Docker를 사용하여 사용자 지정 음성 텍스트 변환 컨테이너
사용자 지정 음성 텍스트 변환 컨테이너는 중간 결과가 포함된 실시간 음성 또는 일괄 처리 오디오 녹음을 기록합니다. 사용자 지정 음성 포털에서 만든 사용자 지정 모델을 사용할 수 있습니다. 이 문서에서는 사용자 지정 음성 텍스트 변환 컨테이너를 다운로드, 설치 및 실행하는 방법을 알아봅니다.
필수 조건, 컨테이너 실행 여부 확인, 동일한 호스트에서 여러 컨테이너 실행, 연결 해제된 컨테이너 실행에 대한 자세한 내용은 Docker를 사용하여 음성 컨테이너 설치 및 실행을 참조하세요.
컨테이너 이미지
지원되는 모든 버전 및 로캘에 대한 사용자 지정 음성 텍스트 변환 컨테이너 이미지는 MCR(Microsoft Container Registry) 신디케이트에서 찾을 수 있습니다. azure-cognitive-services/speechservices/ 리포지토리 내에 있으며 이름은 custom-speech-to-text입니다.

전체 컨테이너 이미지 이름은 mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text입니다. 최신 버전을 얻으려면 특정 버전을 추가하거나 :latest를 추가하세요.
| 버전 | Path |
|---|---|
| 가장 늦은 날짜 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.10.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.10.0-amd64 |
latest를 제외한 모든 태그는 다음과 같은 형식이며 대/소문자를 구분합니다.
<major>.<minor>.<patch>-<platform>-<prerelease>
참고 항목
사용자 지정 음성 텍스트 변환 컨테이너의 locale 및 voice는 컨테이너가 수집한 사용자 지정 모델에 의해 결정됩니다.
편의를 위해 태그는 JSON 형식으로도 제공됩니다. 본문에는 컨테이너 경로와 태그 목록이 포함됩니다. 태그는 버전별로 정렬되지 않지만 이 조각에 표시된 것처럼 "latest"은 항상 목록 끝에 포함됩니다.
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
<--redacted for brevity-->
"4.4.0-amd64",
"4.5.0-amd64",
"4.6.0-amd64",
"4.7.0-amd64",
"4.8.0-amd64",
"4.9.0-amd64",
"4.10.0-amd64",
"latest"
]
}
docker pull로 컨테이너 이미지 가져오기
필수 하드웨어를 포함한 필수 조건이 필요합니다. 각 음성 컨테이너에 대한 권장 리소스 할당도 참조하세요.
docker pull 명령을 사용하여 Microsoft Container Registry에서 컨테이너 이미지를 다운로드합니다.
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
참고 항목
사용자 지정 음성 컨테이너용 locale 및 voice는 컨테이너에서 수집한 사용자 지정 모델에 의해 결정됩니다.
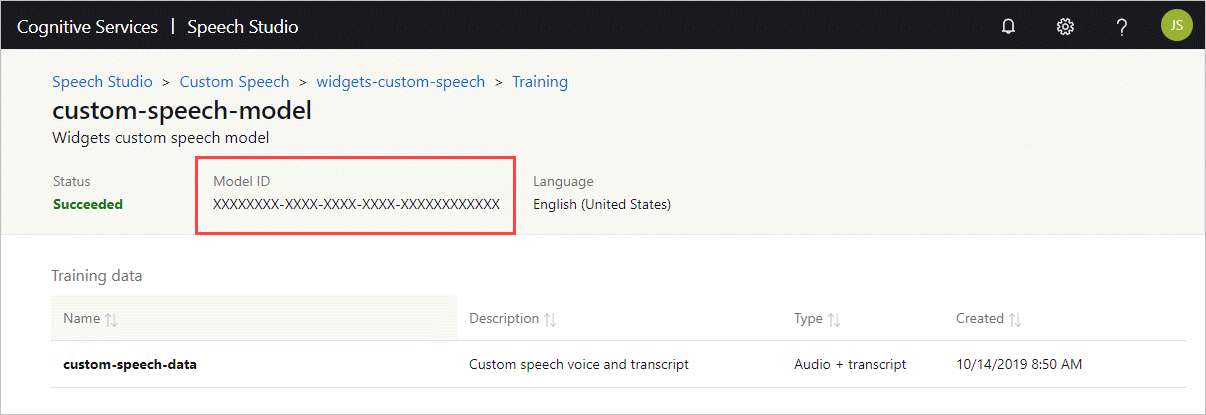
모델 ID 가져오기
컨테이너를 실행하려면 먼저 사용자 지정 모델의 모델 ID나 베이스 모델 ID를 알아야 합니다. 컨테이너를 실행할 때 다운로드하여 사용할 모델 ID 중 하나를 지정합니다.
