Insights를 사용하여 단일 Azure Stack HCI 클러스터 모니터링
적용 대상: Azure Stack HCI, 버전 22H2
이 문서에서는 Insights를 사용하여 단일 Azure Stack HCI 클러스터를 모니터링하는 방법을 설명합니다. 여러 Azure Stack HCI 클러스터의 경우 Insights를 사용하여 여러 Azure Stack HCI 클러스터 모니터링을 참조 하세요.
Insights는 Azure Stack HCI 클러스터 모니터링을 빠르게 시작하는 Azure Monitor의 기능입니다. 클러스터, 서버, 가상 머신 및 스토리지와 관련된 주요 메트릭, 상태 및 사용량 정보를 볼 수 있습니다.
Important
2023년 11월 이전에 Azure Stack HCI 클러스터를 등록하고 Insights를 구성한 경우 서버용 Arc, VM Insights, 클라우드용 Defender 또는 Sentinel과 같은 AMA(Azure Monitor 에이전트)를 사용하는 특정 기능이 로그 및 이벤트 데이터를 올바르게 수집하지 못할 수 있습니다. 문제 해결 지침은 2023년 11월 이전에 등록된 클러스터 문제 해결 섹션을 참조하세요.
이점
Azure Stack HCI에 대한 인사이트는 다음과 같은 이점을 제공합니다.
Azure에서 관리합니다. 인사이트는 Azure에서 관리되며 Azure Portal을 통해 액세스되어 항상 최신 상태인지 확인합니다. 데이터베이스 또는 특수 소프트웨어 설정은 필요하지 않습니다.
확장성. Insights는 여러 구독에서 400개가 넘는 클러스터 정보 집합을 동시에 로드할 수 있습니다. 클러스터, 도메인 또는 물리적 위치에는 제한이 없습니다.
사용자 지정 기능. Insight의 환경은 Azure Monitor 통합 문서 템플릿을 기반으로 합니다. 이렇게 하면 보기 및 쿼리를 변경하고, 특정 제한에 맞는 임계값을 수정하거나 설정한 다음, 이러한 사용자 지정을 통합 문서에 저장할 수 있습니다. 그런 다음 통합 문서의 차트를 Azure 대시보드에 고정할 수 있습니다.
Azure Stack HCI에 대한 인사이트 구성
Insights를 사용하기 위한 필수 구성 요소 및 설정은 사용 중인 Azure Stack HCI 버전에 따라 달라집니다. 특정 버전의 Azure Stack HCI에서 Insights를 사용하는 방법에 대한 지침은 다음 탭 중 하나를 선택합니다.
Azure Stack HCI 버전 22H2 이상의 Insights 기능은 Azure Stack HCI 버전 21H2 이하에서 사용되는 레거시 MMA(Microsoft Monitoring Agent)에 비해 상당한 이점을 제공하는 AMA를 사용합니다. 이러한 장점으로는 향상된 속도, 향상된 보안 및 뛰어난 성능이 있습니다. 새 노드를 AMA에 온보딩하거나 기존 노드를 레거시 에이전트에서 AMA로 마이그레이션 할 수 있습니다.
AMA를 사용하여 Insights 환경을 활용하려면 Azure Stack HCI 시스템을 버전 22H2 이상으로 업그레이드하는 것이 좋습니다.
Azure Stack HCI 버전 22H2에 대한 2023년 5월 누적 업데이트부터 Azure Stack HCI용 Insights를 사용하여 온-프레미스 Azure Stack HCI 시스템을 모니터링할 수 있습니다.
필수 조건
Azure Stack HCI용 Insights를 사용하기 위한 필수 구성 요소는 다음과 같습니다.
Azure Stack HCI 클러스터는 Azure 및 Arc 지원으로 등록해야 합니다. 2021년 6월 15일 이후에 클러스터를 등록한 경우 기본적으로 발생합니다. 그렇지 않으면 Azure Arc 통합을 사용하도록 설정해야 합니다.
클러스터에는 Azure Stack HCI 버전 22H2 및 2023년 5월 누적 업데이트 이상이 설치되어 있어야 합니다.
Azure 리소스에 대한 관리 ID를 사용하도록 설정해야 합니다. 자세한 내용은 향상된 관리 사용 기능을 참조하세요.
인사이트 사용
Insights를 사용하도록 설정하면 유용한 상태 메트릭을 제공하여 현재 Log Analytics 작업 영역과 연결된 모든 Azure Stack HCI 클러스터를 모니터링할 수 있습니다. Insights는 Azure Monitor 에이전트를 설치하고 Azure Stack HCI 클러스터를 모니터링하기 위한 DCR(데이터 수집 규칙)을 구성하는 데 도움이 됩니다.
Azure Portal에서 이 기능을 사용하도록 설정하려면 다음 단계를 수행합니다.
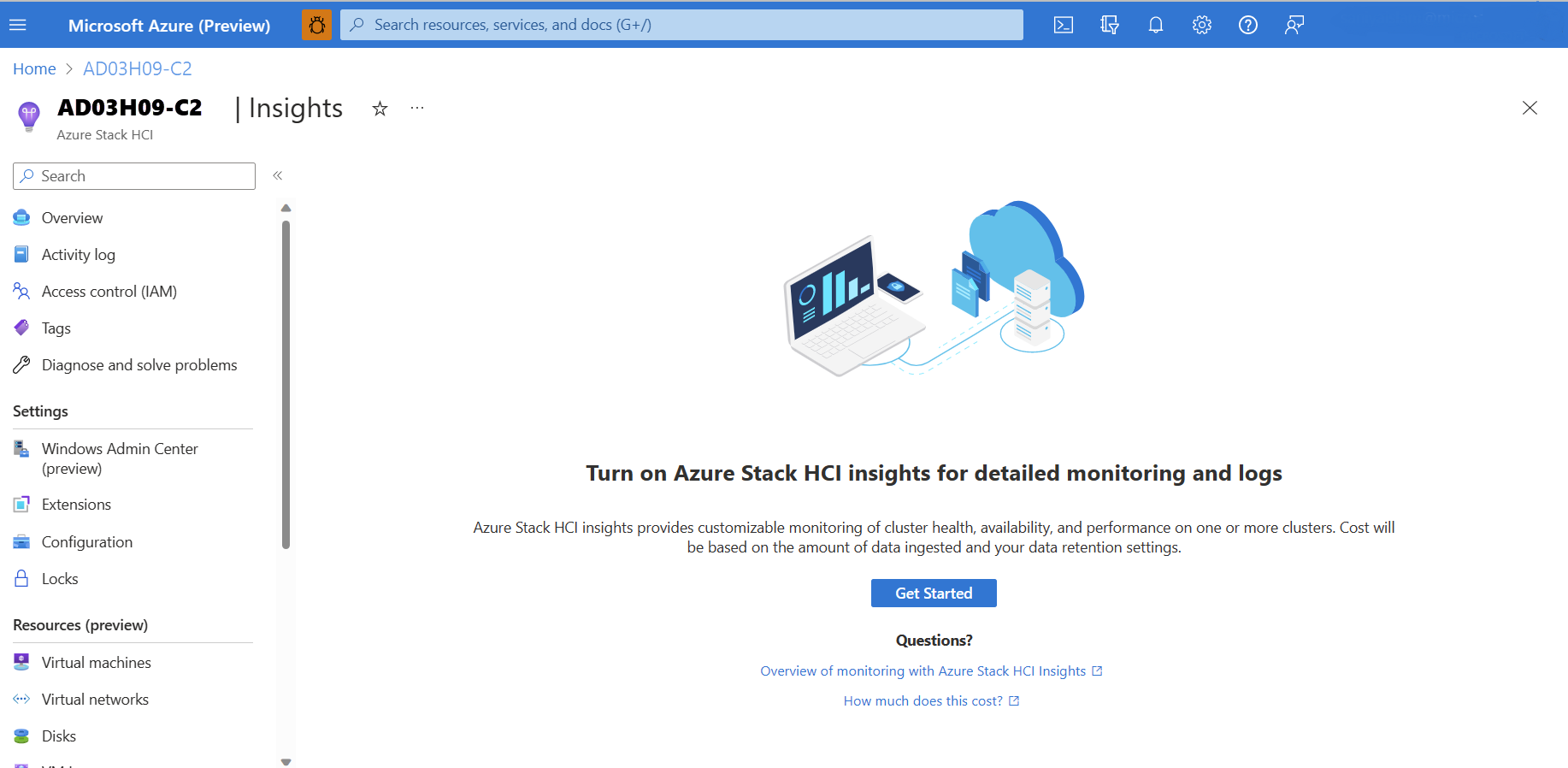
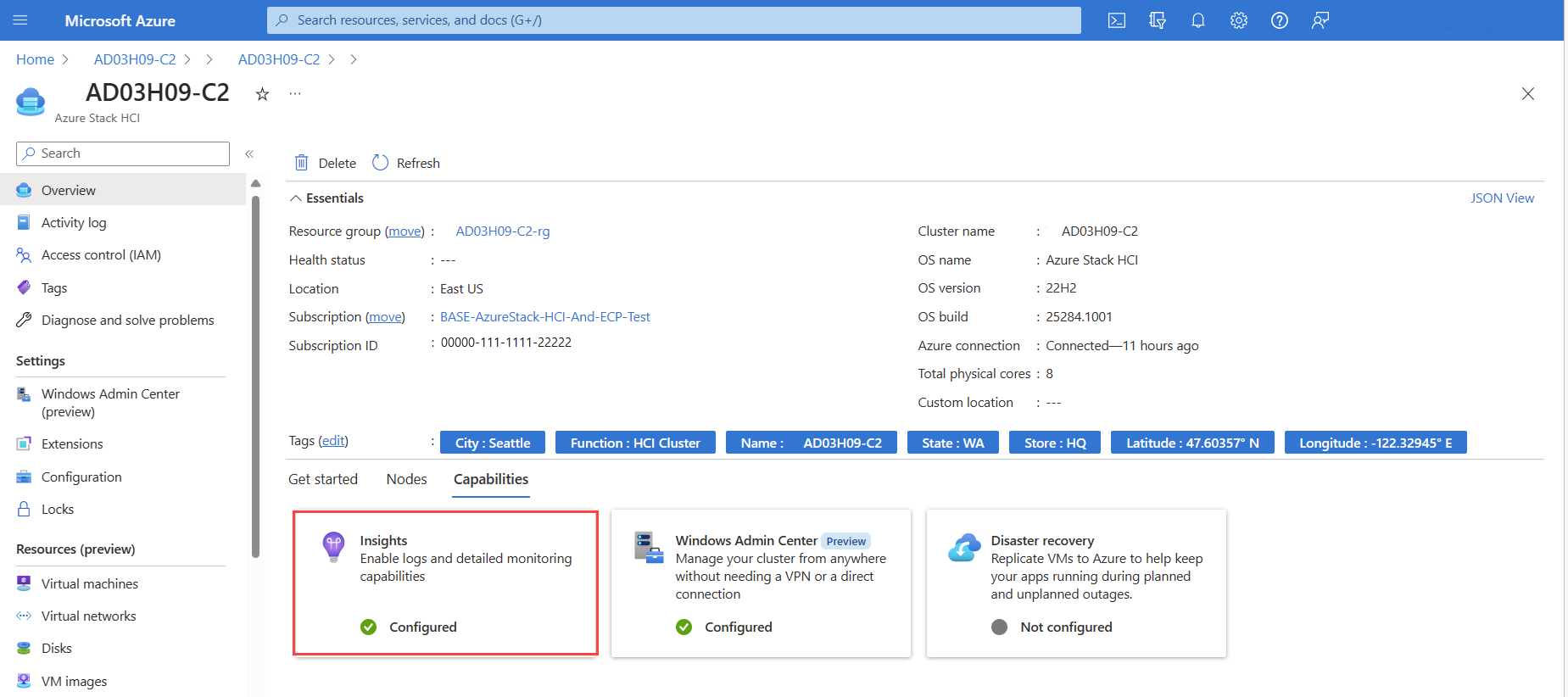
Azure Portal에서 Azure Stack HCI 클러스터 리소스 페이지로 이동한 다음 클러스터를 선택합니다. 기능 탭에서 인사이트를 선택합니다.

