장으로, 영역별 HBase 클러스터를 읽고 쓰는 애플리케이션이 여러 개인 전역 중복 HBase 아키텍처를 만드는 데 사용할 수 있습니다. 클러스터는 비즈니스 요구 사항에 따라 Leader/Leader 또는 Leader/Follower의 다양한 조합으로 설정할 수 있습니다.
Apache Kafka
영역 간 가용성을 사용하도록 설정하기 위해 HDInsight 4.0에서는 Kafka MirrorMaker를 지원합니다. Kafka MirrorMaker는 다른 영역에서 주 Kafka 클러스터의 보조 복제본을 유지 관리하는 데 사용될 수 있습니다. MirrorMaker는 상위 수준 소비자-생산자 쌍 역할을 하고, 주 클러스터의 특정 토픽에서 사용되며, 보조 클러스터에서 이름이 동일한 토픽을 생성합니다. 고가용성 재해 복구 시 MirrorMaker를 사용하는 클러스터 간 복제는 생산자와 소비자가 복제본 클러스터로 장애 조치(failover)해야 한다는 가정하에 제공됩니다. 자세한 정보는 MirrorMaker를 사용하여 HDInsight에서 Kafka로 Apache Kafka 토픽 복제를 참조하세요.
복제가 시작된 경우 토픽 수명에 따라 MirrorMaker 토픽 복제로 인해 원본 토픽과 복제본 토픽 간에 서로 다른 오프셋이 발생할 수 있습니다. HDInsight Kafka 클러스터는 개별 클러스터 수준에서 고가용성 기능인 토픽 파티션 복제도 지원합니다.
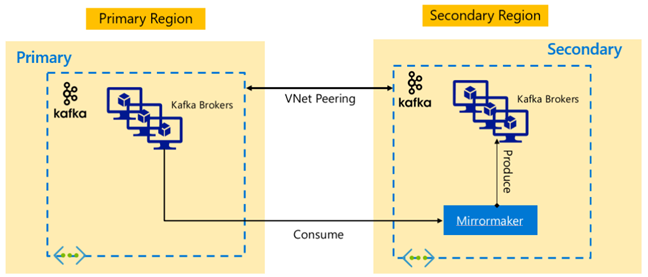
Apache Kafka 아키텍처
Kafka 복제: Active – Passive
Active-Passive 설정을 사용하면 비동기 단방향 미러링을 Active에서 Passive로 설정할 수 있습니다. 생산자와 소비자는 Active 및 Passive 클러스터의 존재에 대해 알고 있어야 하며, Active에서 실패하는 경우 Passive로 장애 조치(failover)할 준비가 되어 있어야 합니다. 다음은 Active-Passive 설정의 장단점입니다.
장점:
- 클러스터 간의 네트워크 대기 시간이 Active 클러스터의 성능에 영향을 주지 않습니다.
- 단방향 복제의 단순성
단점:
- Passive 클러스터가 잘 활용되지 않는 상태를 유지할 수 있습니다.
- 애플리케이션 생산자와 소비자에 대한 장애 조치(failover) 인식 기능을 통합하는 설계의 복잡성
- Active 클러스터에 오류가 발생하면 데이터가 손실될 수 있습니다.
- Active 클러스터와 Passive 클러스터 사이 항목 간의 결과적 일관성
- 주 클러스터로 장애 복구(failback)하면 토픽에서 메시지 불일치가 발생할 수 있습니다.
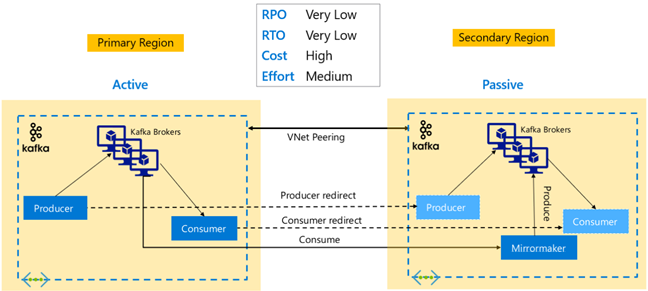
Kafka 복제: Active – Active
Active-Active 설정에는 MirrorMaker를 통해 양방향 비동기 복제를 사용하는, 두 영역으로 구분된 VNet 피어링 HDInsight Kafka 클러스터가 포함됩니다. 이 설계에서 주 클러스터의 소비자가 사용하는 메시지는 보조 클러스터의 소비자가 사용할 수도 있고, 그 반대의 경우도 가능합니다. 다음은 Active-Active 설정의 장단점입니다.
장점:
- 중복 상태이기 때문에 장애 조치(failover) 및 장애 복구(failback)를 실행하기가 더 쉽습니다.
단점:
- 설정, 관리 및 모니터링이 Active-Passive보다 더 복잡합니다.
- 순환 복제의 문제를 해결해야 합니다.
- 양방향 복제는 더 높은 영역 데이터 송신 비용을 발생시킵니다.
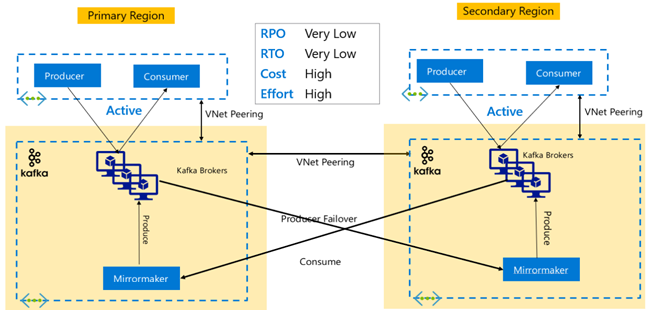
HDInsight Enterprise Security Package
이 설정은 사용자가 주/보조 클러스터에서 모두 다중 사용자 기능을 사용하고, 사용자가 두 클러스터에 대해 인증할 수 있도록 Microsoft Entra Domain Services 복제 세트를 사용하도록 설정하는 데 이용됩니다. 정상 작동 중에 사용자의 작업을 읽기 작업으로 제한하도록 보조 클러스터에 Ranger 정책을 설정해야 합니다. 아래의 아키텍처는 ESP를 사용하는 Hive Active Primary – Standby Secondary 설정의 표시 방법을 설명합니다.
Ranger Metastore 복제:
Ranger Metastore는 데이터 권한 부여를 제어하기 위한 Ranger 정책을 영구적으로 저장하고 제공하는 데 사용됩니다. 주/보조 클러스터에서 독립된 Ranger 정책을 유지하고 보조 클러스터를 읽기 복제본으로 유지하는 것이 좋습니다.
Ranger 정책을 주/보조 클러스터 간에 동기화된 상태로 유지해야 하는 경우, Ranger Import/Export를 사용하여 주기적으로 Ranger 정책을 백업하고 주 클러스터에서 보조 클러스터로 가져옵니다.
주/보조 클러스터 간에 Ranger 정책을 복제하면 보조 클러스터에서 쓰기를 사용하도록 설정될 수 있으며, 이로 인해 보조 클러스터에서 실수로 쓰기가 발생하여 데이터 불일치를 초래할 수 있습니다.
다음 단계
이 문서에서 설명한 항목에 관해 자세히 알아보려면 다음을 참조하세요.