사용자 지정 모델은 Speech Studio를 사용하여 학습되어야 합니다. 모델 ID를 가져오는 방법에 대한 자세한 내용은 사용자 지정 음성 모델 수명 주기를 참조하세요.
docker run 명령의 ModelId 매개 변수에 대한 인수로 사용할 모델 ID를 가져옵니다.
디스플레이 모델 다운로드
컨테이너를 실행하기 전에 선택적으로 사용할 수 있는 디스플레이 모델 정보를 가져오고 해당 모델을 음성 텍스트 변환 컨테이너에 다운로드하여 매우 개선된 최종 디스플레이 출력을 가져올 수 있습니다. 디스플레이 모델 다운로드는 사용자 지정 음성 텍스트 변환 컨테이너 버전 3.1.0 이상에서 사용할 수 있습니다.
참고 항목
docker run 명령을 사용하더라도 서비스를 위해 컨테이너가 시작되지 않습니다.
다시 채점(Rescore), 문장 부호(Punct), 다시 구분(Resegment) 및 wfstitn(Wfstitn) 표시 모델 형식 중 일부 또는 전부를 쿼리하거나 다운로드할 수 있습니다. 그렇지 않으면 FullDisplay 옵션(다른 형식의 포함 여부와 관계없이)을 사용하여 모든 형식의 표시 모델을 쿼리하거나 다운로드할 수 있습니다.
대상 로캘에서 사용 가능한 최신 표시 모델을 쿼리하도록 BaseModelLocale을 설정합니다. 여러 표시 모델 형식을 포함하는 경우 명령에서 각 형식에 대해 사용 가능한 최신 표시 모델을 반환합니다. 예시:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
대상 로캘에서 사용 가능한 최신 표시 모델을 다운로드하도록 DisplayLocale을 설정합니다. DisplayLocale을 설정하는 경우 FullDisplay 또는 공백으로 구분된 표시 모델의 하위 집합도 지정해야 합니다. 이 명령은 지정된 각 형식에 대해 사용 가능한 최신 표시 모델을 다운로드합니다. 예시:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
다시 채점(RescoreId), 문장 부호(PunctId), 다시 구분(ResegmentId) 및 wfstitn(WfstitnId)과 같은 특정 표시 모델을 다운로드하는 하나의 모델 ID 매개 변수를 설정합니다. 이는 ModelId 매개 변수를 통해 기본 모델을 다운로드하는 방법과 비슷합니다. 예를 들어 다시 채점 표시 모델을 다운로드하려면 RescoreId 매개 변수가 포함된 다음 명령을 사용할 수 있습니다.
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
참고 항목
둘 이상의 쿼리 또는 다운로드 매개 변수를 설정하는 경우 명령은 우선 순위를 BaseModelLocale, 모델 ID, DisplayLocale(표시 모델에만 해당)의 순서로 지정합니다.
docker run을 사용하여 컨테이너 실행
서비스용 컨테이너를 실행하려면 docker run 명령을 사용합니다.
다음 표에는 다양한 docker run 매개 변수와 해당하는 설명이 나와 있습니다.
| 매개 변수 | 설명 |
|---|---|
{VOLUME_MOUNT} |
Docker에서 사용자 지정 모델을 유지하는 데 사용하는 호스트 컴퓨터 볼륨 탑재입니다. 예를 들어, c:\ 드라이브가 호스트 컴퓨터에 있는 c:\CustomSpeech입니다. |
{MODEL_ID} |
Custom Speech 또는 베이스 모델 ID입니다. 자세한 내용은 모델 ID 가져오기를 참조하세요. |
{ENDPOINT_URI} |
이 엔드포인트는 측정 및 청구에 필요합니다. 자세한 내용은 청구 인수를 참조하세요. |
{API_KEY} |
API 키가 필요합니다. 자세한 내용은 청구 인수를 참조하세요. |
사용자 지정 음성 텍스트 변환 컨테이너를 실행할 때 사용자 지정 음성 텍스트 컨테이너 요구 사항 및 권장 사항에 따라 포트, 메모리 및 CPU를 구성합니다.