인사이트 페이지에서 시작 을 선택합니다.
참고 항목
시작 단추는 2023년 5월 누적 업데이트 이상이 설치된 Azure Stack HCI 버전 22H2에만 사용할 수 있으며 관리 ID를 사용하도록 설정한 후에만 사용할 수 있습니다. 그렇지 않으면 이 단추를 사용할 수 없습니다.
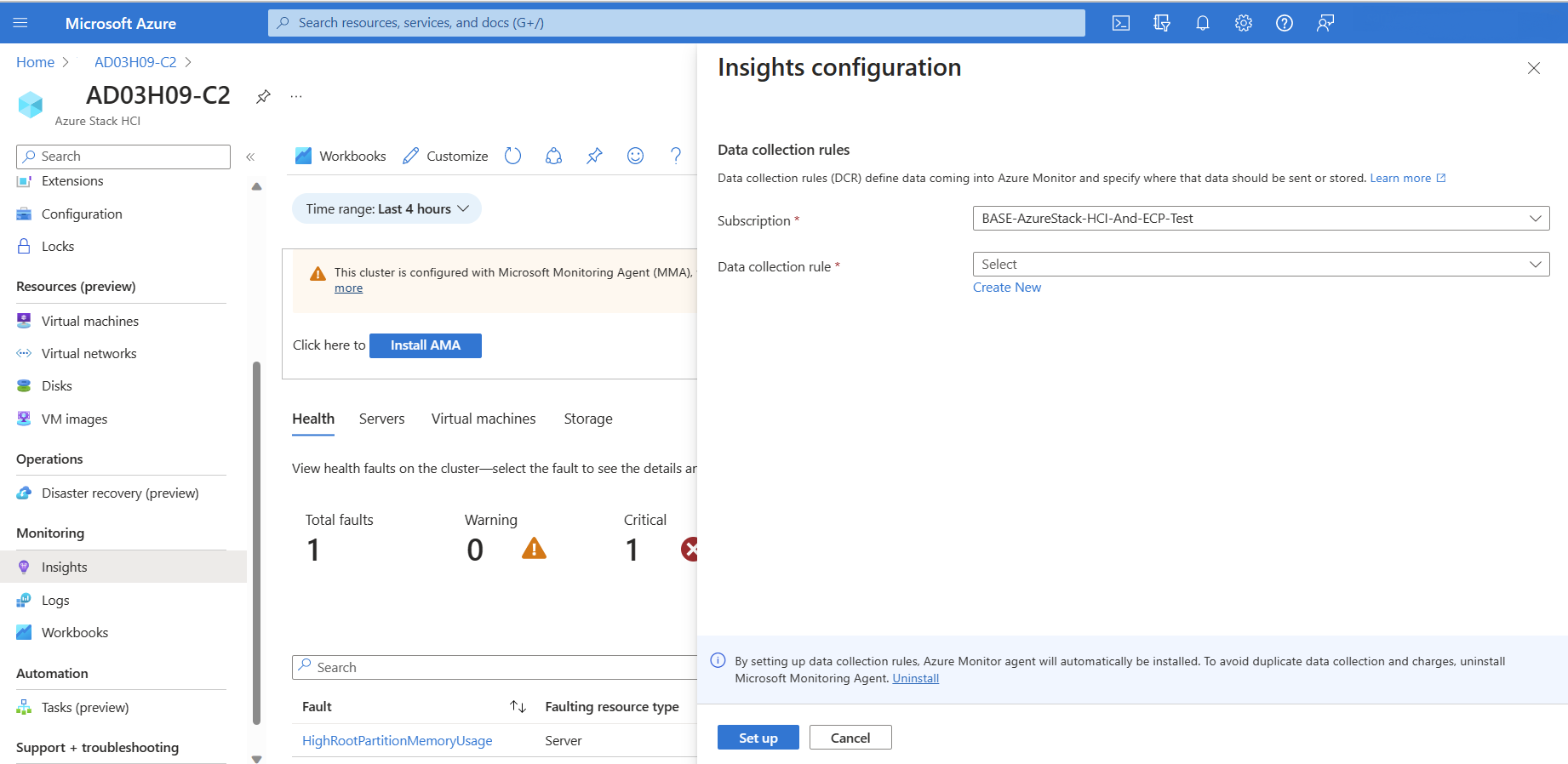
Insights 구성 페이지의 데이터 수집 규칙 드롭다운에서 기존 DCR을 선택합니다. DCR은 수집해야 하는 이벤트 로그 및 성능 카운터를 지정하고 Log Analytics 작업 영역에 저장합니다. Insights는 아직 존재하지 않는 경우 기본 DCR을 만듭니다. Insights에 사용하도록 설정된 DCR만 포함됩니다.
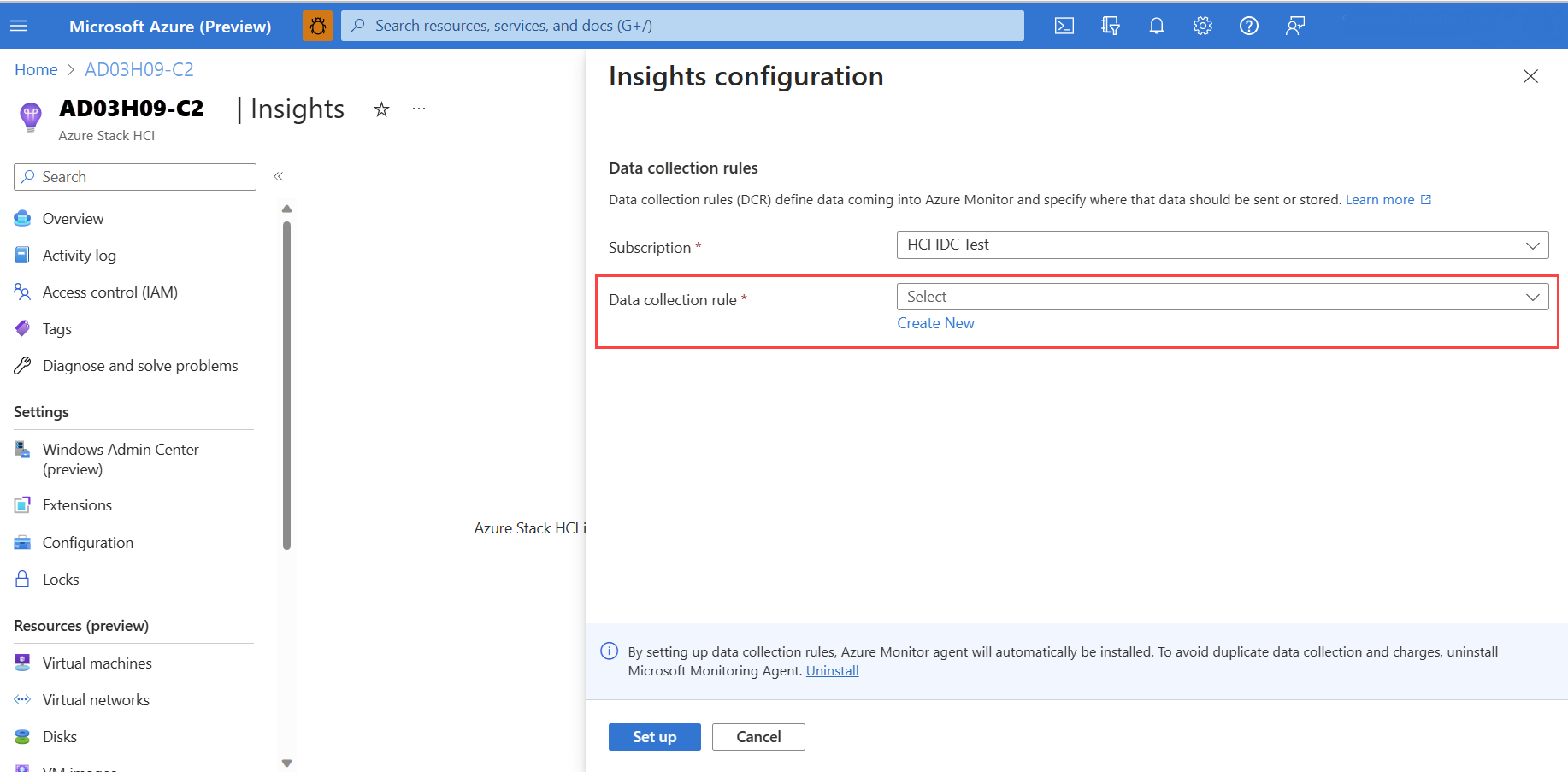
(선택 사항) Insights 구성 페이지에서 새로 만들기를 선택하여 새 DCR을 만들 수도 있습니다.
Important
고유한 DCR을 만들지 않는 것이 좋습니다. Insights에서 만든 DCR에는 작업에 필요한 특수 데이터 스트림이 포함되어 있습니다. 이 DCR을 편집하여 Windows 및 Syslog 이벤트와 같은 더 많은 데이터를 수집할 수 있습니다. AMA 설치를 통해 만든 DCR에는 DCR 이름과 연결된 접두
AzureStackHCI-사를 갖습니다.새 데이터 수집 규칙 페이지에서 구독, DCR 이름 및 DCE(데이터 수집 엔드포인트) 이름을 지정합니다. DCE는 구성 서비스에 액세스하여 Azure Monitor 에이전트에 연결된 DCR을 가져오는 데 사용됩니다. DCE에 대한 자세한 내용은 Azure Monitor의 데이터 수집 엔드포인트를 참조하세요.
참고 항목
에이전트에서 프라이빗 링크를 사용하는 경우 DCE를 추가해야 합니다. AMA 네트워크 설정에 대한 자세한 내용은 Azure Monitor 에이전트 네트워크 설정 정의를 참조 하세요.
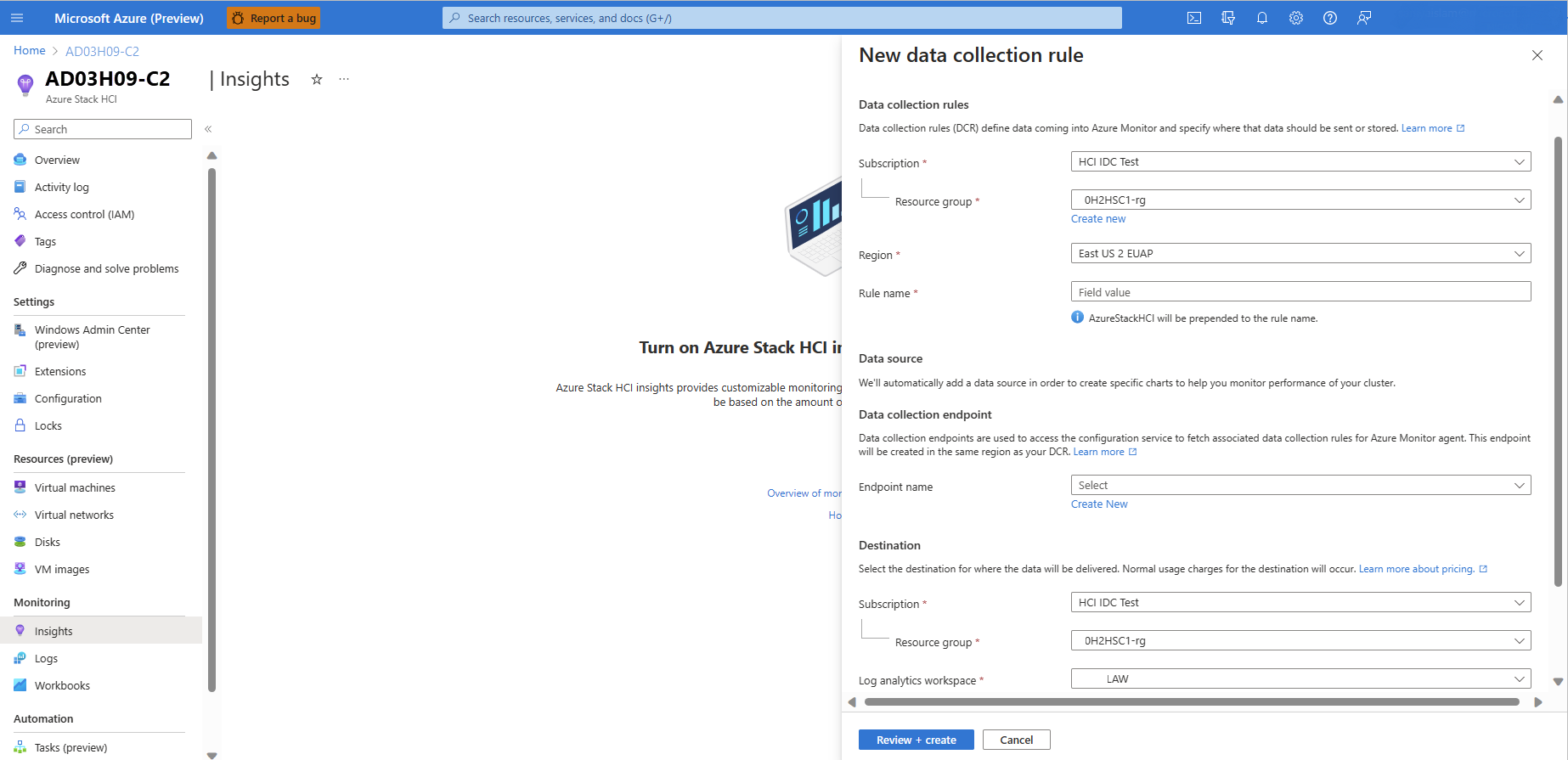
검토 + 만들기 단추를 선택합니다.
모니터링되지 않는 클러스터에 대해 DCR을 아직 만들지 않은 경우 성능 카운터를 사용하도록 설정하고 Windows 이벤트 로그 채널을 사용하도록 설정하여 DCR을 만듭니다.
DCR 이름, 이벤트 로그 수, 성능 카운터 및 데이터가 저장되는 Log Analytics 작업 영역의 이름을 요약하여 최종 화면을 검토합니다. 설정을 선택합니다.
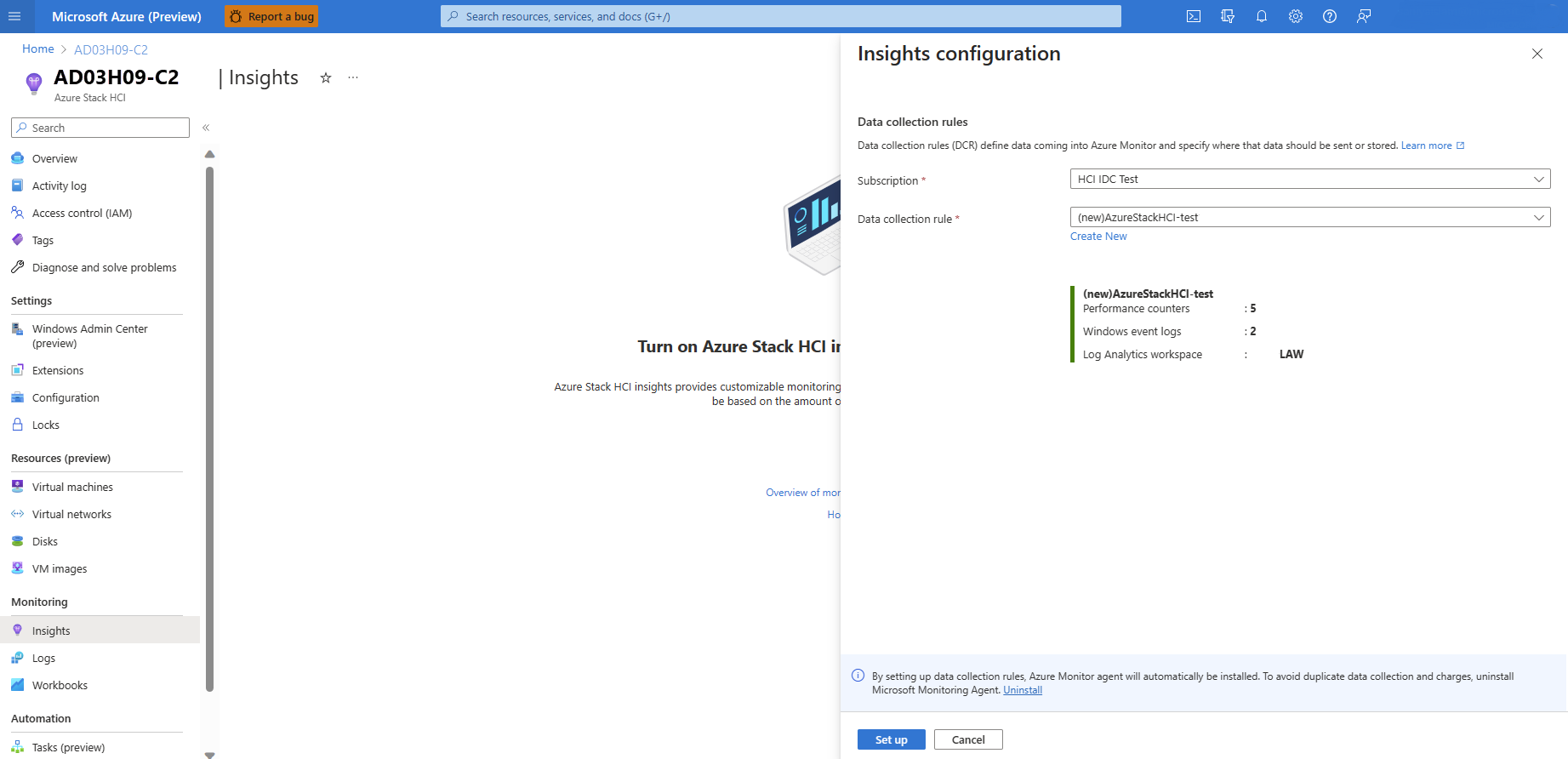
설정을 선택하면 확장 페이지로 리디렉션됩니다. 여기서 에이전트 설치 상태를 볼 수 있습니다. Insights를 구성하면 AMA가 클러스터의 모든 노드에 자동으로 설치됩니다.
Azure Stack HCI 클러스터 리소스 페이지로 이동한 다음 클러스터를 선택합니다. 이제 인사이트가 기능 탭에 구성된 것으로 표시됩니다.