다음은 자리 표시자 값이 포함된 docker run 명령의 예입니다. VOLUME_MOUNT, MODEL_ID, ENDPOINT_URI 및 API_KEY 값을 지정해야 합니다.
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
이 명령은 다음을 수행합니다.
- 컨테이너 이미지에서 사용자 지정 음성 텍스트 변환 컨테이너를 실행합니다.
- 4개 CPU 코어 및 8GB 메모리를 할당합니다.
- 볼륨 입력 탑재에서 사용자 지정 음성 텍스트 변환 모델을 로드합니다(예: C:\CustomSpeech).
- TCP 포트 5000을 노출하고 컨테이너의 의사-TTY를 할당합니다.
ModelId가 지정된 모델을 다운로드합니다(볼륨 탑재에서 찾을 수 없는 경우).- 사용자 지정 모델이 이전에 다운로드된 경우에는
ModelId가 무시됩니다. - 종료 후 자동으로 컨테이너를 제거합니다. 컨테이너 이미지는 호스트 컴퓨터에서 계속 사용할 수 있습니다.
음성 컨테이너가 있는 docker run에 대한 자세한 내용은 Docker를 사용하여 음성 컨테이너 설치 및 실행을 참조하세요.
컨테이너 사용
음성 컨테이너는 음성 SDK 및 음성 CLI를 통해 액세스되는 websocket 기반 쿼리 엔드포인트 API를 제공합니다. 기본적으로 음성 SDK 및 음성 CLI는 공개 음성 서비스를 사용합니다. 컨테이너를 사용하려면 초기화 메서드를 변경해야 합니다.
Important
컨테이너와 함께 음성 서비스를 사용하는 경우 호스트 인증을 사용해야 합니다. 키와 지역을 구성하면 요청이 공개 음성 서비스로 이동됩니다. 음성 서비스의 결과가 예상과 다를 수 있습니다. 연결이 끊긴 컨테이너의 요청은 실패합니다.
이 Azure 클라우드 초기화 구성을 사용하는 대신 다음을 수행하세요.
var config = SpeechConfig.FromSubscription(...);
컨테이너 호스트와 함께 이 구성을 사용하세요.
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
이 Azure 클라우드 초기화 구성을 사용하는 대신 다음을 수행하세요.
auto speechConfig = SpeechConfig::FromSubscription(...);
컨테이너 호스트와 함께 이 구성을 사용하세요.
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
이 Azure 클라우드 초기화 구성을 사용하는 대신 다음을 수행하세요.
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
컨테이너 호스트와 함께 이 구성을 사용하세요.
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
이 Azure 클라우드 초기화 구성을 사용하는 대신 다음을 수행하세요.
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
컨테이너 호스트와 함께 이 구성을 사용하세요.
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
이 Azure 클라우드 초기화 구성을 사용하는 대신 다음을 수행하세요.
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
컨테이너 호스트와 함께 이 구성을 사용하세요.
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
이 Azure 클라우드 초기화 구성을 사용하는 대신 다음을 수행하세요.
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
컨테이너 호스트와 함께 이 구성을 사용하세요.
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
이 Azure 클라우드 초기화 구성을 사용하는 대신 다음을 수행하세요.
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
컨테이너 호스트와 함께 이 구성을 사용하세요.
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
이 Azure 클라우드 초기화 구성을 사용하는 대신 다음을 수행하세요.
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
컨테이너 엔드포인트와 함께 이 구성을 사용하세요.
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
컨테이너에서 음성 CLI를 사용하는 경우 --host ws://localhost:5000/ 옵션을 포함하세요. CLI가 인증을 위해 음성 키를 사용하지 않도록 하려면 --key none도 지정해야 합니다. 음성 CLI를 구성하는 방법에 대한 자세한 내용은 Azure AI 음성 CLI 시작하기를 참조하세요.
키와 지역 대신 호스트 인증을 사용하여 음성 텍스트 변환 빠른 시작을 사용해 보세요.
다음 단계
- 음성 컨테이너 개요를 참조하세요.
- 컨테이너 구성에서 구성 설정 검토
- 더 많은 Azure AI 컨테이너 사용