데이터 수집 규칙
Azure Monitor 에이전트를 사용하여 컴퓨터에서 Insights를 사용하도록 설정하는 경우 사용할 DCR을 지정해야 합니다. DCR에 대한 자세한 내용은 Azure Monitor의 데이터 수집 규칙을 참조하세요.
| 옵션 | 설명 |
|---|---|
| 성능 카운터 | 운영 체제에서 수집할 데이터 성능 카운터를 지정합니다. 이 옵션은 모든 컴퓨터에 필요합니다. 이러한 성능 카운터는 Insights 통합 문서의 시각화를 채우는 데 사용됩니다. 현재 Insights 통합 문서에서는 5개의 성능 카운터Memory()\Available Bytes(, , Network Interface()\Bytes Total/secProcessor(_Total)\% Processor TimeRDMA Activity()\RDMA Inbound Bytes/sec및)를 사용합니다.RDMA Activity()\RDMA Outbound Bytes/sec |
| 이벤트 로그 채널 | 운영 체제에서 수집할 Windows 이벤트 로그를 지정합니다. 이 옵션은 모든 컴퓨터에 필요합니다. Windows 이벤트 로그는 Insights 통합 문서의 시각화를 채우는 데 사용됩니다. 현재 데이터는 다음과 같은 두 개의 Windows 이벤트 로그 채널을 통해 수집됩니다. - microsoft-windows-health/operationalmicrosoft-windows-sddc-management/operational |
| Log Analytics 작업 영역 | 데이터를 저장할 작업 영역입니다. 인사이트가 있는 작업 영역만 나열됩니다. |
이벤트 채널
Microsoft-windows-sddc-management/operational Windows 이벤트 채널과 Microsoft-windows-health/operational Windows 이벤트 채널은 Windows 이벤트 로그 아래에 Log Analytics 작업 영역에 추가됩니다.

이러한 로그를 수집하여 Insights는 개별 서버, 드라이브, 볼륨 및 VM의 상태를 표시합니다. 기본적으로 5개의 성능 카운터가 추가됩니다.
성능 카운터
기본적으로 5개의 성능 카운터가 추가됩니다.

다음 표에서는 모니터링되는 성능 카운터에 대해 설명합니다.
| 성능 카운터 | 설명 |
|---|---|
| Memory(*)\Available Bytes | 사용 가능한 바이트는 프로세스에 할당하거나 시스템 사용을 위해 즉시 사용할 수 있는 실제 메모리 양(바이트)입니다. |
| Network Interface(*)\Bytes Total/sec | 프레이밍 문자를 포함하여 각 네트워크 어댑터를 통해 바이트를 보내고 받는 속도입니다. Bytes Total/sec는 Bytes Received/sec 및 Bytes Sent/sec의 합계입니다. |
| Processor(_Total)% Processor Time | 모든 프로세스 스레드가 프로세서를 사용하여 명령을 실행하는 데 사용한 경과된 시간의 백분율입니다. |
| RDMA 작업(*)\RDMA 인바운드 바이트/초 | 초당 네트워크 어댑터에 의해 RDMA를 통해 수신되는 데이터의 비율입니다. |
| RDMA 작업(*)\RDMA 아웃바운드 바이트/초 | 초당 네트워크 어댑터에 의해 RDMA를 통해 전송되는 데이터의 비율입니다. |
Insights를 사용하도록 설정한 후 데이터를 수집하는 데 최대 15분이 걸릴 수 있습니다. 프로세스가 완료되면 왼쪽 창의 인사이트 메뉴에서 클러스터의 상태를 다양하게 시각화할 수 있습니다.

인사이트 사용 안 함
Insights를 사용하지 않도록 설정하려면 다음 단계를 수행합니다.
기능 탭에서 인사이트를 선택합니다.
인사이트 사용 안 함 선택


Insights 기능을 사용하지 않도록 설정하면 데이터 수집 규칙과 클러스터 간의 연결이 삭제되고 상태 관리 서비스 및 SDDC 관리 로그가 더 이상 수집되지 않지만 기존 데이터는 삭제되지 않습니다. 해당 데이터를 삭제하려면 DCR 및 Log Analytics 작업 영역으로 이동하여 데이터를 수동으로 삭제합니다.
Insights 업데이트
Insights 타일은 다음과 같은 경우에 업데이트 필요 메시지를 표시합니다.
- 데이터 수집 규칙이 변경됩니다.
- Windows 이벤트 로그의 상태 이벤트가 삭제됩니다.
- Log Analytics 작업 영역에서 5개의 성능 카운터 중 어느 것이든 삭제됩니다.
Insights를 다시 사용하도록 설정하려면 다음 단계를 수행합니다.
기능에서 Insights 타일을 선택합니다.
업데이트를 선택하여 시각화를 다시 확인합니다.
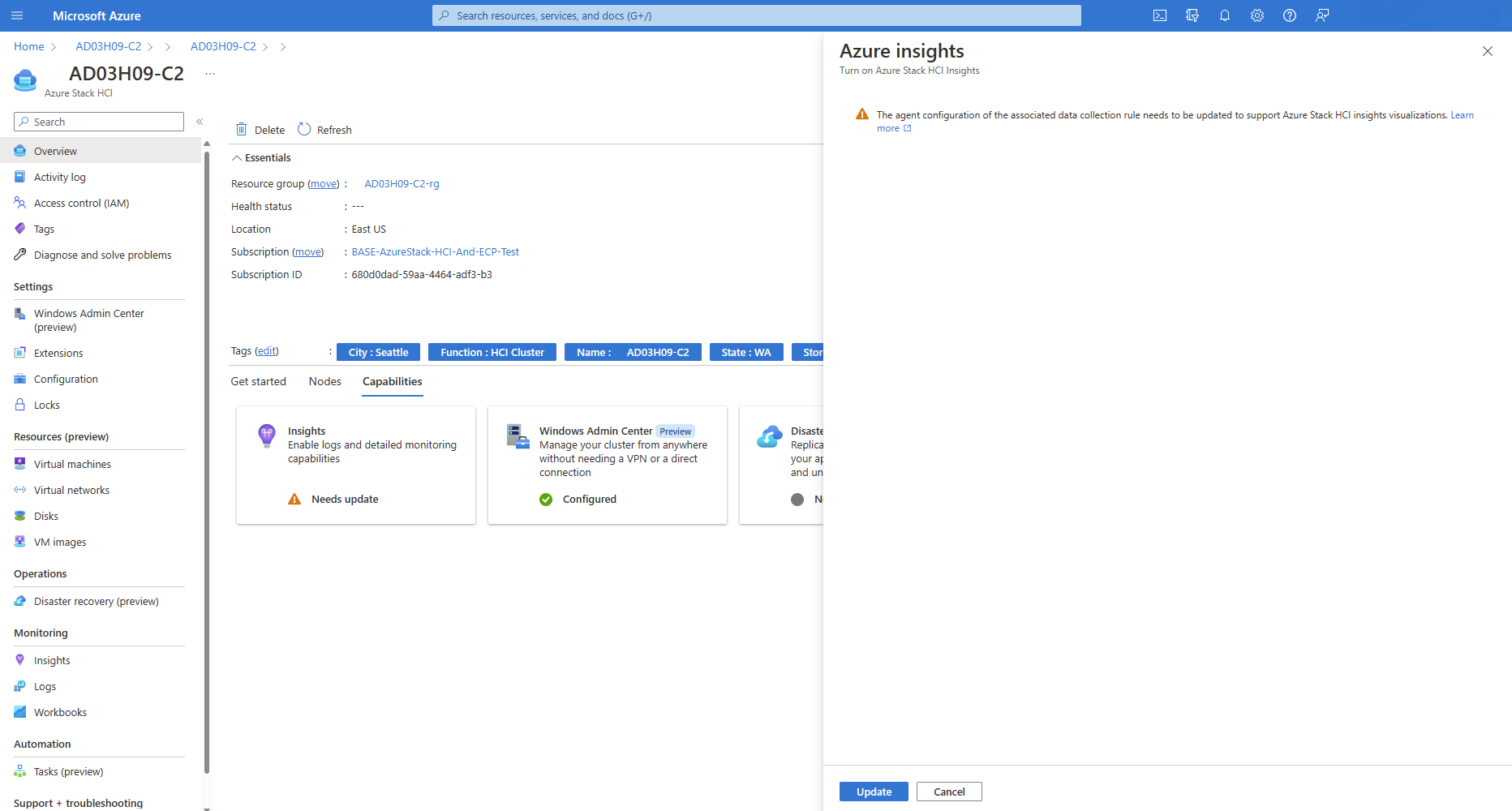

Microsoft Monitoring Agent에서 마이그레이션
MMA(Microsoft Monitoring Agent)에서 AMA(Azure Monitoring Agent)로 마이그레이션하려면 아래로 스크롤하여 Insights로 스크롤합니다.
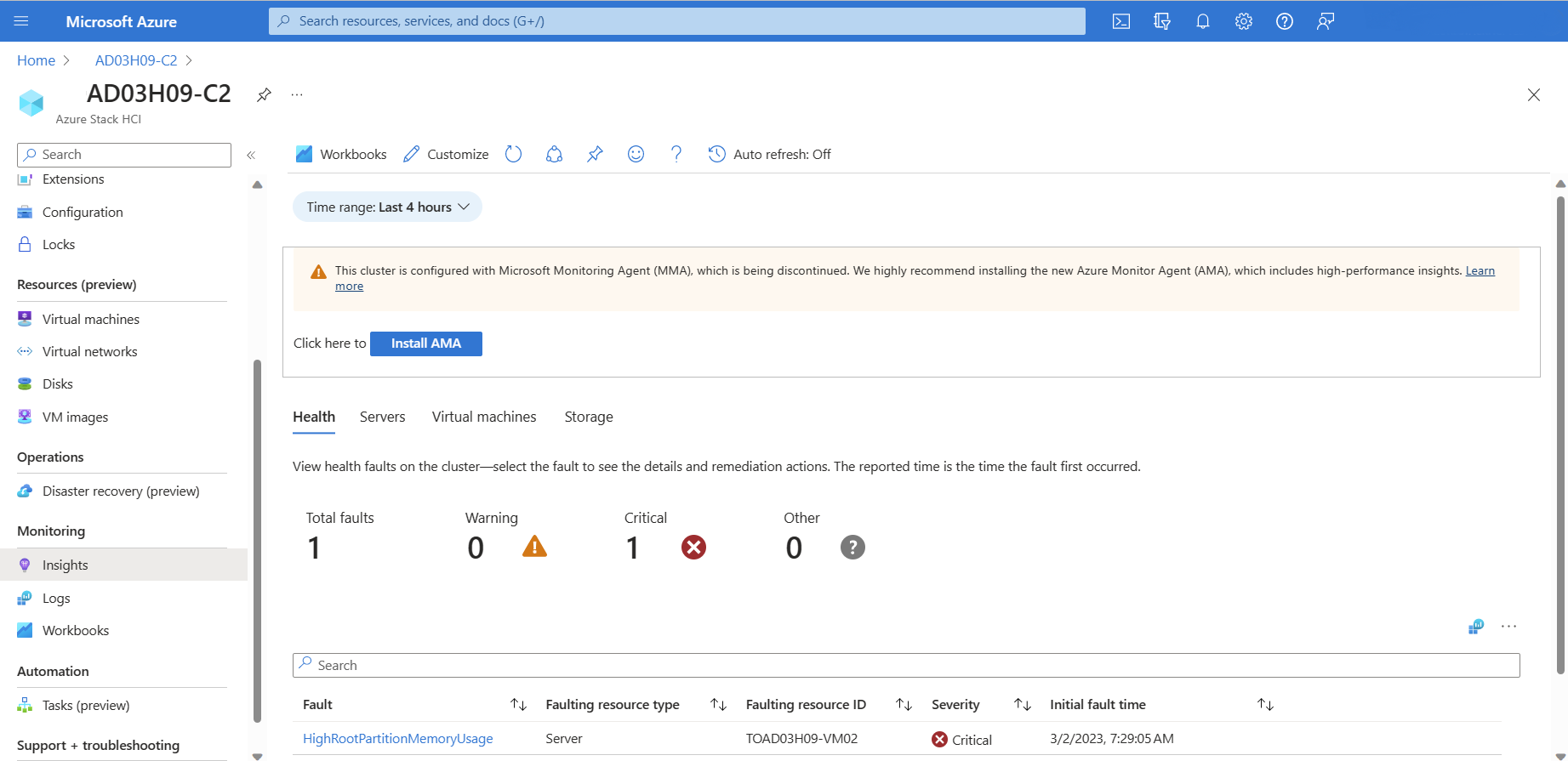
AMA 설치를 선택합니다. 인사이트 구성 창이 열립니다.


Azure Monitor 에이전트와 Microsoft Monitoring Agent 확장은 모두 마이그레이션 중에 동일한 컴퓨터에 설치할 수 있습니다. 두 에이전트를 모두 실행하면 데이터가 중복되고 비용이 증가할 수 있습니다. 컴퓨터에 두 에이전트가 모두 설치된 경우 다음 스크린샷과 같이 중복 데이터를 수집할 수 있다는 경고가 Azure Portal에 표시됩니다.
Warning
Azure Monitor 에이전트와 Microsoft Monitoring Agent 확장을 모두 사용하여 단일 컴퓨터에서 중복 데이터를 수집하면 중복 데이터를 Log Analytics 작업 영역으로 보내는 데 추가 수집 비용이 발생할 수 있습니다.

Microsoft Monitoring Agent 확장을 사용하는 컴퓨터에서 직접 제거해야 합니다. 이 단계를 수행하기 전에 컴퓨터가 Microsoft Monitoring Agent가 필요한 다른 솔루션에 의존하지 않는지 확인합니다. MicrosoftMonitoringAgent가 Log Analytics 작업 영역에 아직 연결되어 있지 않은지 확인한 후 확장 페이지로 리디렉션하여 MicrosoftMonitoringAgent를 수동으로 제거할 수 있습니다.

문제 해결
이 섹션에서는 Azure Stack HCI용 Insights를 사용하는 문제를 해결하기 위한 지침을 제공합니다.
2023년 11월 이전에 등록된 클러스터 문제 해결
출판하다. 2023년 11월 이전에 등록된 클러스터에서 서버용 Arc, VM Insights, Container Insights, 클라우드용 Defender 및 Sentinel과 같은 Azure Stack HCI에서 AMA를 사용하는 기능이 로그 및 이벤트 데이터를 제대로 수집하지 못할 수 있습니다.
원인. 2023년 11월 이전에 클러스터 등록은 클러스터 ID를 사용하도록 AMA를 구성했으며, Azure Stack HCI에서 AMA를 사용하는 서비스는 적절한 로그 수집을 위해 클러스터 노드의 ID를 필요로 했습니다. 이 불일치로 인해 이러한 서비스에서 잘못된 로그 수집이 발생했습니다.
해결 방법. 이 문제를 해결하기 위해 서버 ID를 대신 사용하도록 AMA에 대한 HCI 클러스터 등록을 변경했습니다. 이 변경을 구현하려면 2023년 11월 이전에 등록된 클러스터에서 다음 단계를 수행합니다.
- 클러스터 등록을 복구합니다. 클러스터 등록 복구를 참조하세요.
- AMA를 복구합니다. AMA 복구를 참조하세요.
- Azure Stack HCI에 대한 인사이트를 다시 구성합니다. Azure Stack HCI에 대한 인사이트 다시 구성을 참조하세요.
Azure Portal에서 Azure Stack HCI용 Insights 페이지는 AMA 구성의 변경 사항을 자동으로 검색하고 페이지 맨 위에 배너를 표시하여 AMA를 사용하는 서비스를 계속 사용하는 데 필요한 조치를 취하도록 안내합니다.

클러스터 등록 복구
클러스터 등록을 복구하려면 다음 단계를 수행합니다.
클러스터 노드에서 최신
Az.StackHCIPowerShell 모듈을 설치합니다. 최신Az.StackHCI버전 번호로 바꿉latestversion다.Install-Module -Name Az.StackHCI -RequiredVersion {latestversion} -Scope CurrentUser -Repository PSGallery -Force복구 등록 명령을 실행하여 regkey를 제거합니다.
Register-AzStackHCI -TenantId {TenantID} -SubscriptionId {subscriptionID} -ComputerName {NodeName} -RepairRegistration
Azure Stack HCI용 AMA 복구
AMA를 복구하려면 다음 옵션 중 하나를 선택합니다.
옵션 1: AMA 제거
AMA가 이미 업데이트된 경우 제거합니다. AMA를 제거하려면 다음 단계를 수행합니다.
Azure Portal에서 Azure Stack HCI 클러스터의 확장 페이지로 이동합니다.
AzureMonitorWindowsAgent에 대한 확인란을 선택하고 제거를 선택합니다.

옵션 2: AMA 업데이트
AMA를 업데이트하려면 다음 단계를 수행합니다.
Azure Portal에서 Azure Stack HCI 클러스터의 확장 페이지로 이동합니다.
AzureMonitorWindowsAgent에 대한 확인란을 선택하고, 아직 수행되지 않은 경우 자동 업그레이드 사용을 선택합니다.
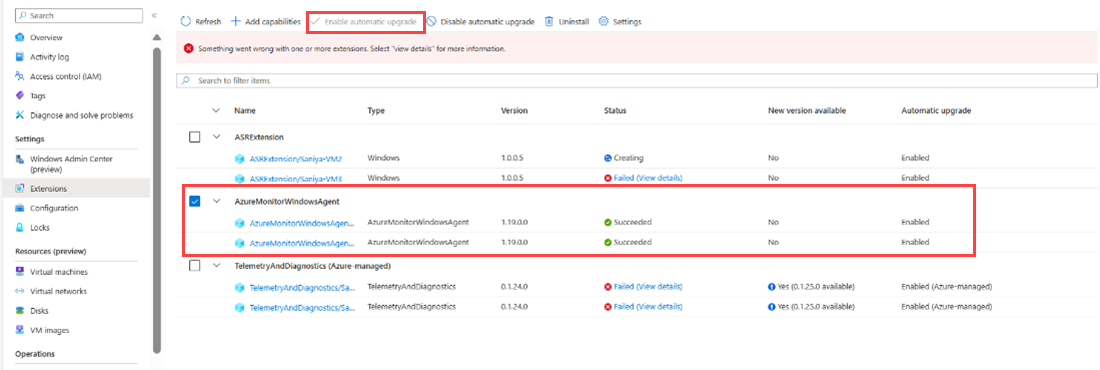
옵션 3: AMA 다시 시작
모든 클러스터 노드에서 다음 단계를 수행하여 AMA를 다시 시작합니다.
다음 명령을 실행하여 AMA를 사용하지 않도록 설정합니다.
cd C:\Packages\Plugins\Microsoft.Azure.Monitor.AzureMonitorWindowsAgent\<agent version number> AzureMonitorAgentExtension.exe disable실행 파일이 완료되고 모든 AMA 프로세스가 중지된 후 다음 명령을 실행하여 에이전트를 다시 시작합니다.
AzureMonitorAgentExtension.exe enable
옵션 4: 클러스터 노드 다시 부팅


Azure Stack HCI에 대한 인사이트 다시 구성
다음 단계에 따라 Azure Stack HCI에 대한 Insights를 다시 구성합니다.
Azure Portal의 Azure Stack HCI 클러스터에 대한 인사이트 페이지에는 다음 스크린샷과 같이 맨 위에 배너가 표시되어 Insights를 다시 구성하고 DCR을 클러스터 노드와 연결하는 데 도움이 됩니다. 배너를 검토하고 인사이트 구성을 선택합니다.
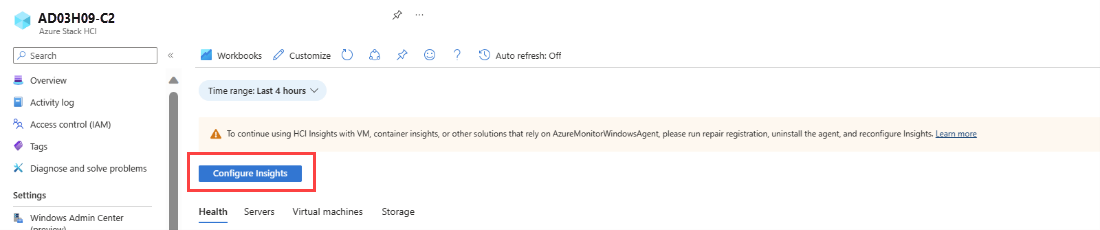
DCR을 다시 구성합니다. 지침에 따라 이 문서에 제공된 대로 Insights를 구성합니다. Azure Stack HCI에 대한 인사이트 구성을 참조하세요.
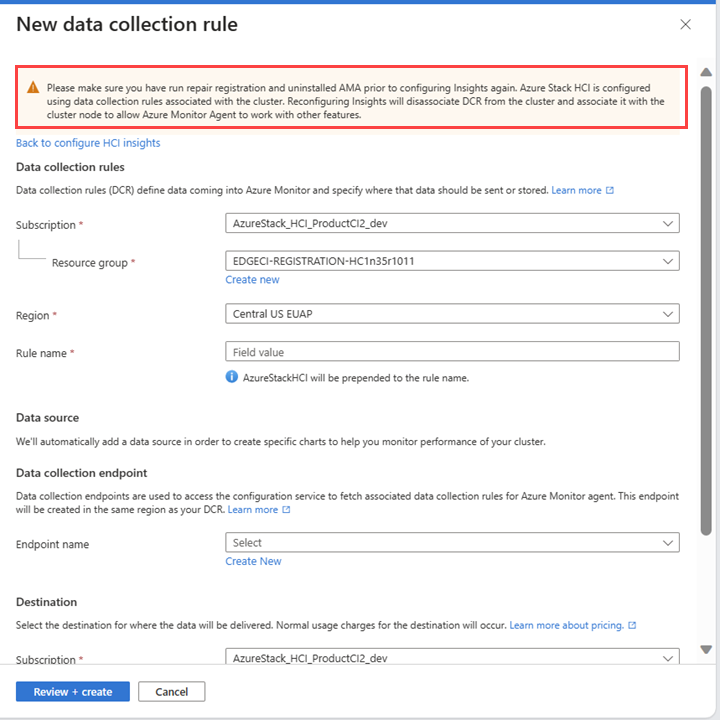


데이터가 채워지지 않은 빈 통합 문서 페이지 문제 해결
출판하다. 다음 스크린샷과 같이 데이터가 채워지지 않은 빈 통합 문서 페이지가 표시됩니다.

가능한 원인. 최근 Insights 구성, 2023년 11월 이전에 등록된 클러스터에 대한 불완전한 문제 해결 단계 또는 관련 DCR이 제대로 구성되지 않는 등 이 문제에 대한 몇 가지 가능한 원인이 있을 수 있습니다.
해결 방법. 이 문제를 해결하려면 다음 단계를 순서대로 수행합니다.
- 최근에 Insights를 구성한 경우 AMA가 데이터를 수집할 때까지 최대 1시간 동안 기다립니다.
- 대기한 후에도 데이터가 아직 없는 경우 2023년 11월 섹션 이전에 등록된 문제 해결 클러스터에 언급된 모든 단계를 완료했는지 확인합니다.
- 연결된 DCR의 구성을 확인합니다. 데이터 수집 규칙 섹션에 설명된 대로 이벤트 채널 및 성능 카운터가 연결된 DCR에 데이터 원본으로 추가되었는지 확인합니다.
- 위의 단계를 수행한 후에도 문제가 지속되고 데이터가 표시되지 않는 경우 고객 지원팀에 문의하여 도움을 요청하세요.
자세한 문제 해결 지침은 Azure Monitor 에이전트에 대한 문제 해결 지침을 참조하세요.











인사이트 시각화
Insights를 사용하도록 설정하면 다음 표에서 모든 리소스에 대한 세부 정보를 제공합니다.
건강
클러스터에 상태 오류를 제공합니다.
| 메트릭 | 설명 | 단위 | 예시 |
|---|---|---|---|
| 오류 | 상태 오류에 대한 간단한 설명입니다. 링크를 클릭하면 추가 정보가 포함된 측면 패널이 열립니다. | 단위 없음 | PoolCapacityThresholdExceeded |
| 오류 리소스 종류 | 오류가 발생한 리소스의 유형입니다. | 단위 없음 | StoragePool |
| 오류 리소스 ID | 상태 오류가 발생한 리소스의 고유 ID입니다. | 고유 ID | {a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1e1}: SP:{b1b1b1b1-cccc-dddd-eeee-f2f2f2f2f2f2f2} |
| 심각도 | 오류의 심각도는 경고 또는 위험일 수 있습니다. | 단위 없음 | Warning |
| 초기 오류 시간 | 서버가 마지막으로 업데이트된 시기의 타임스탬프입니다. | DateTime | 4/9/2022, 12:15:42 오후 |
서버
| 메트릭 | 설명 | 단위 | 예시 |
|---|---|---|---|
| 서버 | 클러스터에 있는 서버의 이름입니다. | 단위 없음 | VM-1 |
| 마지막으로 업데이트한 날짜 | 서버가 마지막으로 업데이트된 날짜 및 시간입니다. | DateTime | 4/9/2022, 12:15:42 오후 |
| 상태 | 클러스터의 서버 리소스 상태입니다. | 정상, 경고, 위험 및 기타일 수 있습니다. | 정상 |
| CPU 사용량 | 프로세스에서 CPU를 사용한 비율입니다. | Percent | 56% |
| 메모리 사용량 | 서버 프로세스의 메모리 사용량은 Counter Process\Private Bytes와 메모리 매핑된 데이터의 크기와 같습니다. | Percent | 16% |
| 논리 프로세서 | 논리 프로세서의 수입니다. | Count | 2 |
| CPU | CPU 수입니다. | Count | 2 |
| 작동 시간 | 컴퓨터, 특히 컴퓨터가 작동 중인 시간입니다. | Timespan | 2.609시간 |
| 사이트 | 서버가 속한 사이트의 이름입니다. | 사이트 이름 | SiteA |
| 도메인 이름 | 서버가 속한 로컬 도메인입니다. | 단위 없음 | Contoso.local |
가상 머신
클러스터에 있는 모든 가상 머신의 상태를 제공합니다. VM은 실행, 중지됨, 실패 또는 기타(알 수 없음, 시작, 스냅샷, 저장, 중지, 일시 중지, 다시 시작, 일시 중지됨, 일시 중단됨) 중 하나일 수 있습니다.
| 메트릭 | 설명 | 단위 | 예시 |
|---|---|---|---|
| 서버 | 서버의 이름입니다. | 단위 없음 | Sample-VM-1 |
| 마지막 업데이트 날짜 | 이렇게 하면 서버가 마지막으로 업데이트된 날짜와 시간이 표시됩니다. | DateTime | 4/9/2022, 12:24:02 오후 |
| 총 VM 수 | 서버 노드의 VM 수입니다. | Count | 0/0 실행 중 |
| 실행 중 | 서버 노드에서 실행 중인 VM의 수입니다. | Count | 2 |
| Stopped | 서버 노드에서 중지된 VM의 수입니다. | Count | 3 |
| 실패함 | 서버 노드에서 실패한 VM의 수입니다. | Count | 2 |
| 기타 | VM이 다음 상태(알 수 없음, 시작, 스냅샷, 저장, 중지, 일시 중지, 다시 시작, 일시 중지됨) 중 하나에 있는 경우 "기타"로 간주됩니다. | Count | 2 |
스토리지
다음 표에서는 클러스터의 볼륨 및 드라이브 상태를 제공합니다.
| 메트릭 | 설명 | 단위 | 예시 |
|---|---|---|---|
| 볼륨 | 볼륨의 이름 | 단위 없음 | ClusterPerformanceHistory |
| 마지막으로 업데이트한 날짜 | 스토리지가 마지막으로 업데이트된 날짜 및 시간입니다. | DateTime | 4/14/2022, 2:58:55 오후 |
| 상태 | 볼륨의 상태입니다. | 정상, 경고, 위험 및 기타. | 정상 |
| 총 용량 | 보고 기간 동안 디바이스의 총 용량(바이트)입니다. | 바이트 | 2.5GB |
| 사용 가능한 용량 | 보고 기간 동안 사용 가능한 용량(바이트) | 바이트 | 20B |
| Iops | 초당 입출력 작업 수입니다. | 초당 | 45/s |
| 처리량 | Application Gateway에서 제공하는 초당 바이트 수입니다. | 초당 바이트 | 5B/s |
| 대기 시간 | I/O 요청을 완료하는 데 걸리는 시간입니다. | 둘째 | 0.0016 s |
| 복원력 | 오류에서 복구할 용량입니다. 데이터 가용성을 최대화합니다. | 단위 없음 | 3방향 미러 |
| 중복 제거 | 디스크에 저장해야 하는 데이터의 실제 바이트 수를 줄이는 프로세스입니다. | 사용 가능 여부 | 예/아니요 |
| 파일 시스템 | 파일 시스템의 형식입니다. | 단위 없음 | ReFS |
Azure Monitor 가격 책정
모니터링 시각화를 사용하도록 설정하면 로그가 다음에서 수집됩니다.
- 상태 관리(Microsoft-windows-health/operational).
- SDDC 관리(Microsoft-Windows-SDDC-Management/Operational; 이벤트 ID: 3000, 3001, 3002, 3003, 3004).
수집된 데이터의 양과 Log Analytics 작업 영역의 데이터 보존 설정에 따라 요금이 청구됩니다.
Azure Monitor에는 종량제 가격이 있으며 월별 청구 계정당 처음 5GB는 무료입니다. 사용 중인 Azure 지역과 같은 여러 요인으로 인해 가격이 달라질 수 있으므로 최신 가격 계산을 보려면 Azure Monitor 가격 계산기를 방문하세요.